 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful and Stable Neuron Explanations for Trustworthy Mechanistic Interpretability
Dec 19, 2025Neuron identification is a popular tool in mechanistic interpretability, aiming to uncover the human-interpretable concepts represented by individual neurons in deep networks. While algorithms such as Network Dissection and CLIP-Dissect achieve great empirical success, a rigorous theoretical foundation remains absent, which is crucial to enable trustworthy and reliable explanations. In this work, we observe that neuron identification can be viewed as the inverse process of machine learning, which allows us to derive guarantees for neuron explanations. Based on this insight, we present the first theoretical analysis of two fundamental challenges: (1) Faithfulness: whether the identified concept faithfully represents the neuron's underlying function and (2) Stability: whether the identification results are consistent across probing datasets. We derive generalization bounds for widely used similarity metrics (e.g. accuracy, AUROC, IoU) to guarantee faithfulness, and propose a bootstrap ensemble procedure that quantifies stability along with BE (Bootstrap Explanation) method to generate concept prediction sets with guaranteed coverage probability. Experiments on both synthetic and real data validate our theoretical results and demonstrate the practicality of our method, providing an important step toward trustworthy neuron identification.
ReflCtrl: Controlling LLM Reflection via Representation Engineering
Dec 16, 2025Large language models (LLMs) with Chain-of-Thought (CoT) reasoning have achieved strong performance across diverse tasks, including mathematics, coding, and general reasoning. A distinctive ability of these reasoning models is self-reflection: the ability to review and revise previous reasoning steps. While self-reflection enhances reasoning performance, it also increases inference cost. In this work, we study self-reflection through the lens of representation engineering. We segment the model's reasoning into steps, identify the steps corresponding to reflection, and extract a reflection direction in the latent space that governs this behavior. Using this direction, we propose a stepwise steering method that can control reflection frequency. We call our framework ReflCtrl. Our experiments show that (1) in many cases reflections are redundant, especially in stronger models (in our experiments, we can save up to 33.6 percent of reasoning tokens while preserving performance), and (2) the model's reflection behavior is highly correlated with an internal uncertainty signal, implying self-reflection may be controlled by the model's uncertainty.
Rethinking Randomized Smoothing for Adversarial Robustness
Mar 02, 2020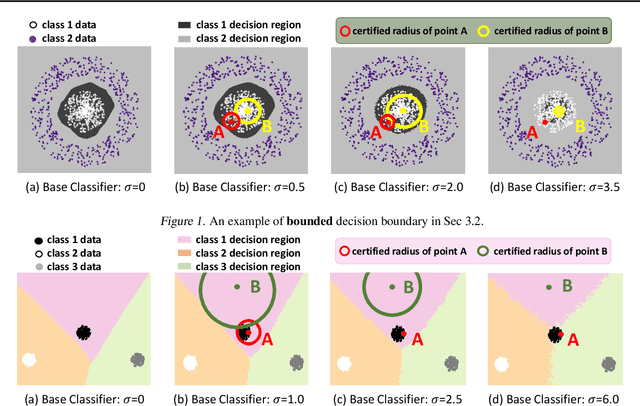

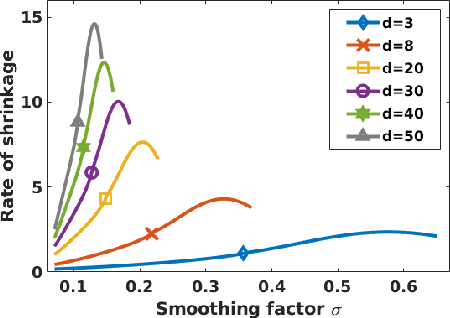

The fragility of modern machine learning models has drawn a considerable amount of attention from both academia and the public. While immense interests were in either crafting adversarial attacks as a way to measure the robustness of neural networks or devising worst-case analytical robustness verification with guarantees, few methods could enjoy both scalability and robustness guarantees at the same time. As an alternative to these attempts, randomized smoothing adopts a different prediction rule that enables statistical robustness arguments and can scale to large networks. However, in this paper, we point out for the first time the side effects of current randomized smoothing workflows. Specifically, we articulate and prove two major points: 1) the decision boundaries shrink with the adoption of randomized smoothing prediction rule; 2) noise augmentation does not necessarily resolve the shrinking issue and can even create additional issues.
Towards Verifying Robustness of Neural Networks Against Semantic Perturbations
Dec 19, 2019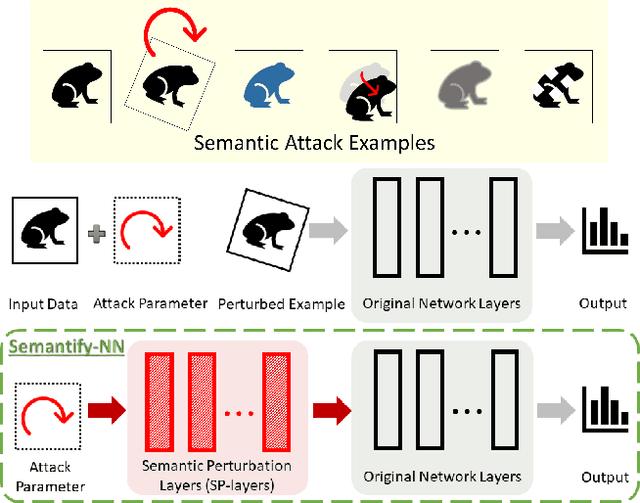
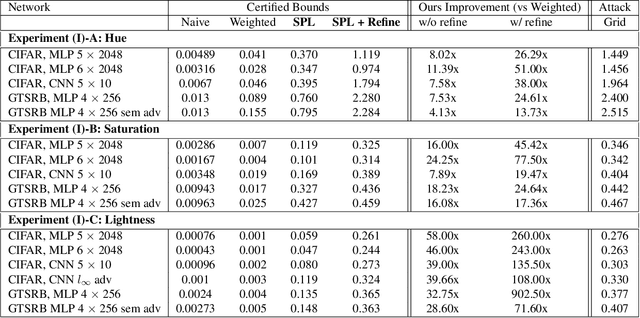
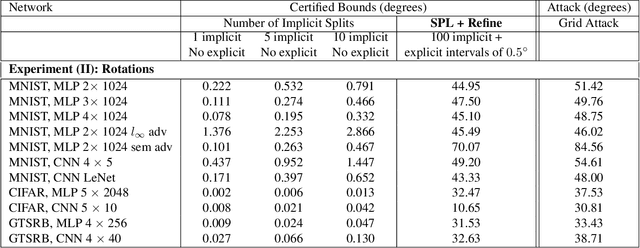
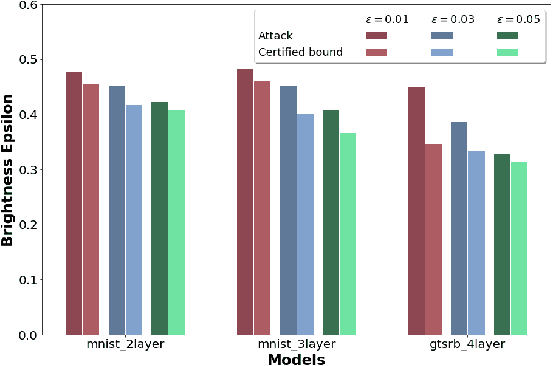
Verifying robustness of neural networks given a specified threat model is a fundamental yet challenging task. While current verification methods mainly focus on the L_p-norm-ball threat model of the input instances, robustness verification against semantic adversarial attacks inducing large L_p-norm perturbations such as color shifting and lighting adjustment are beyond their capacity. To bridge this gap, we propose Semantify-NN, a model-agnostic and generic robustness verification approach against semantic perturbations for neural networks. By simply inserting our proposed semantic perturbation layers (SP-layers) to the input layer of any given model, Semantify-NN is model-agnostic, and any $L_p$-norm-ball based verification tools can be used to verify the model robustness against semantic perturbations. We illustrate the principles of designing the SP-layers and provide examples including semantic perturbations to image classification in the space of hue, saturation, lightness, brightness, contrast and rotation, respectively. Experimental results on various network architectures and different datasets demonstrate the superior verification performance of Semantify-NN over L_p-norm-based verification frameworks that naively convert semantic perturbation to L_p-norm. To the best of our knowledge, Semantify-NN is the first framework to support robustness verification against a wide range of semantic perturbations.