 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-to-Sequence Learning using Gated Graph Neural Networks
Jun 26, 2018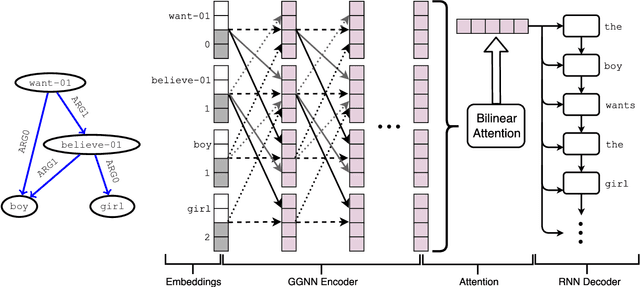
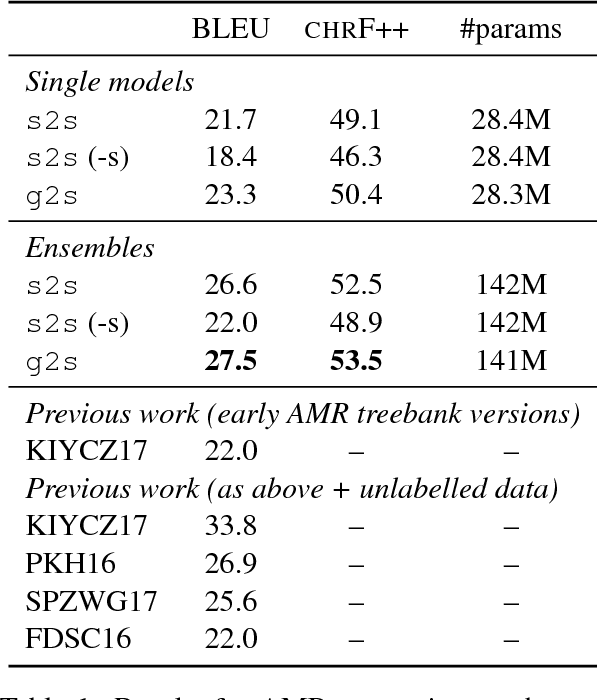
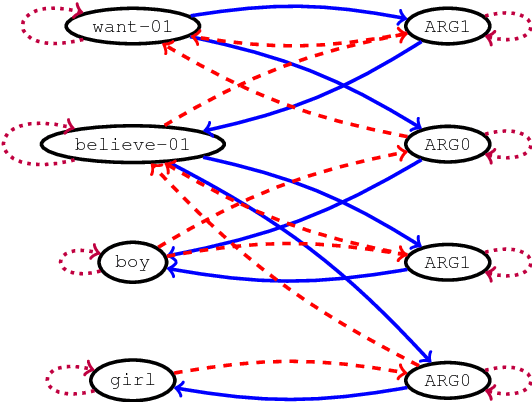
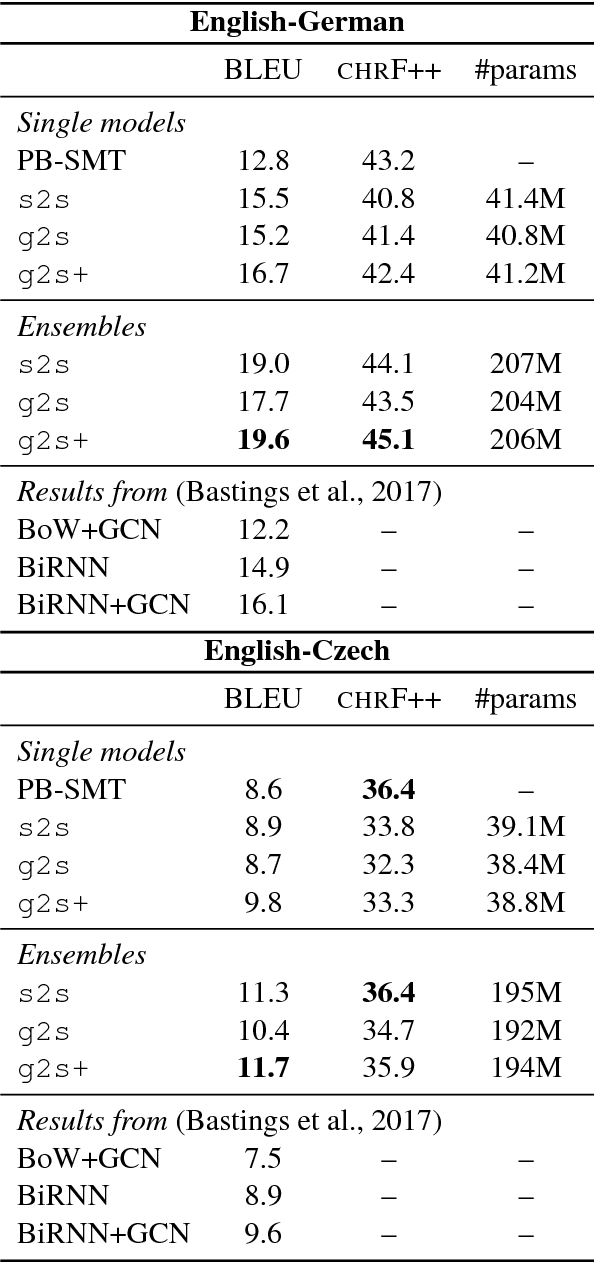
Many NLP applications can be framed as a graph-to-sequence learning problem. Previous work proposing neural architectures on this setting obtained promising results compared to grammar-based approaches but still rely on linearisation heuristics and/or standard recurrent networks to achieve the best performance. In this work, we propose a new model that encodes the full structural information contained in the graph. Our architecture couples the recently proposed Gated Graph Neural Networks with an input transformation that allows nodes and edges to have their own hidden representations, while tackling the parameter explosion problem present in previous work. Experimental results show that our model outperforms strong baselines in generation from AMR graphs and syntax-based neural machine translation.
A Stochastic Decoder for Neural Machine Translation
May 28, 2018
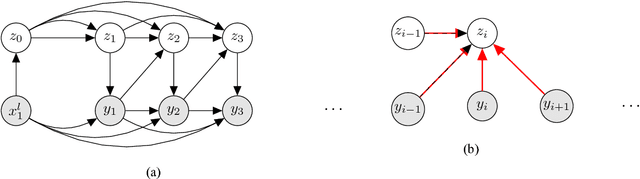
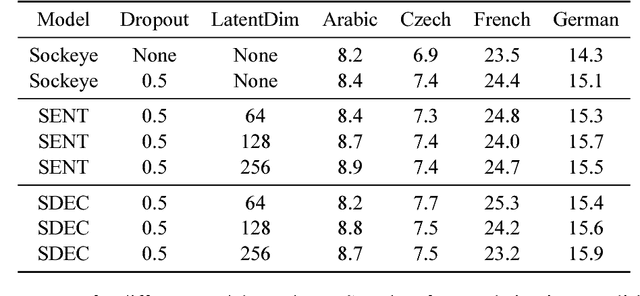
The process of translation is ambiguous, in that there are typically many valid trans- lations for a given sentence. This gives rise to significant variation in parallel cor- pora, however, most current models of machine translation do not account for this variation, instead treating the prob- lem as a deterministic process. To this end, we present a deep generative model of machine translation which incorporates a chain of latent variables, in order to ac- count for local lexical and syntactic varia- tion in parallel corpora. We provide an in- depth analysis of the pitfalls encountered in variational inference for training deep generative models. Experiments on sev- eral different language pairs demonstrate that the model consistently improves over strong baselines.
Content-based Popularity Prediction of Online Petitions Using a Deep Regression Model
May 17, 2018
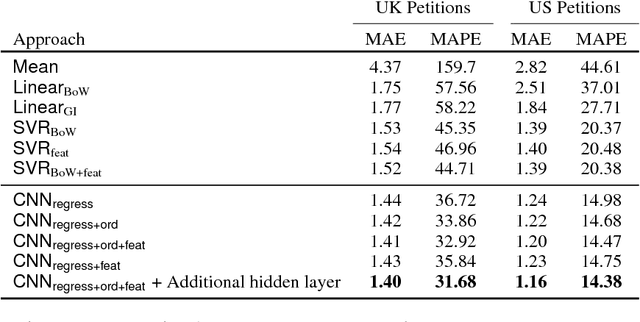
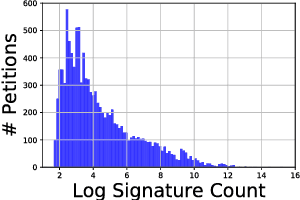
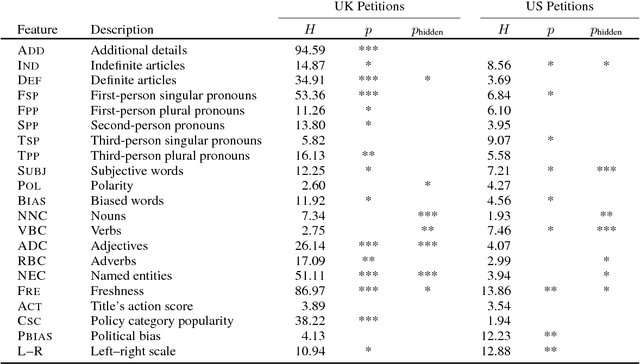
Online petitions are a cost-effective way for citizens to collectively engage with policy-makers in a democracy. Predicting the popularity of a petition --- commonly measured by its signature count --- based on its textual content has utility for policy-makers as well as those posting the petition. In this work, we model this task using CNN regression with an auxiliary ordinal regression objective. We demonstrate the effectiveness of our proposed approach using UK and US government petition datasets.
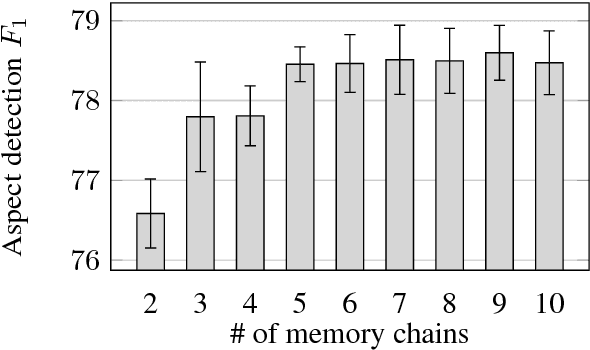
Narrative Modeling with Memory Chains and Semantic Supervision
May 16, 2018
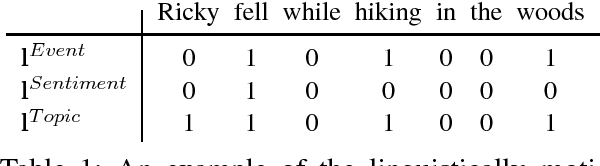
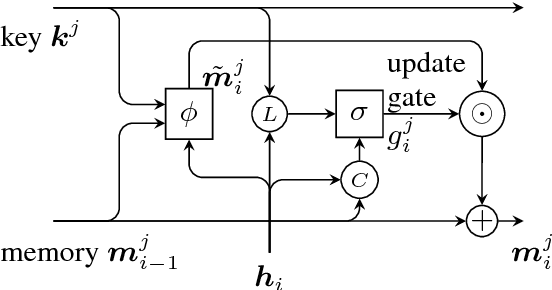
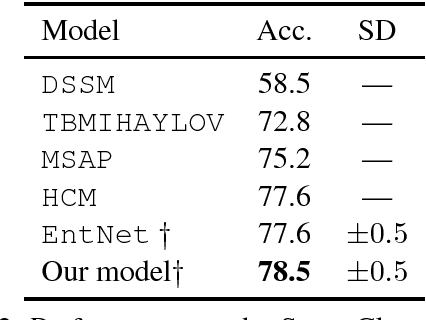
Story comprehension requires a deep semantic understanding of the narrative, making it a challenging task. Inspired by previous studies on ROC Story Cloze Test, we propose a novel method, tracking various semantic aspects with external neural memory chains while encouraging each to focus on a particular semantic aspect. Evaluated on the task of story ending prediction, our model demonstrates superior performance to a collection of competitive baselines, setting a new state of the art.
Towards Robust and Privacy-preserving Text Representations
May 16, 2018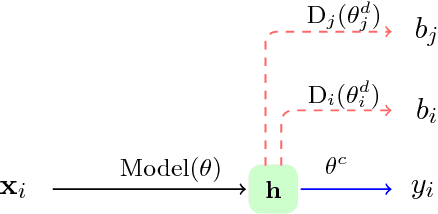


Written text often provides sufficient clues to identify the author, their gender, age, and other important attributes. Consequently, the authorship of training and evaluation corpora can have unforeseen impacts, including differing model performance for different user groups, as well as privacy implications. In this paper, we propose an approach to explicitly obscure important author characteristics at training time, such that representations learned are invariant to these attributes. Evaluating on two tasks, we show that this leads to increased privacy in the learned representations, as well as more robust models to varying evaluation conditions, including out-of-domain corpora.
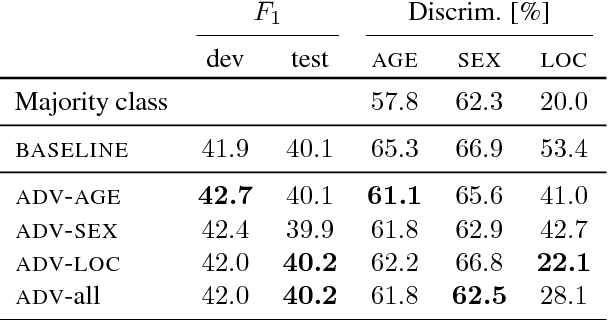
What's in a Domain? Learning Domain-Robust Text Representations using Adversarial Training
May 16, 2018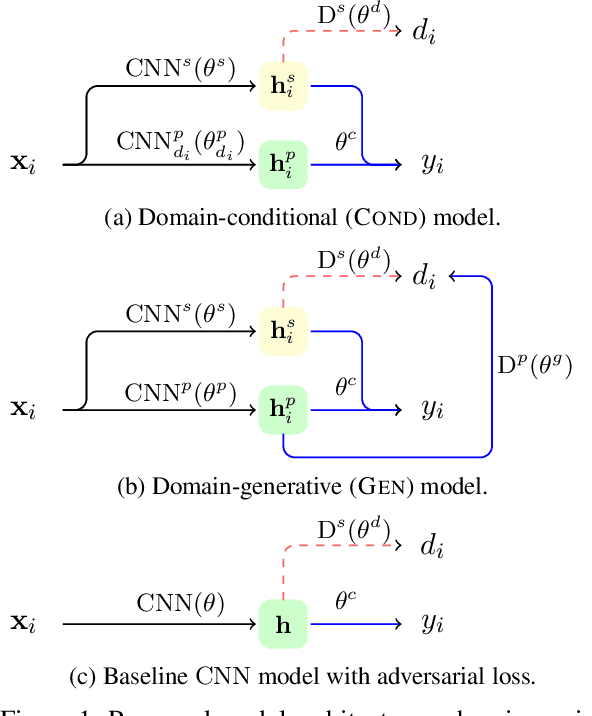
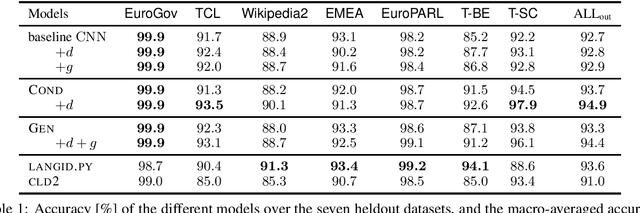
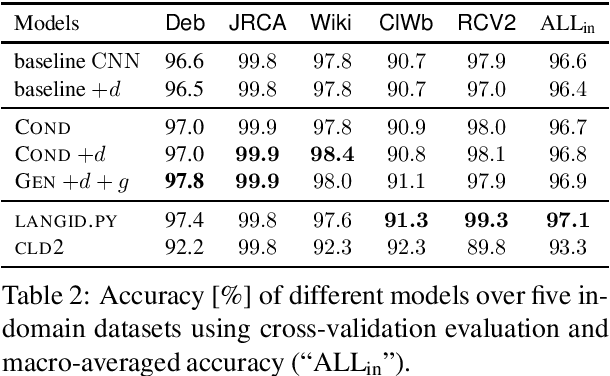
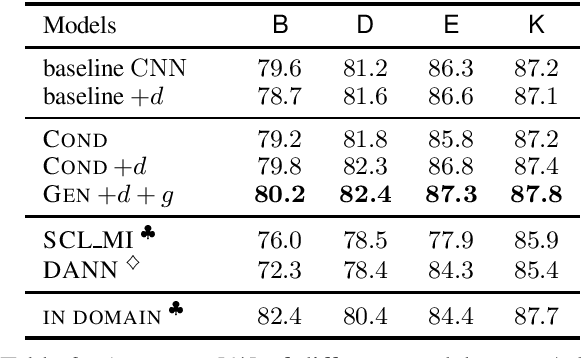
Most real world language problems require learning from heterogenous corpora, raising the problem of learning robust models which generalise well to both similar (in domain) and dissimilar (out of domain) instances to those seen in training. This requires learning an underlying task, while not learning irrelevant signals and biases specific to individual domains. We propose a novel method to optimise both in- and out-of-domain accuracy based on joint learning of a structured neural model with domain-specific and domain-general components, coupled with adversarial training for domain. Evaluating on multi-domain language identification and multi-domain sentiment analysis, we show substantial improvements over standard domain adaptation techniques, and domain-adversarial training.
Semi-supervised User Geolocation via Graph Convolutional Networks
May 15, 2018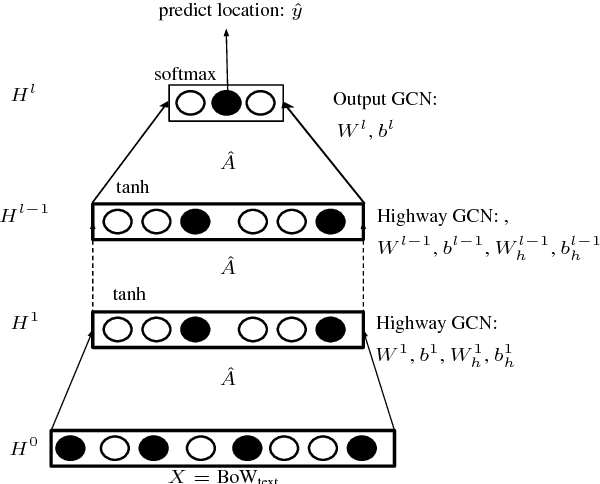
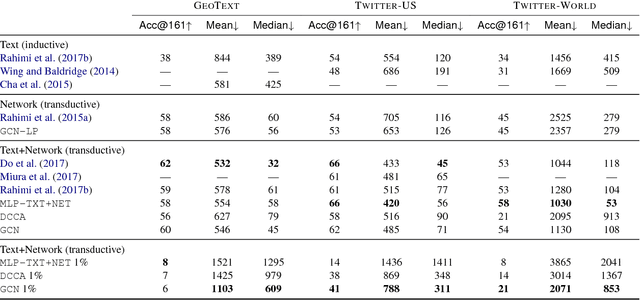
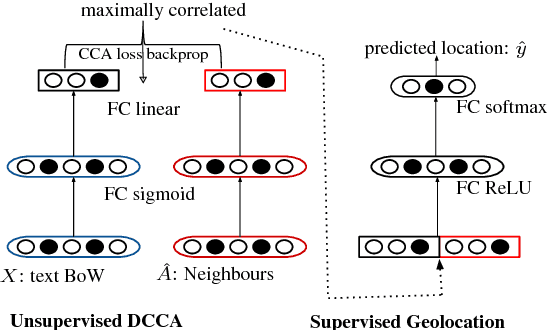

Social media user geolocation is vital to many applications such as event detection. In this paper, we propose GCN, a multiview geolocation model based on Graph Convolutional Networks, that uses both text and network context. We compare GCN to the state-of-the-art, and to two baselines we propose, and show that our model achieves or is competitive with the state- of-the-art over three benchmark geolocation datasets when sufficient supervision is available. We also evaluate GCN under a minimal supervision scenario, and show it outperforms baselines. We find that highway network gates are essential for controlling the amount of useful neighbourhood expansion in GCN.
Hierarchical Structured Model for Fine-to-coarse Manifesto Text Analysis
May 08, 2018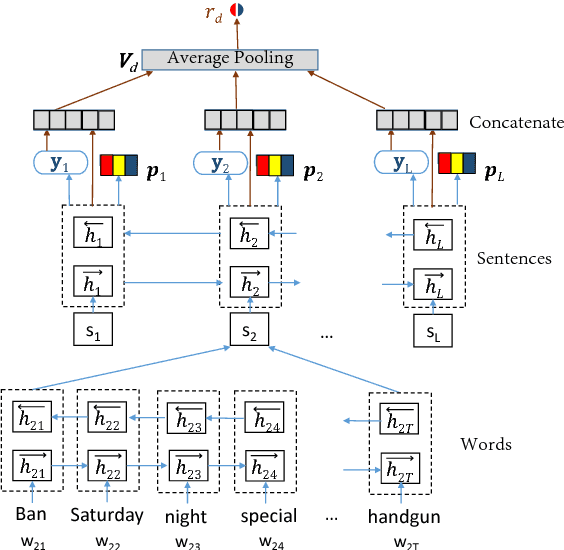
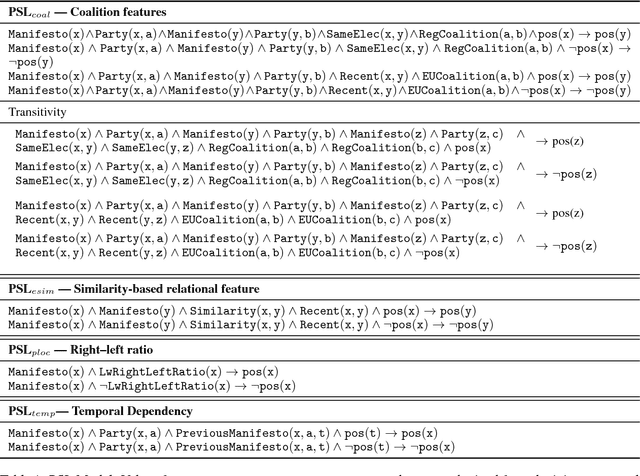
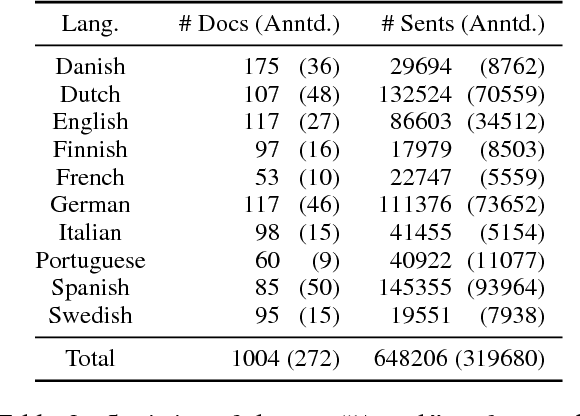
Election manifestos document the intentions, motives, and views of political parties. They are often used for analysing a party's fine-grained position on a particular issue, as well as for coarse-grained positioning of a party on the left--right spectrum. In this paper we propose a two-stage model for automatically performing both levels of analysis over manifestos. In the first step we employ a hierarchical multi-task structured deep model to predict fine- and coarse-grained positions, and in the second step we perform post-hoc calibration of coarse-grained positions using probabilistic soft logic. We empirically show that the proposed model outperforms state-of-art approaches at both granularities using manifestos from twelve countries, written in ten different languages.
Recurrent Entity Networks with Delayed Memory Update for Targeted Aspect-based Sentiment Analysis
Apr 30, 2018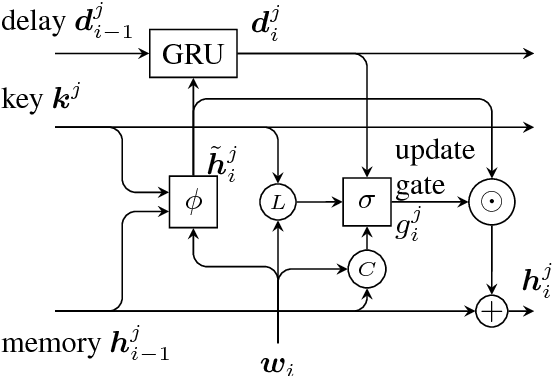
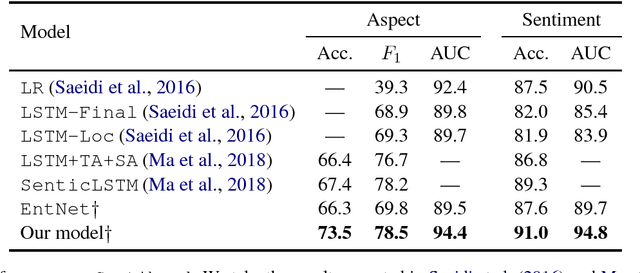
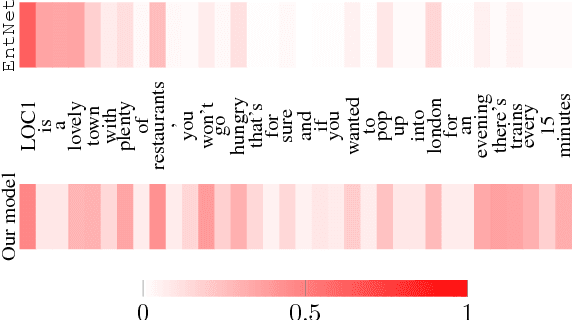
While neural networks have been shown to achieve impressive results for sentence-level sentiment analysis, targeted aspect-based sentiment analysis (TABSA) --- extraction of fine-grained opinion polarity w.r.t. a pre-defined set of aspects --- remains a difficult task. Motivated by recent advances in memory-augmented models for machine reading, we propose a novel architecture, utilising external "memory chains" with a delayed memory update mechanism to track entities. On a TABSA task, the proposed model demonstrates substantial improvements over state-of-the-art approaches, including those using external knowledge bases.
Discourse-Aware Rumour Stance Classification in Social Media Using Sequential Classifiers
Dec 06, 2017
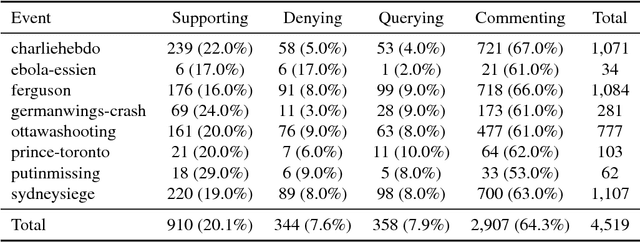
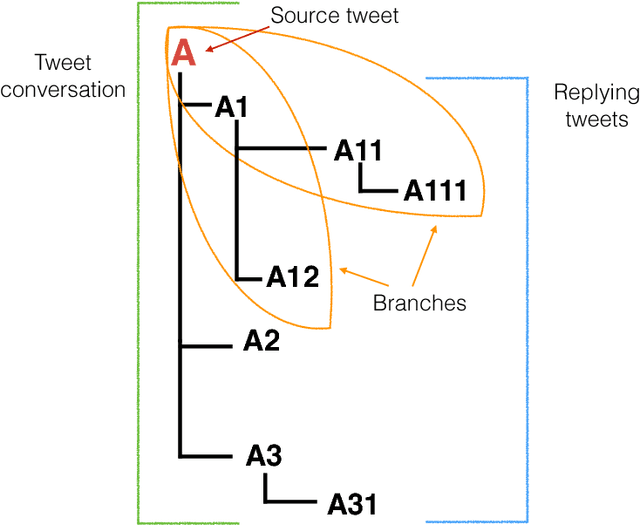
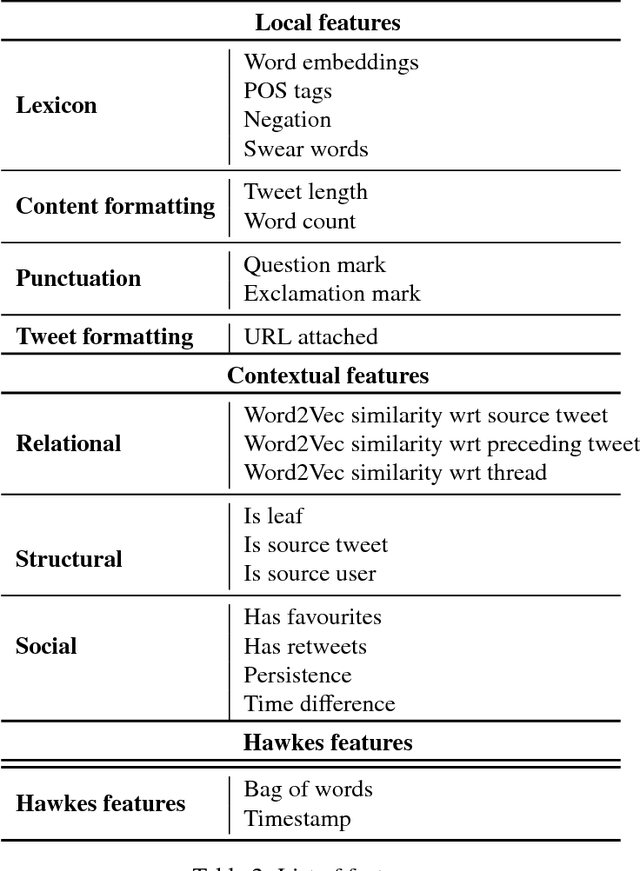
Rumour stance classification, defined as classifying the stance of specific social media posts into one of supporting, denying, querying or commenting on an earlier post, is becoming of increasing interest to researchers. While most previous work has focused on using individual tweets as classifier inputs, here we report on the performance of sequential classifiers that exploit the discourse features inherent in social media interactions or 'conversational threads'. Testing the effectiveness of four sequential classifiers -- Hawkes Processes, Linear-Chain Conditional Random Fields (Linear CRF), Tree-Structured Conditional Random Fields (Tree CRF) and Long Short Term Memory networks (LSTM) -- on eight datasets associated with breaking news stories, and looking at different types of local and contextual features, our work sheds new light on the development of accurate stance classifiers. We show that sequential classifiers that exploit the use of discourse properties in social media conversations while using only local features, outperform non-sequential classifiers. Furthermore, we show that LSTM using a reduced set of features can outperform the other sequential classifiers; this performance is consistent across datasets and across types of stances. To conclude, our work also analyses the different features under study, identifying those that best help characterise and distinguish between stances, such as supporting tweets being more likely to be accompanied by evidence than denying tweets. We also set forth a number of directions for future research.