 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Constituent Syntax for Coreference Resolution
Feb 22, 2022
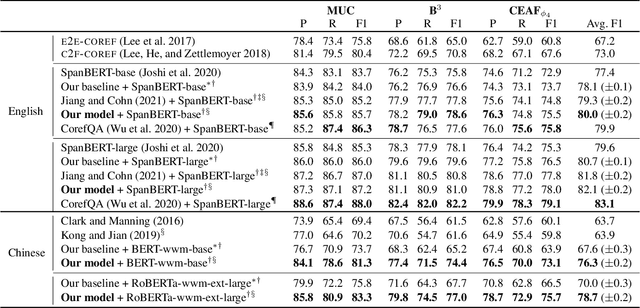
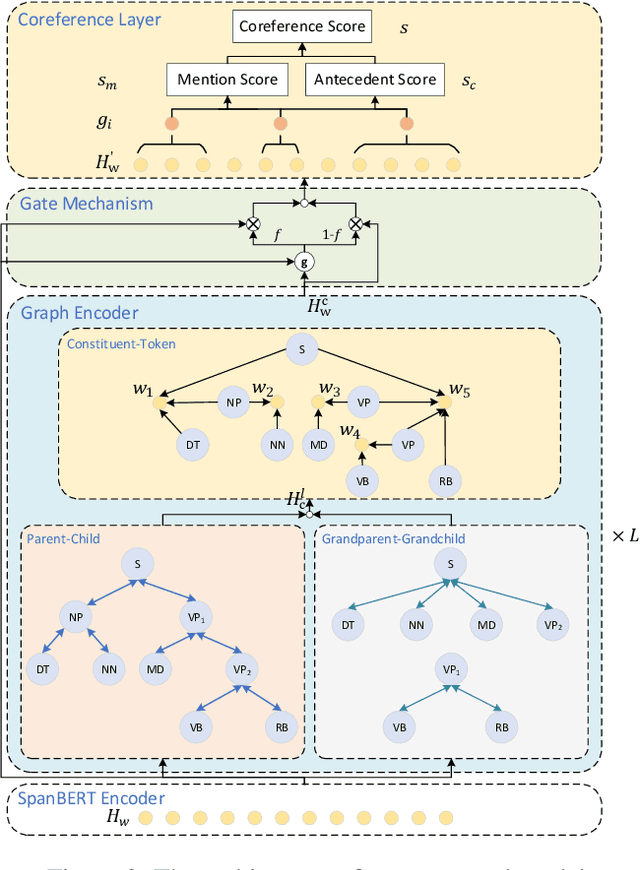
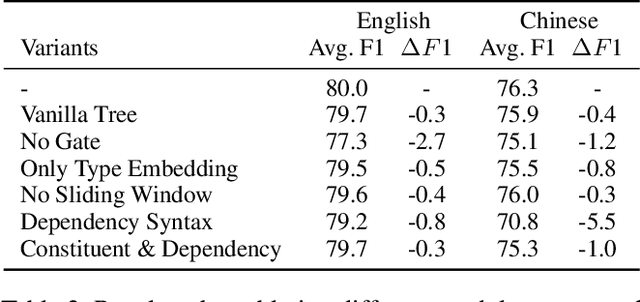
Syntax has been shown to benefit Coreference Resolution from incorporating long-range dependencies and structured information captured by syntax trees, either in traditional statistical machine learning based systems or recently proposed neural models. However, most leading systems use only dependency trees. We argue that constituent trees also encode important information, such as explicit span-boundary signals captured by nested multi-word phrases, extra linguistic labels and hierarchical structures useful for detecting anaphora. In this work, we propose a simple yet effective graph-based method to incorporate constituent syntactic structures. Moreover, we also explore to utilise higher-order neighbourhood information to encode rich structures in constituent trees. A novel message propagation mechanism is therefore proposed to enable information flow among elements in syntax trees. Experiments on the English and Chinese portions of OntoNotes 5.0 benchmark show that our proposed model either beats a strong baseline or achieves new state-of-the-art performance. (Code is available at https://github.com/Fantabulous-J/Coref-Constituent-Graph)
ITTC @ TREC 2021 Clinical Trials Track
Feb 16, 2022
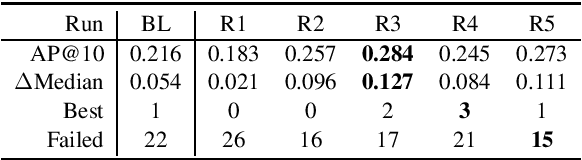
This paper describes the submissions of the Natural Language Processing (NLP) team from the Australian Research Council Industrial Transformation Training Centre (ITTC) for Cognitive Computing in Medical Technologies to the TREC 2021 Clinical Trials Track. The task focuses on the problem of matching eligible clinical trials to topics constituting a summary of a patient's admission notes. We explore different ways of representing trials and topics using NLP techniques, and then use a common retrieval model to generate the ranked list of relevant trials for each topic. The results from all our submitted runs are well above the median scores for all topics, but there is still plenty of scope for improvement.
Exploring Story Generation with Multi-task Objectives in Variational Autoencoders
Nov 15, 2021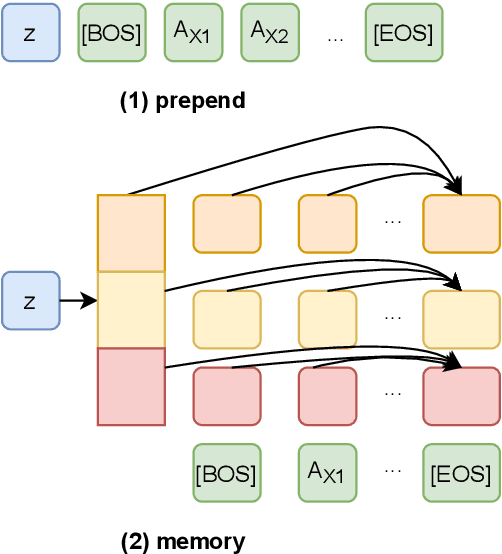

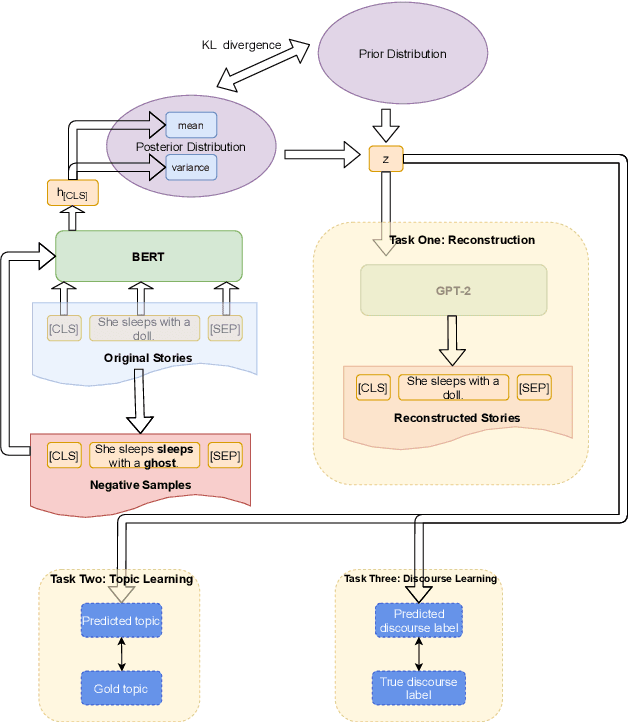
GPT-2 has been frequently adapted in story generation models as it provides powerful generative capability. However, it still fails to generate consistent stories and lacks diversity. Current story generation models leverage additional information such as plots or commonsense into GPT-2 to guide the generation process. These approaches focus on improving generation quality of stories while our work look at both quality and diversity. We explore combining BERT and GPT-2 to build a variational autoencoder (VAE), and extend it by adding additional objectives to learn global features such as story topic and discourse relations. Our evaluations show our enhanced VAE can provide better quality and diversity trade off, generate less repetitive story content and learn a more informative latent variable.
It is Not as Good as You Think! Evaluating Simultaneous Machine Translation on Interpretation Data
Oct 11, 2021
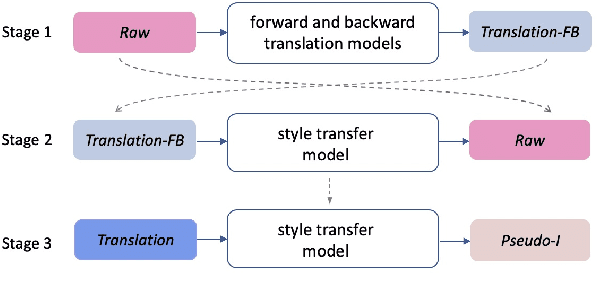
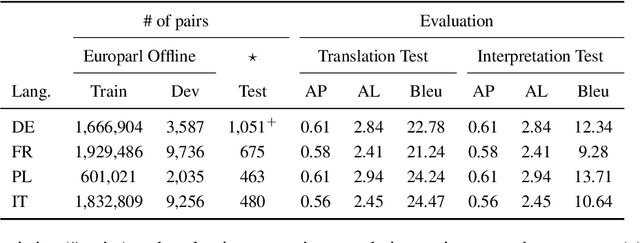
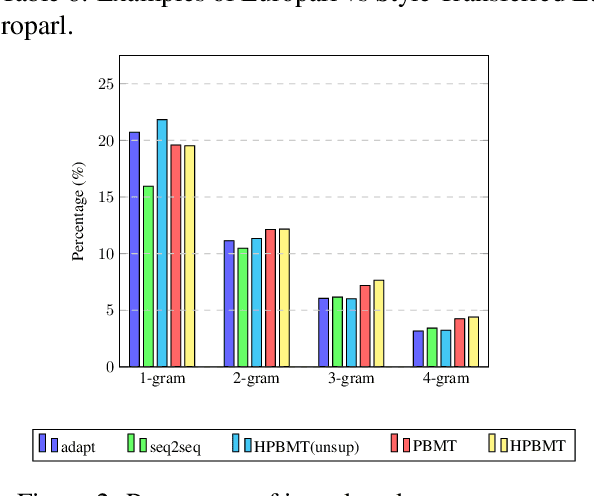
Most existing simultaneous machine translation (SiMT) systems are trained and evaluated on offline translation corpora. We argue that SiMT systems should be trained and tested on real interpretation data. To illustrate this argument, we propose an interpretation test set and conduct a realistic evaluation of SiMT trained on offline translations. Our results, on our test set along with 3 existing smaller scale language pairs, highlight the difference of up-to 13.83 BLEU score when SiMT models are evaluated on translation vs interpretation data. In the absence of interpretation training data, we propose a translation-to-interpretation (T2I) style transfer method which allows converting existing offline translations into interpretation-style data, leading to up-to 2.8 BLEU improvement. However, the evaluation gap remains notable, calling for constructing large-scale interpretation corpora better suited for evaluating and developing SiMT systems.
Unsupervised Cross-Lingual Transfer of Structured Predictors without Source Data
Oct 08, 2021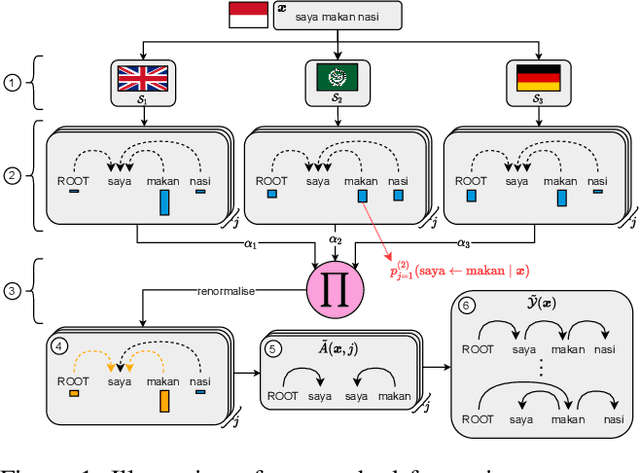
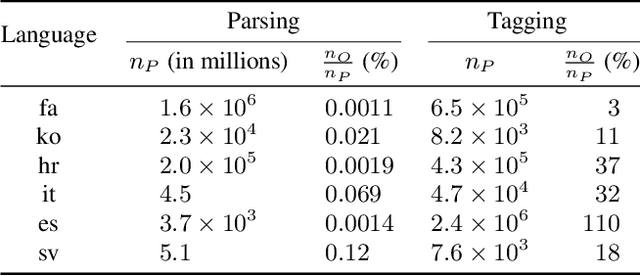
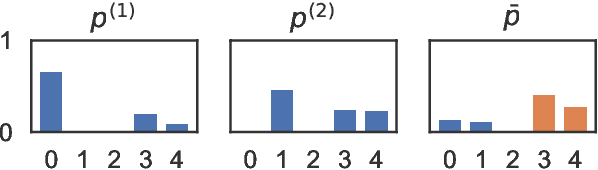
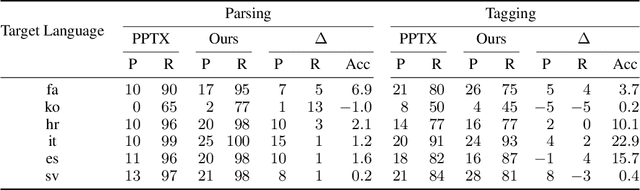
Providing technologies to communities or domains where training data is scarce or protected e.g., for privacy reasons, is becoming increasingly important. To that end, we generalise methods for unsupervised transfer from multiple input models for structured prediction. We show that the means of aggregating over the input models is critical, and that multiplying marginal probabilities of substructures to obtain high-probability structures for distant supervision is substantially better than taking the union of such structures over the input models, as done in prior work. Testing on 18 languages, we demonstrate that the method works in a cross-lingual setting, considering both dependency parsing and part-of-speech structured prediction problems. Our analyses show that the proposed method produces less noisy labels for the distant supervision.
Contrastive Learning for Fair Representations
Sep 22, 2021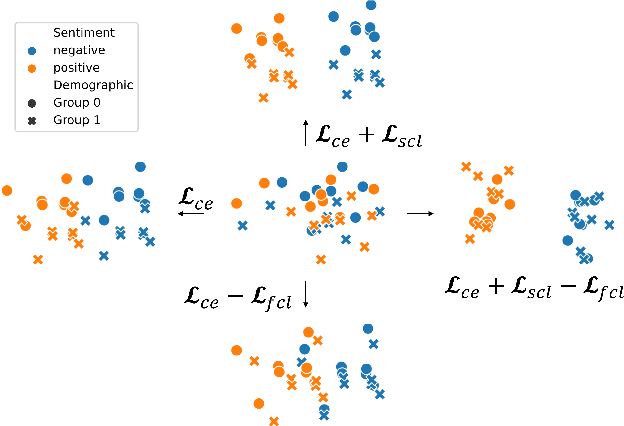
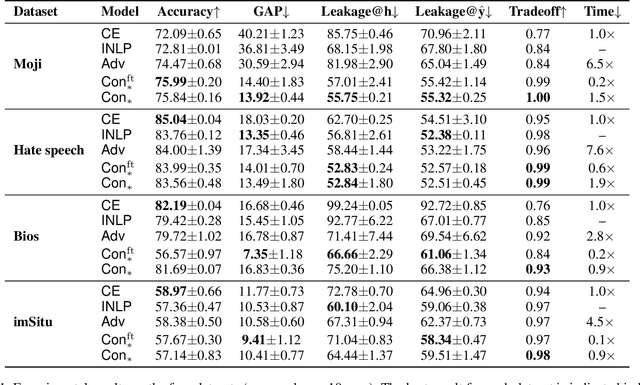
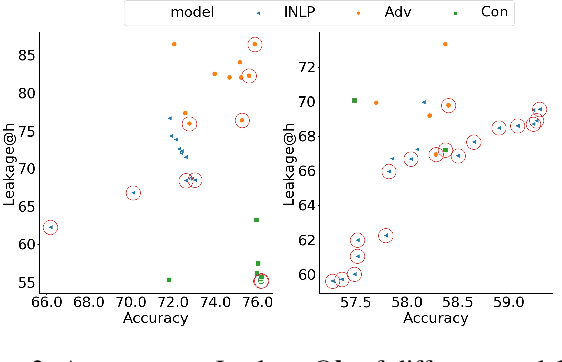
Trained classification models can unintentionally lead to biased representations and predictions, which can reinforce societal preconceptions and stereotypes. Existing debiasing methods for classification models, such as adversarial training, are often expensive to train and difficult to optimise. In this paper, we propose a method for mitigating bias in classifier training by incorporating contrastive learning, in which instances sharing the same class label are encouraged to have similar representations, while instances sharing a protected attribute are forced further apart. In such a way our method learns representations which capture the task label in focused regions, while ensuring the protected attribute has diverse spread, and thus has limited impact on prediction and thereby results in fairer models. Extensive experimental results across four tasks in NLP and computer vision show (a) that our proposed method can achieve fairer representations and realises bias reductions compared with competitive baselines; and (b) that it can do so without sacrificing main task performance; (c) that it sets a new state-of-the-art performance in one task despite reducing the bias. Finally, our method is conceptually simple and agnostic to network architectures, and incurs minimal additional compute cost.
Fairness-aware Class Imbalanced Learning
Sep 21, 2021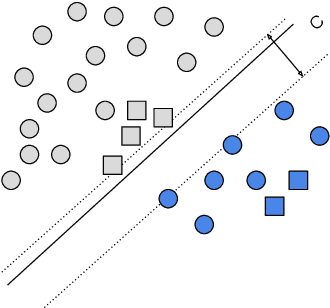

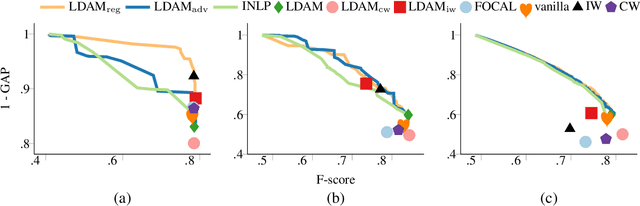

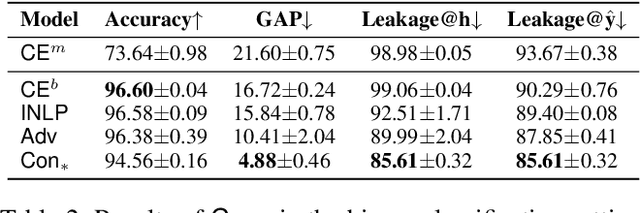
Class imbalance is a common challenge in many NLP tasks, and has clear connections to bias, in that bias in training data often leads to higher accuracy for majority groups at the expense of minority groups. However there has traditionally been a disconnect between research on class-imbalanced learning and mitigating bias, and only recently have the two been looked at through a common lens. In this work we evaluate long-tail learning methods for tweet sentiment and occupation classification, and extend a margin-loss based approach with methods to enforce fairness. We empirically show through controlled experiments that the proposed approaches help mitigate both class imbalance and demographic biases.
Evaluating Debiasing Techniques for Intersectional Biases
Sep 21, 2021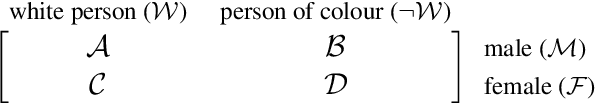
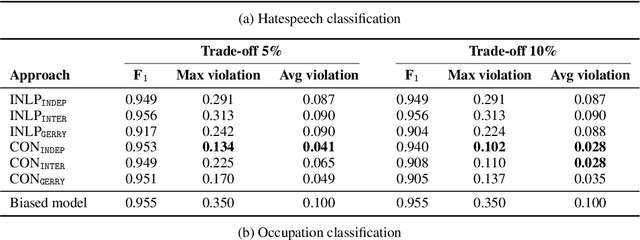
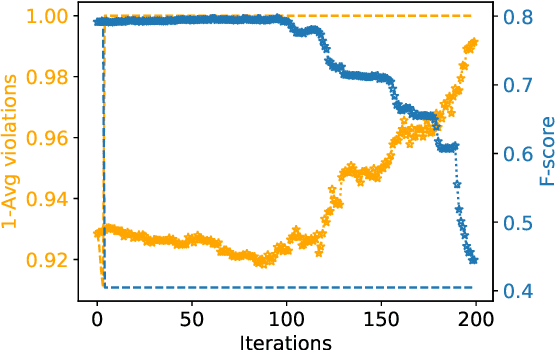
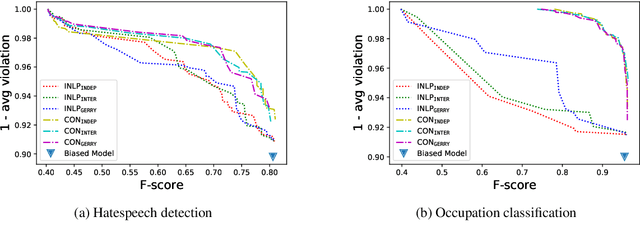
Bias is pervasive in NLP models, motivating the development of automatic debiasing techniques. Evaluation of NLP debiasing methods has largely been limited to binary attributes in isolation, e.g., debiasing with respect to binary gender or race, however many corpora involve multiple such attributes, possibly with higher cardinality. In this paper we argue that a truly fair model must consider `gerrymandering' groups which comprise not only single attributes, but also intersectional groups. We evaluate a form of bias-constrained model which is new to NLP, as well an extension of the iterative nullspace projection technique which can handle multiple protected attributes.
Commonsense Knowledge in Word Associations and ConceptNet
Sep 20, 2021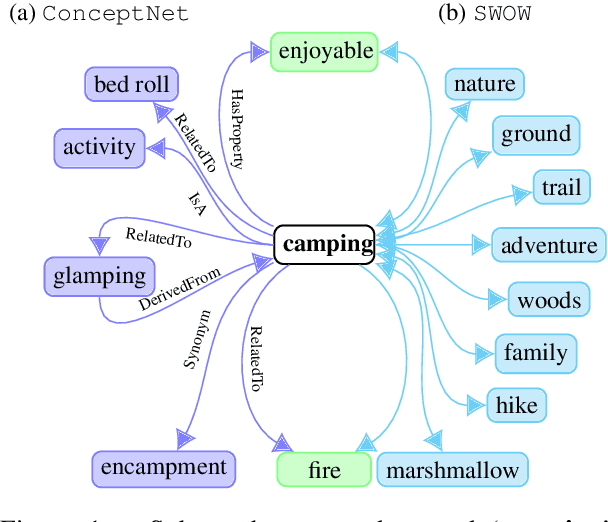

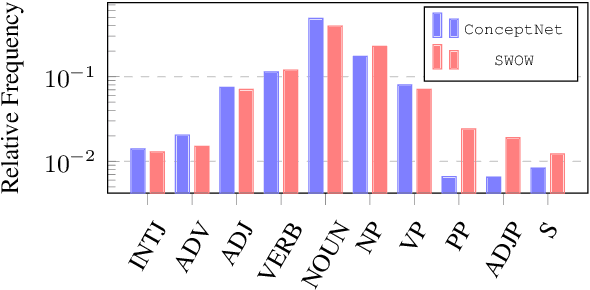

Humans use countless basic, shared facts about the world to efficiently navigate in their environment. This commonsense knowledge is rarely communicated explicitly, however, understanding how commonsense knowledge is represented in different paradigms is important for both deeper understanding of human cognition and for augmenting automatic reasoning systems. This paper presents an in-depth comparison of two large-scale resources of general knowledge: ConcpetNet, an engineered relational database, and SWOW a knowledge graph derived from crowd-sourced word associations. We examine the structure, overlap and differences between the two graphs, as well as the extent to which they encode situational commonsense knowledge. We finally show empirically that both resources improve downstream task performance on commonsense reasoning benchmarks over text-only baselines, suggesting that large-scale word association data, which have been obtained for several languages through crowd-sourcing, can be a valuable complement to curated knowledge graphs
Balancing out Bias: Achieving Fairness Through Training Reweighting
Sep 16, 2021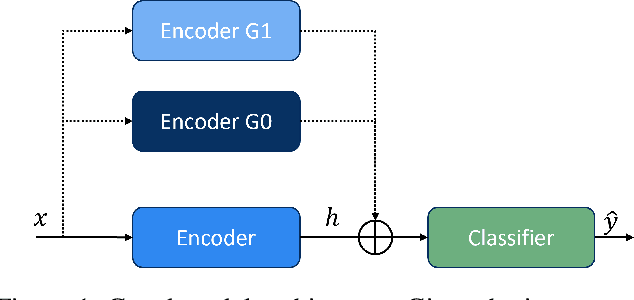
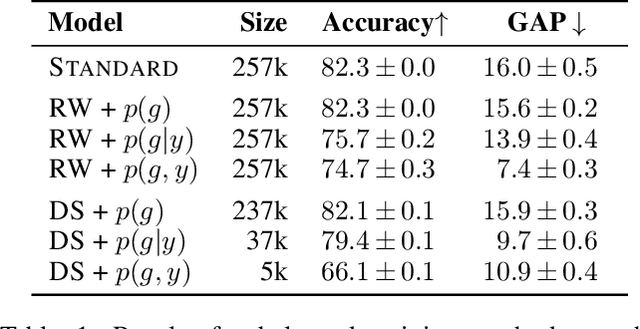
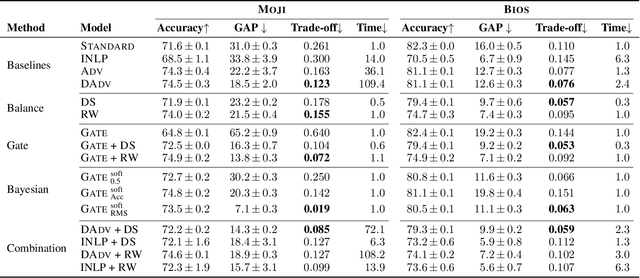
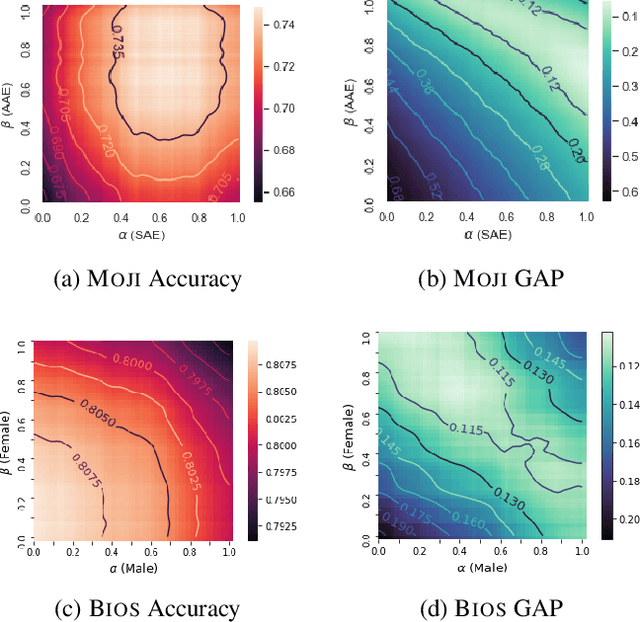
Bias in natural language processing arises primarily from models learning characteristics of the author such as gender and race when modelling tasks such as sentiment and syntactic parsing. This problem manifests as disparities in error rates across author demographics, typically disadvantaging minority groups. Existing methods for mitigating and measuring bias do not directly account for correlations between author demographics and linguistic variables. Moreover, evaluation of bias has been inconsistent in previous work, in terms of dataset balance and evaluation methods. This paper introduces a very simple but highly effective method for countering bias using instance reweighting, based on the frequency of both task labels and author demographics. We extend the method in the form of a gated model which incorporates the author demographic as an input, and show that while it is highly vulnerable to input data bias, it provides debiased predictions through demographic input perturbation, and outperforms all other bias mitigation techniques when combined with instance reweighting.