 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNNKGC: Improving Knowledge Graph Completion with Node Neighborhoods
Feb 13, 2023



Knowledge graph completion (KGC) aims to discover missing relations of query entities. Current text-based models utilize the entity name and description to infer the tail entity given the head entity and a certain relation. Existing approaches also consider the neighborhood of the head entity. However, these methods tend to model the neighborhood using a flat structure and are only restricted to 1-hop neighbors. In this work, we propose a node neighborhood-enhanced framework for knowledge graph completion. It models the head entity neighborhood from multiple hops using graph neural networks to enrich the head node information. Moreover, we introduce an additional edge link prediction task to improve KGC. Evaluation on two public datasets shows that this framework is simple yet effective. The case study also shows that the model is able to predict explainable predictions.
Can Persistent Homology provide an efficient alternative for Evaluation of Knowledge Graph Completion Methods?
Jan 31, 2023In this paper we present a novel method, $\textit{Knowledge Persistence}$ ($\mathcal{KP}$), for faster evaluation of Knowledge Graph (KG) completion approaches. Current ranking-based evaluation is quadratic in the size of the KG, leading to long evaluation times and consequently a high carbon footprint. $\mathcal{KP}$ addresses this by representing the topology of the KG completion methods through the lens of topological data analysis, concretely using persistent homology. The characteristics of persistent homology allow $\mathcal{KP}$ to evaluate the quality of the KG completion looking only at a fraction of the data. Experimental results on standard datasets show that the proposed metric is highly correlated with ranking metrics (Hits@N, MR, MRR). Performance evaluation shows that $\mathcal{KP}$ is computationally efficient: In some cases, the evaluation time (validation+test) of a KG completion method has been reduced from 18 hours (using Hits@10) to 27 seconds (using $\mathcal{KP}$), and on average (across methods & data) reduces the evaluation time (validation+test) by $\approx$ $\textbf{99.96}\%$.
MegaCRN: Meta-Graph Convolutional Recurrent Network for Spatio-Temporal Modeling
Dec 12, 2022



Spatio-temporal modeling as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the underlying heterogeneity and non-stationarity implied in the graph streams, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a large-scale spatio-temporal dataset that contains a variaty of non-stationary phenomena. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle locations and time slots with different patterns and be robustly adaptive to different anomalous situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Dec 08, 2022



Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
Learnable Spectral Wavelets on Dynamic Graphs to Capture Global Interactions
Nov 22, 2022



Learning on evolving(dynamic) graphs has caught the attention of researchers as static methods exhibit limited performance in this setting. The existing methods for dynamic graphs learn spatial features by local neighborhood aggregation, which essentially only captures the low pass signals and local interactions. In this work, we go beyond current approaches to incorporate global features for effectively learning representations of a dynamically evolving graph. We propose to do so by capturing the spectrum of the dynamic graph. Since static methods to learn the graph spectrum would not consider the history of the evolution of the spectrum as the graph evolves with time, we propose a novel approach to learn the graph wavelets to capture this evolving spectra. Further, we propose a framework that integrates the dynamically captured spectra in the form of these learnable wavelets into spatial features for incorporating local and global interactions. Experiments on eight standard datasets show that our method significantly outperforms related methods on various tasks for dynamic graphs.
KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation
May 23, 2022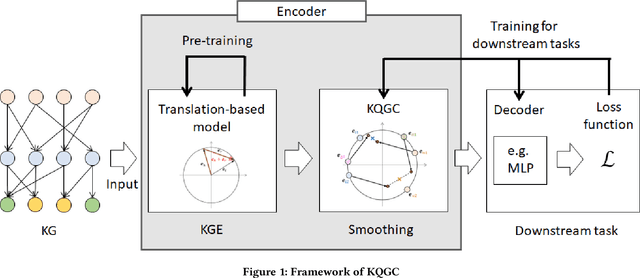
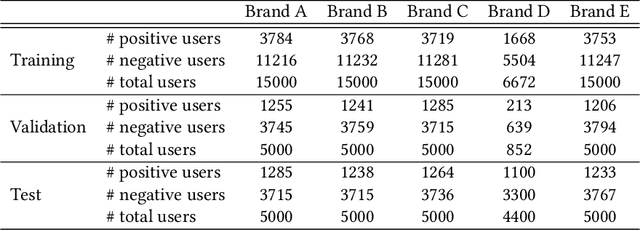
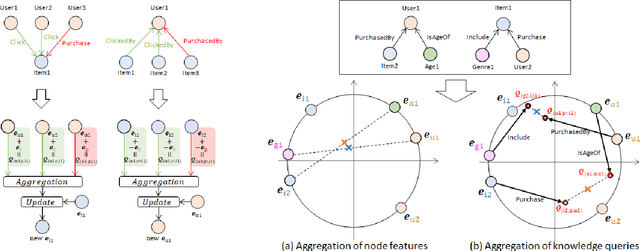
Leveraging graphs on recommender systems has gained popularity with the development of graph representation learning (GRL). In particular, knowledge graph embedding (KGE) and graph neural networks (GNNs) are representative GRL approaches, which have achieved the state-of-the-art performance on several recommendation tasks. Furthermore, combination of KGE and GNNs (KG-GNNs) has been explored and found effective in many academic literatures. One of the main characteristics of GNNs is their ability to retain structural properties among neighbors in the resulting dense representation, which is usually coined as smoothing. The smoothing is specially desired in the presence of homophilic graphs, such as the ones we find on recommender systems. In this paper, we propose a new model for recommender systems named Knowledge Query-based Graph Convolution (KQGC). In contrast to exisiting KG-GNNs, KQGC focuses on the smoothing, and leverages a simple linear graph convolution for smoothing KGE. A pre-trained KGE is fed into KQGC, and it is smoothed by aggregating neighbor knowledge queries, which allow entity-embeddings to be aligned on appropriate vector points for smoothing KGE effectively. We apply the proposed KQGC to a recommendation task that aims prospective users for specific products. Extensive experiments on a real E-commerce dataset demonstrate the effectiveness of KQGC.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022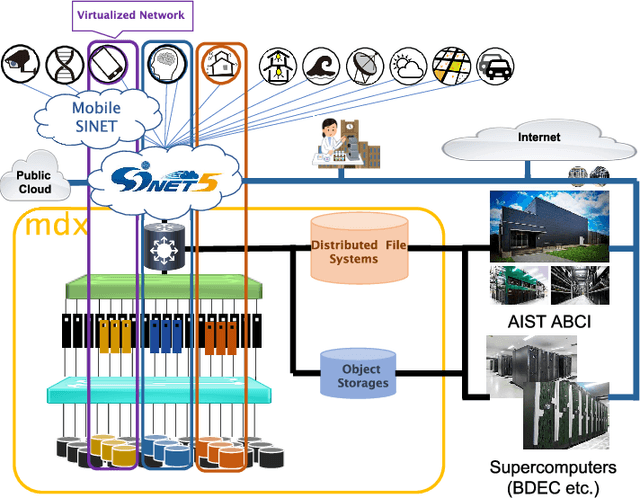
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Ethereum Fraud Detection with Heterogeneous Graph Neural Networks
Mar 23, 2022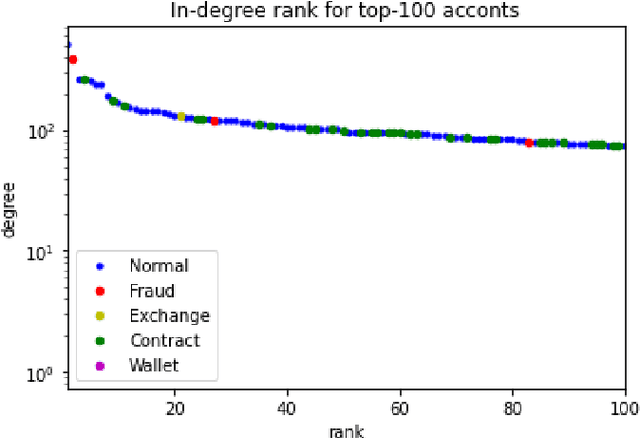
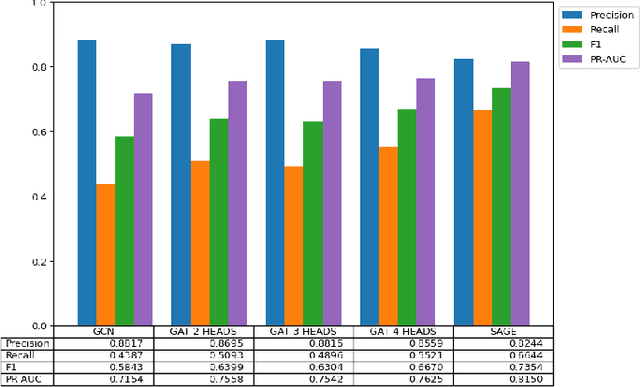
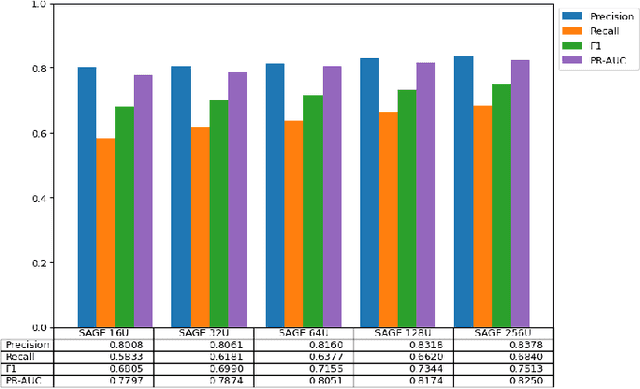
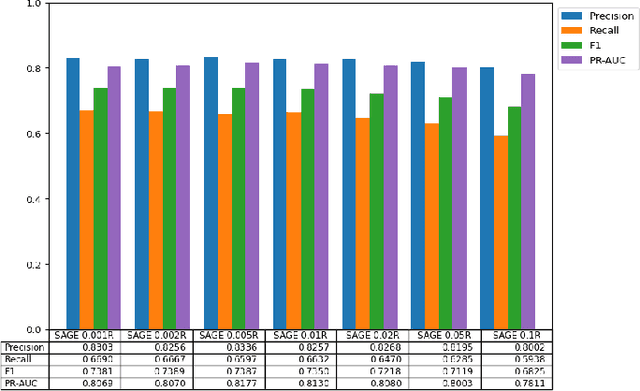
While transactions with cryptocurrencies such as Ethereum are becoming more prevalent, fraud and other criminal transactions are not uncommon. Graph analysis algorithms and machine learning techniques detect suspicious transactions that lead to phishing in large transaction networks. Many graph neural network (GNN) models have been proposed to apply deep learning techniques to graph structures. Although there is research on phishing detection using GNN models in the Ethereum transaction network, models that address the scale of the number of vertices and edges and the imbalance of labels have not yet been studied. In this paper, we compared the model performance of GNN models on the actual Ethereum transaction network dataset and phishing reported label data to exhaustively compare and verify which GNN models and hyperparameters produce the best accuracy. Specifically, we evaluated the model performance of representative homogeneous GNN models which consider single-type nodes and edges and heterogeneous GNN models which support different types of nodes and edges. We showed that heterogeneous models had better model performance than homogeneous models. In particular, the RGCN model achieved the best performance in the overall metrics.
Investigating Expressiveness of Transformer in Spectral Domain for Graphs
Jan 27, 2022
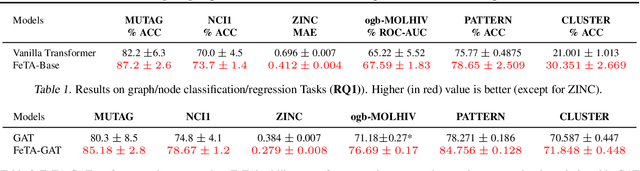
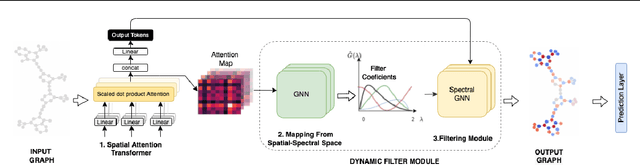
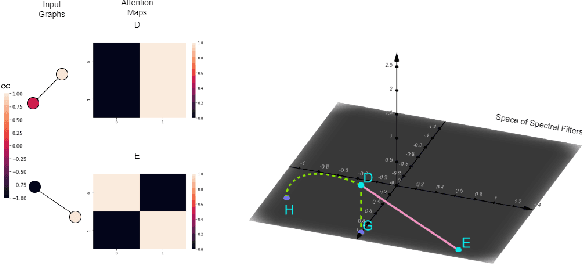
Transformers have been proven to be inadequate for graph representation learning. To understand this inadequacy, there is need to investigate if spectral analysis of transformer will reveal insights on its expressive power. Similar studies already established that spectral analysis of Graph neural networks (GNNs) provides extra perspectives on their expressiveness. In this work, we systematically study and prove the link between the spatial and spectral domain in the realm of the transformer. We further provide a theoretical analysis that the spatial attention mechanism in the transformer cannot effectively capture the desired frequency response, thus, inherently limiting its expressiveness in spectral space. Therefore, we propose FeTA, a framework that aims to perform attention over the entire graph spectrum analogous to the attention in spatial space. Empirical results suggest that FeTA provides homogeneous performance gain against vanilla transformer across all tasks on standard benchmarks and can easily be extended to GNN based models with low-pass characteristics (e.g., GAT). Furthermore, replacing the vanilla transformer model with FeTA in recently proposed position encoding schemes has resulted in comparable or better performance than transformer and GNN baselines.
Efficient Scaling of Dynamic Graph Neural Networks
Sep 16, 2021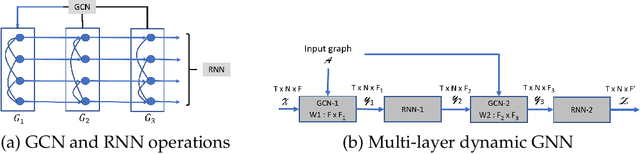
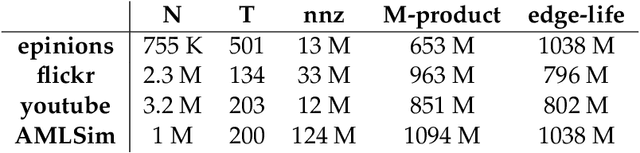
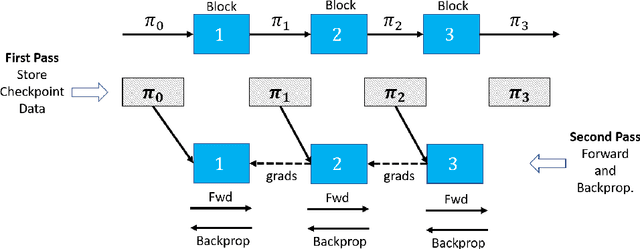
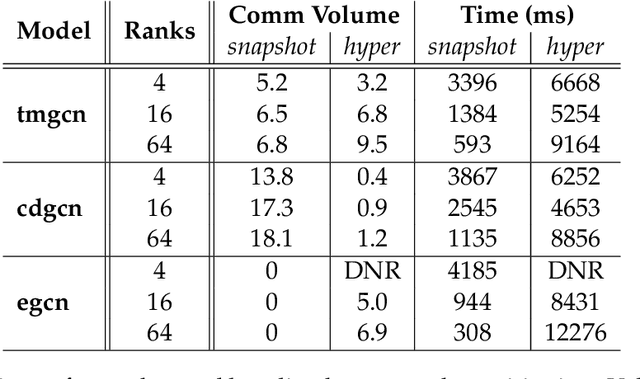
We present distributed algorithms for training dynamic Graph Neural Networks (GNN) on large scale graphs spanning multi-node, multi-GPU systems. To the best of our knowledge, this is the first scaling study on dynamic GNN. We devise mechanisms for reducing the GPU memory usage and identify two execution time bottlenecks: CPU-GPU data transfer; and communication volume. Exploiting properties of dynamic graphs, we design a graph difference-based strategy to significantly reduce the transfer time. We develop a simple, but effective data distribution technique under which the communication volume remains fixed and linear in the input size, for any number of GPUs. Our experiments using billion-size graphs on a system of 128 GPUs shows that: (i) the distribution scheme achieves up to 30x speedup on 128 GPUs; (ii) the graph-difference technique reduces the transfer time by a factor of up to 4.1x and the overall execution time by up to 40%