 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-Aware Epipolar Matching for Multi-View Multi-Person 3D Pose Estimation in Basketball
May 28, 2026Multi-view multi-person 3D pose estimation in team sports scenarios remains challenging due to player occlusions, appearance similarity caused by team uniforms, and the scarcity of annotated multi-view data, all of which limit the effectiveness and generalization capability of learning-based methods. In contrast, the performance of training-free approaches is inherently constrained by the accuracy of 2D keypoint detection and the robustness of cross-view association. To address these challenges, we propose Mesh-Aware Epipolar Matching (MAEM), a training-free framework for multi-view multi-person 3D pose estimation. Our method employs a monocular 3D human mesh recovery model as the frontend and introduces a two-stage epipolar matching strategy based on the recovered mesh outputs. Specifically, the proposed framework combines disjoint-set-union-based clustering with per-joint triangulation to achieve robust cross-view association and accurate 3D pose reconstruction. Experiments on two public multi-view basketball datasets demonstrate that MAEM consistently outperforms existing training-free association baselines while achieving competitive RGB-only performance in both indoor and outdoor basketball scenarios. MAEM achieves MPJPE/PA-MPJPE scores of 59.8/40.7 mm on SportCenter EPFL and 74.0/51.8 mm on Human-M3 Basketball, highlighting the effectiveness of dense mesh geometry for cross-view association without requiring target-domain training or fine-tuning.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
VIFSS: View-Invariant and Figure Skating-Specific Pose Representation Learning for Temporal Action Segmentation
Aug 14, 2025Understanding human actions from videos plays a critical role across various domains, including sports analytics. In figure skating, accurately recognizing the type and timing of jumps a skater performs is essential for objective performance evaluation. However, this task typically requires expert-level knowledge due to the fine-grained and complex nature of jump procedures. While recent approaches have attempted to automate this task using Temporal Action Segmentation (TAS), there are two major limitations to TAS for figure skating: the annotated data is insufficient, and existing methods do not account for the inherent three-dimensional aspects and procedural structure of jump actions. In this work, we propose a new TAS framework for figure skating jumps that explicitly incorporates both the three-dimensional nature and the semantic procedure of jump movements. First, we propose a novel View-Invariant, Figure Skating-Specific pose representation learning approach (VIFSS) that combines contrastive learning as pre-training and action classification as fine-tuning. For view-invariant contrastive pre-training, we construct FS-Jump3D, the first publicly available 3D pose dataset specialized for figure skating jumps. Second, we introduce a fine-grained annotation scheme that marks the ``entry (preparation)'' and ``landing'' phases, enabling TAS models to learn the procedural structure of jumps. Extensive experiments demonstrate the effectiveness of our framework. Our method achieves over 92% F1@50 on element-level TAS, which requires recognizing both jump types and rotation levels. Furthermore, we show that view-invariant contrastive pre-training is particularly effective when fine-tuning data is limited, highlighting the practicality of our approach in real-world scenarios.
KASportsFormer: Kinematic Anatomy Enhanced Transformer for 3D Human Pose Estimation on Short Sports Scene Video
Jul 28, 2025Recent transformer based approaches have demonstrated impressive performance in solving real-world 3D human pose estimation problems. Albeit these approaches achieve fruitful results on benchmark datasets, they tend to fall short of sports scenarios where human movements are more complicated than daily life actions, as being hindered by motion blur, occlusions, and domain shifts. Moreover, due to the fact that critical motions in a sports game often finish in moments of time (e.g., shooting), the ability to focus on momentary actions is becoming a crucial factor in sports analysis, where current methods appear to struggle with instantaneous scenarios. To overcome these limitations, we introduce KASportsFormer, a novel transformer based 3D pose estimation framework for sports that incorporates a kinematic anatomy-informed feature representation and integration module. In which the inherent kinematic motion information is extracted with the Bone Extractor (BoneExt) and Limb Fuser (LimbFus) modules and encoded in a multimodal manner. This improved the capability of comprehending sports poses in short videos. We evaluate our method through two representative sports scene datasets: SportsPose and WorldPose. Experimental results show that our proposed method achieves state-of-the-art results with MPJPE errors of 58.0mm and 34.3mm, respectively. Our code and models are available at: https://github.com/jw0r1n/KASportsFormer
AthletePose3D: A Benchmark Dataset for 3D Human Pose Estimation and Kinematic Validation in Athletic Movements
Mar 11, 2025Human pose estimation is a critical task in computer vision and sports biomechanics, with applications spanning sports science, rehabilitation, and biomechanical research. While significant progress has been made in monocular 3D pose estimation, current datasets often fail to capture the complex, high-acceleration movements typical of competitive sports. In this work, we introduce AthletePose3D, a novel dataset designed to address this gap. AthletePose3D includes 12 types of sports motions across various disciplines, with approximately 1.3 million frames and 165 thousand individual postures, specifically capturing high-speed, high-acceleration athletic movements. We evaluate state-of-the-art (SOTA) monocular 2D and 3D pose estimation models on the dataset, revealing that models trained on conventional datasets perform poorly on athletic motions. However, fine-tuning these models on AthletePose3D notably reduces the SOTA model mean per joint position error (MPJPE) from 214mm to 65mm-a reduction of over 69%. We also validate the kinematic accuracy of monocular pose estimations through waveform analysis, highlighting strong correlations in joint angle estimations but limitations in velocity estimation. Our work provides a comprehensive evaluation of monocular pose estimation models in the context of sports, contributing valuable insights for advancing monocular pose estimation techniques in high-performance sports environments. The dataset, code, and model checkpoints are available at: https://github.com/calvinyeungck/AthletePose3D
3D Pose-Based Temporal Action Segmentation for Figure Skating: A Fine-Grained and Jump Procedure-Aware Annotation Approach
Aug 29, 2024



Understanding human actions from videos is essential in many domains, including sports. In figure skating, technical judgments are performed by watching skaters' 3D movements, and its part of the judging procedure can be regarded as a Temporal Action Segmentation (TAS) task. TAS tasks in figure skating that automatically assign temporal semantics to video are actively researched. However, there is a lack of datasets and effective methods for TAS tasks requiring 3D pose data. In this study, we first created the FS-Jump3D dataset of complex and dynamic figure skating jumps using optical markerless motion capture. We also propose a new fine-grained figure skating jump TAS dataset annotation method with which TAS models can learn jump procedures. In the experimental results, we validated the usefulness of 3D pose features as input and the fine-grained dataset for the TAS model in figure skating. FS-Jump3D Dataset is available at https://github.com/ryota-skating/FS-Jump3D.
Runner re-identification from single-view video in the open-world setting
Oct 18, 2023In many sports, player re-identification is crucial for automatic video processing and analysis. However, most of the current studies on player re-identification in multi- or single-view sports videos focus on re-identification in the closed-world setting using labeled image dataset, and player re-identification in the open-world setting for automatic video analysis is not well developed. In this paper, we propose a runner re-identification system that directly processes single-view video to address the open-world setting. In the open-world setting, we cannot use labeled dataset and have to process video directly. The proposed system automatically processes raw video as input to identify runners, and it can identify runners even when they are framed out multiple times. For the automatic processing, we first detect the runners in the video using the pre-trained YOLOv8 and the fine-tuned EfficientNet. We then track the runners using ByteTrack and detect their shoes with the fine-tuned YOLOv8. Finally, we extract the image features of the runners using an unsupervised method using the gated recurrent unit autoencoder model. To improve the accuracy of runner re-identification, we use dynamic features of running sequence images. We evaluated the system on a running practice video dataset and showed that the proposed method identified runners with higher accuracy than one of the state-of-the-art models in unsupervised re-identification. We also showed that our unsupervised running dynamic feature extractor was effective for runner re-identification. Our runner re-identification system can be useful for the automatic analysis of running videos.
Automatic detection of faults in race walking from a smartphone camera: a comparison of an Olympic medalist and university athletes
Aug 24, 2022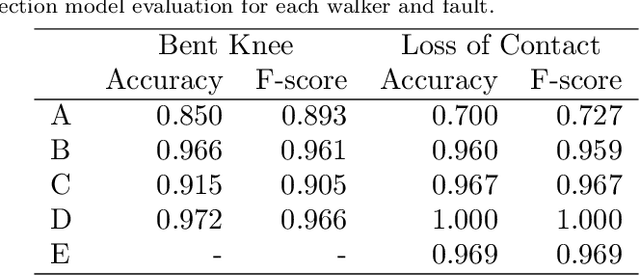
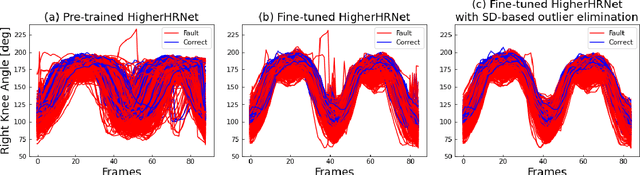
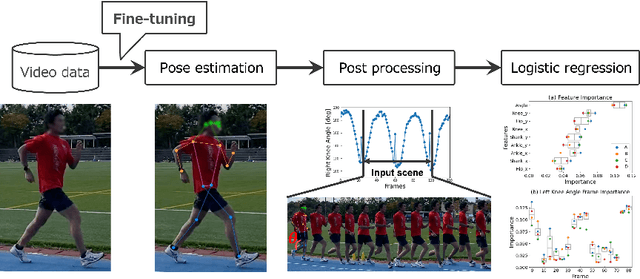
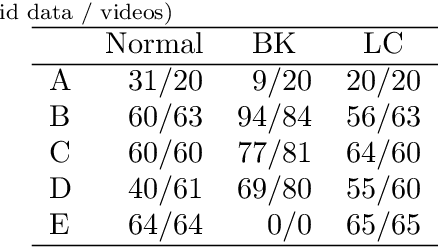
Automatic fault detection is a major challenge in many sports. In race walking, referees visually judge faults according to the rules. Hence, ensuring objectivity and fairness while judging is important. To address this issue, some studies have attempted to use sensors and machine learning to automatically detect faults. However, there are problems associated with sensor attachments and equipment such as a high-speed camera, which conflict with the visual judgement of referees, and the interpretability of the fault detection models. In this study, we proposed a fault detection system for non-contact measurement. We used pose estimation and machine learning models trained based on the judgements of multiple qualified referees to realize fair fault judgement. We verified them using smartphone videos of normal race walking and walking with intentional faults in several athletes including the medalist of the Tokyo Olympics. The validation results show that the proposed system detected faults with an average accuracy of over 90%. We also revealed that the machine learning model detects faults according to the rules of race walking. In addition, the intentional faulty walking movement of the medalist was different from that of university walkers. This finding informs realization of a more general fault detection model. The code and data are available at https://github.com/SZucchini/racewalk-aijudge.