 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaselines and Protocols for Household Speaker Recognition
May 05, 2022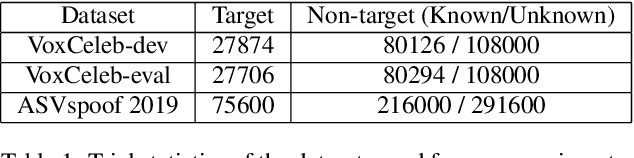
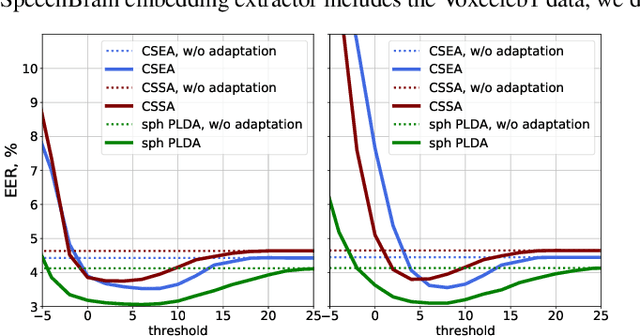
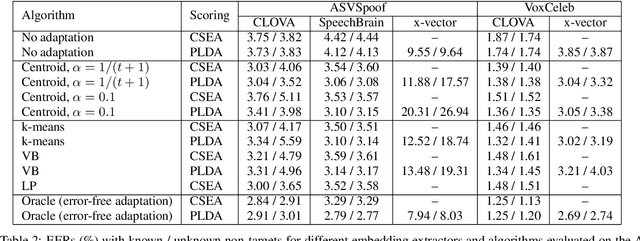
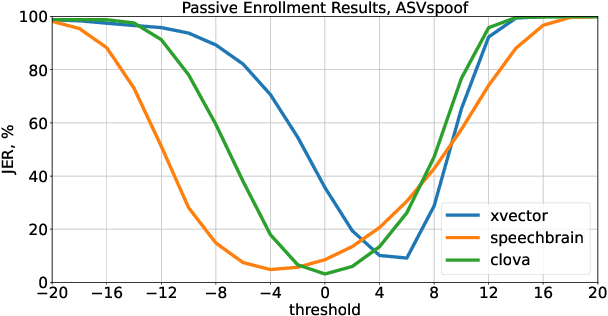
Speaker recognition on household devices, such as smart speakers, features several challenges: (i) robustness across a vast number of heterogeneous domains (households), (ii) short utterances, (iii) possibly absent speaker labels of the enrollment data (passive enrollment), and (iv) presence of unknown persons (guests). While many commercial products exist, there is less published research and no publicly-available evaluation protocols or open-source baselines. Our work serves to bridge this gap by providing an accessible evaluation benchmark derived from public resources (VoxCeleb and ASVspoof 2019 data) along with a preliminary pool of open-source baselines. This includes four algorithms for active enrollment (speaker labels available) and one algorithm for passive enrollment.
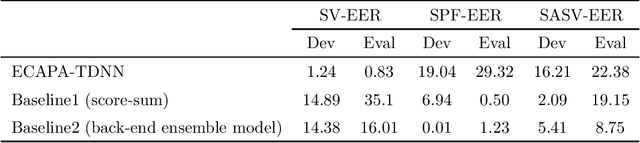
Baseline Systems for the First Spoofing-Aware Speaker Verification Challenge: Score and Embedding Fusion
Apr 21, 2022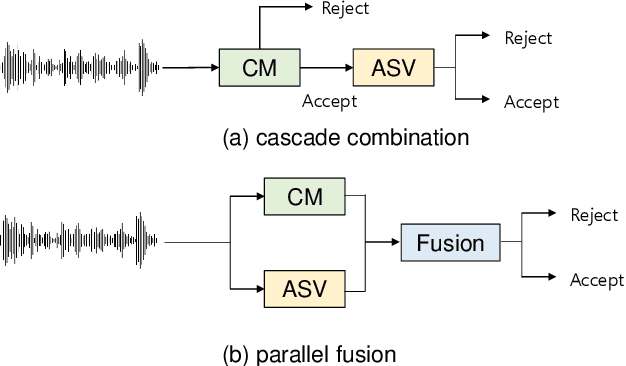

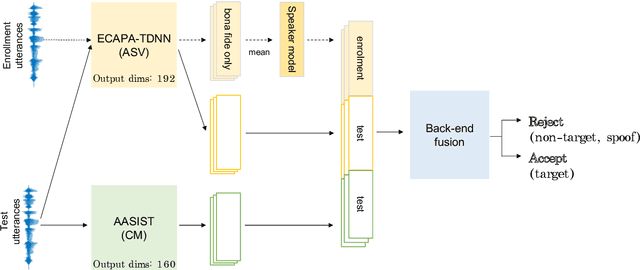
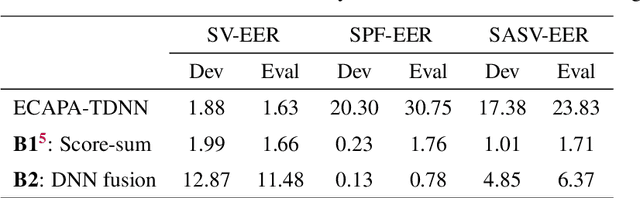
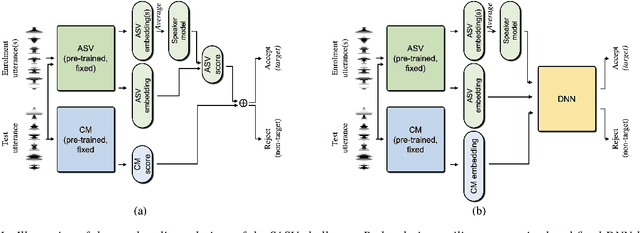
Deep learning has brought impressive progress in the study of both automatic speaker verification (ASV) and spoofing countermeasures (CM). Although solutions are mutually dependent, they have typically evolved as standalone sub-systems whereby CM solutions are usually designed for a fixed ASV system. The work reported in this paper aims to gauge the improvements in reliability that can be gained from their closer integration. Results derived using the popular ASVspoof2019 dataset indicate that the equal error rate (EER) of a state-of-the-art ASV system degrades from 1.63% to 23.83% when the evaluation protocol is extended with spoofed trials.%subjected to spoofing attacks. However, even the straightforward integration of ASV and CM systems in the form of score-sum and deep neural network-based fusion strategies reduce the EER to 1.71% and 6.37%, respectively. The new Spoofing-Aware Speaker Verification (SASV) challenge has been formed to encourage greater attention to the integration of ASV and CM systems as well as to provide a means to benchmark different solutions.
Improving speaker de-identification with functional data analysis of f0 trajectories
Mar 31, 2022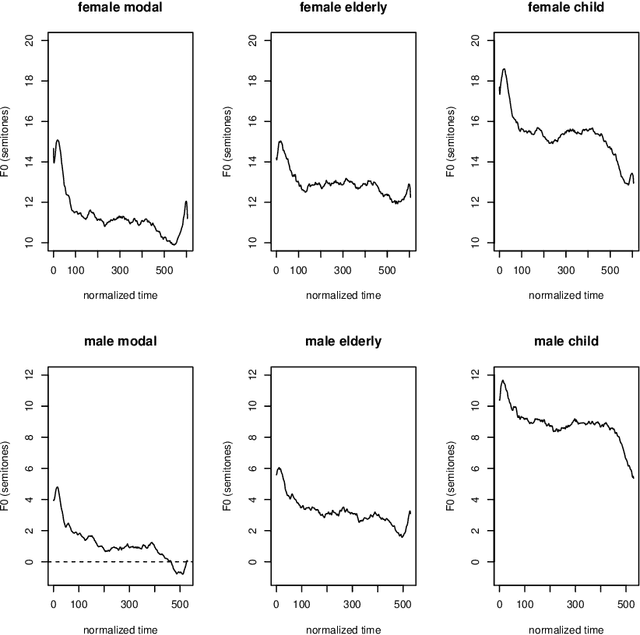
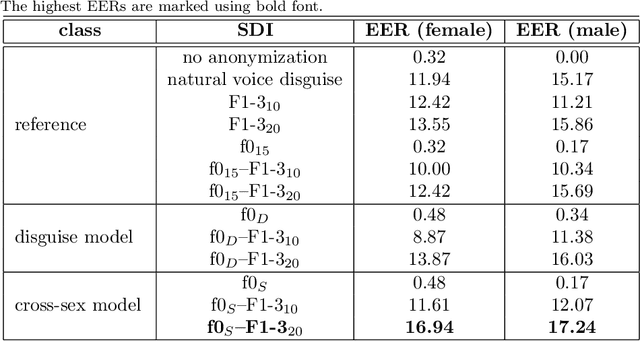
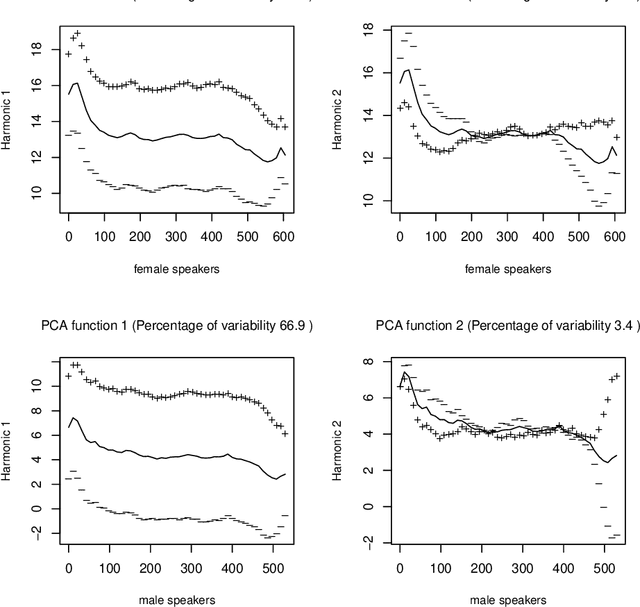
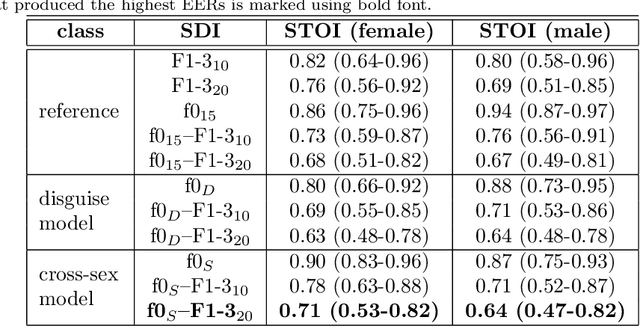
Due to a constantly increasing amount of speech data that is stored in different types of databases, voice privacy has become a major concern. To respond to such concern, speech researchers have developed various methods for speaker de-identification. The state-of-the-art solutions utilize deep learning solutions which can be effective but might be unavailable or impractical to apply for, for example, under-resourced languages. Formant modification is a simpler, yet effective method for speaker de-identification which requires no training data. Still, remaining intonational patterns in formant-anonymized speech may contain speaker-dependent cues. This study introduces a novel speaker de-identification method, which, in addition to simple formant shifts, manipulates f0 trajectories based on functional data analysis. The proposed speaker de-identification method will conceal plausibly identifying pitch characteristics in a phonetically controllable manner and improve formant-based speaker de-identification up to 25%.
SASV 2022: The First Spoofing-Aware Speaker Verification Challenge
Mar 28, 2022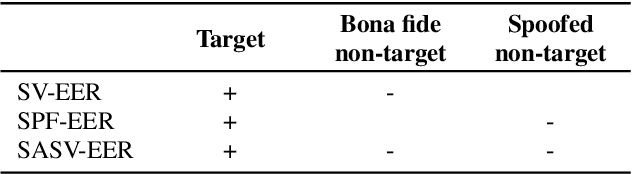
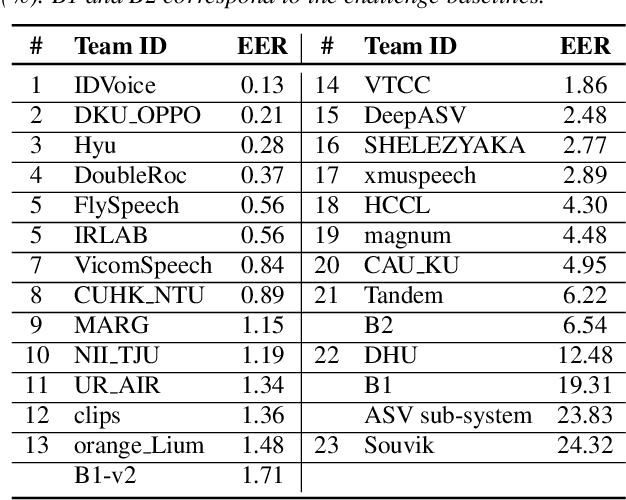
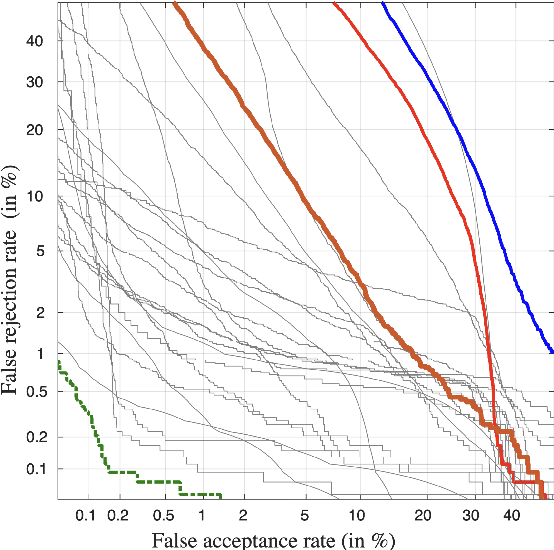
The first spoofing-aware speaker verification (SASV) challenge aims to integrate research efforts in speaker verification and anti-spoofing. We extend the speaker verification scenario by introducing spoofed trials to the usual set of target and impostor trials. In contrast to the established ASVspoof challenge where the focus is upon separate, independently optimised spoofing detection and speaker verification sub-systems, SASV targets the development of integrated and jointly optimised solutions. Pre-trained spoofing detection and speaker verification models are provided as open source and are used in two baseline SASV solutions. Both models and baselines are freely available to participants and can be used to develop back-end fusion approaches or end-to-end solutions. Using the provided common evaluation protocol, 23 teams submitted SASV solutions. When assessed with target, bona fide non-target and spoofed non-target trials, the top-performing system reduces the equal error rate of a conventional speaker verification system from 23.83% to 0.13%. SASV challenge results are a testament to the reliability of today's state-of-the-art approaches to spoofing detection and speaker verification.
Spoofing-Aware Speaker Verification with Unsupervised Domain Adaptation
Mar 21, 2022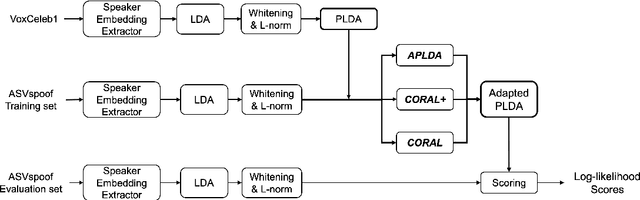
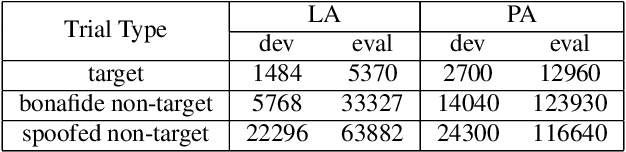
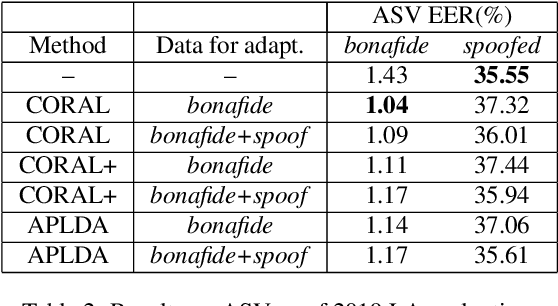
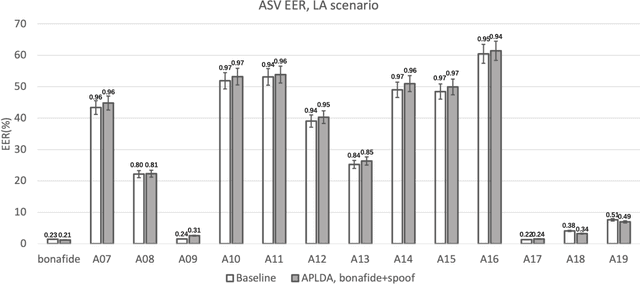
In this paper, we initiate the concern of enhancing the spoofing robustness of the automatic speaker verification (ASV) system, without the primary presence of a separate countermeasure module. We start from the standard ASV framework of the ASVspoof 2019 baseline and approach the problem from the back-end classifier based on probabilistic linear discriminant analysis. We employ three unsupervised domain adaptation techniques to optimize the back-end using the audio data in the training partition of the ASVspoof 2019 dataset. We demonstrate notable improvements on both logical and physical access scenarios, especially on the latter where the system is attacked by replayed audios, with a maximum of 36.1% and 5.3% relative improvement on bonafide and spoofed cases, respectively. We perform additional studies such as per-attack breakdown analysis, data composition, and integration with a countermeasure system at score-level with Gaussian back-end.
Learnable Nonlinear Compression for Robust Speaker Verification
Feb 10, 2022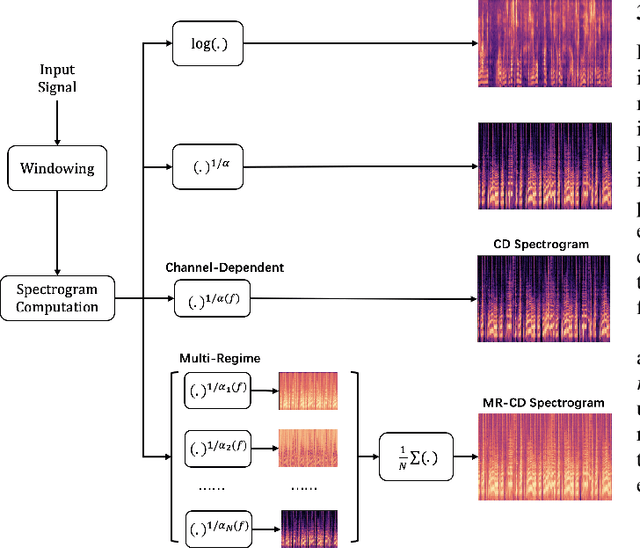

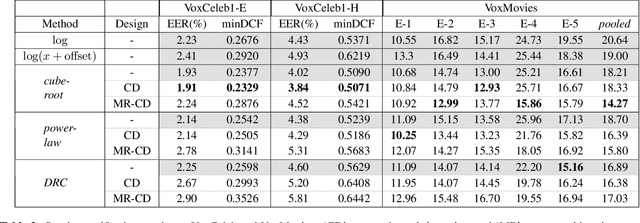
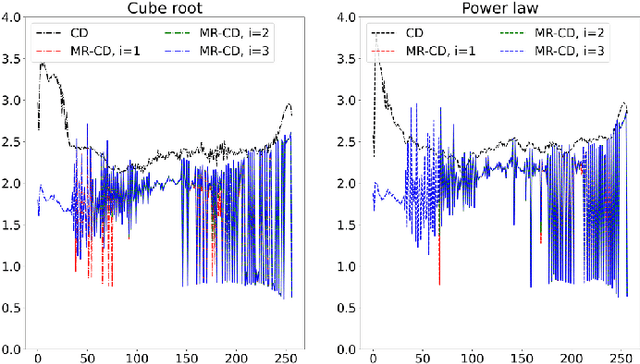
In this study, we focus on nonlinear compression methods in spectral features for speaker verification based on deep neural network. We consider different kinds of channel-dependent (CD) nonlinear compression methods optimized in a data-driven manner. Our methods are based on power nonlinearities and dynamic range compression (DRC). We also propose multi-regime (MR) design on the nonlinearities, at improving robustness. Results on VoxCeleb1 and VoxMovies data demonstrate improvements brought by proposed compression methods over both the commonly-used logarithm and their static counterparts, especially for ones based on power function. While CD generalization improves performance on VoxCeleb1, MR provides more robustness on VoxMovies, with a maximum relative equal error rate reduction of 21.6%.
SASV Challenge 2022: A Spoofing Aware Speaker Verification Challenge Evaluation Plan
Jan 25, 2022
ASV (automatic speaker verification) systems are intrinsically required to reject both non-target (e.g., voice uttered by different speaker) and spoofed (e.g., synthesised or converted) inputs. However, there is little consideration for how ASV systems themselves should be adapted when they are expected to encounter spoofing attacks, nor when they operate in tandem with CMs (spoofing countermeasures), much less how both systems should be jointly optimised. The goal of the first SASV (spoofing-aware speaker verification) challenge, a special sesscion in ISCA INTERSPEECH 2022, is to promote development of integrated systems that can perform ASV and CM simultaneously.
Optimizing Tandem Speaker Verification and Anti-Spoofing Systems
Jan 24, 2022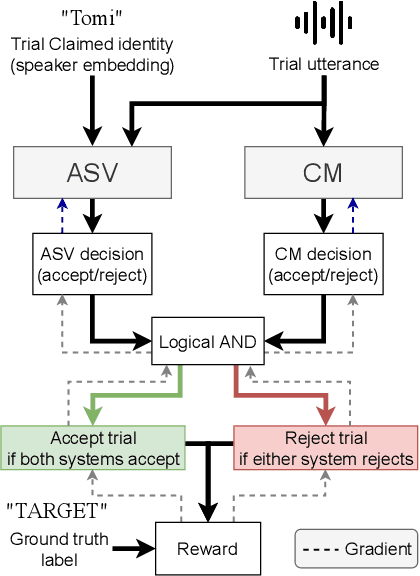
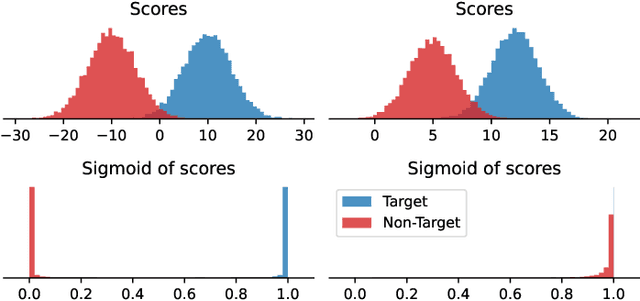
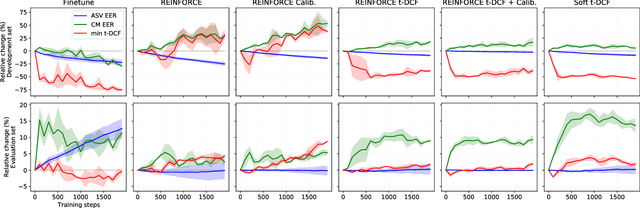

As automatic speaker verification (ASV) systems are vulnerable to spoofing attacks, they are typically used in conjunction with spoofing countermeasure (CM) systems to improve security. For example, the CM can first determine whether the input is human speech, then the ASV can determine whether this speech matches the speaker's identity. The performance of such a tandem system can be measured with a tandem detection cost function (t-DCF). However, ASV and CM systems are usually trained separately, using different metrics and data, which does not optimize their combined performance. In this work, we propose to optimize the tandem system directly by creating a differentiable version of t-DCF and employing techniques from reinforcement learning. The results indicate that these approaches offer better outcomes than finetuning, with our method providing a 20% relative improvement in the t-DCF in the ASVSpoof19 dataset in a constrained setting.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing. Published version available at: https://ieeexplore.ieee.org/document/9664367
Optimizing Multi-Taper Features for Deep Speaker Verification
Oct 21, 2021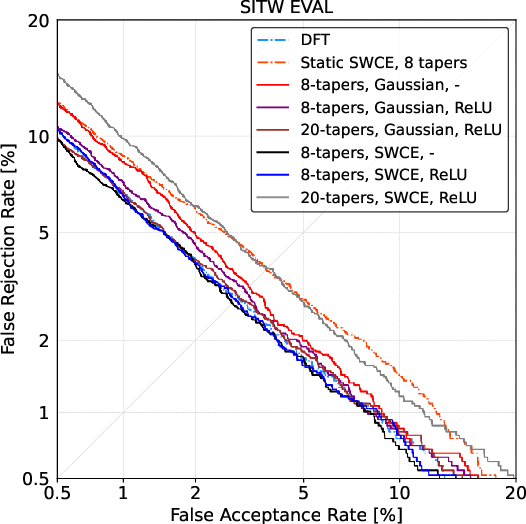
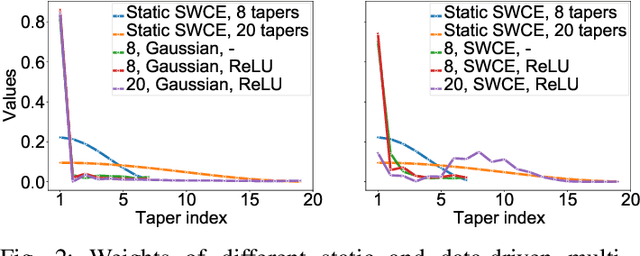
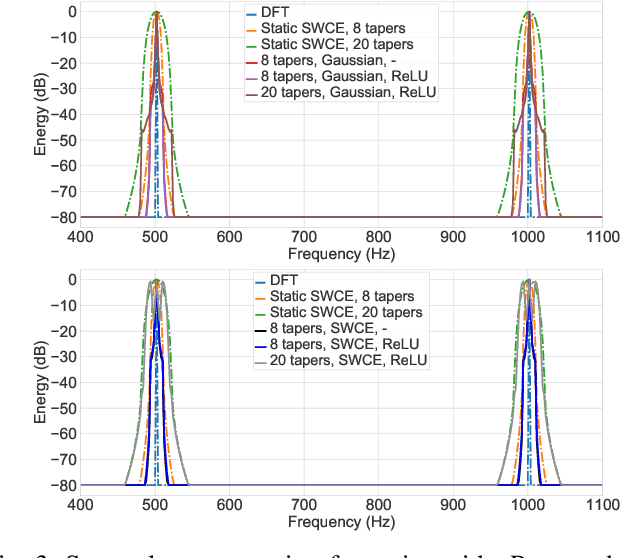
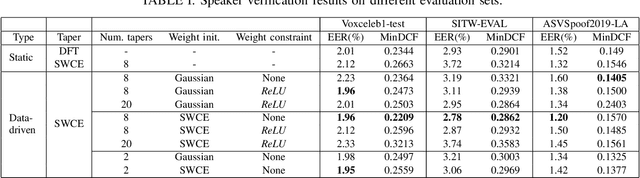
Multi-taper estimators provide low-variance power spectrum estimates that can be used in place of the windowed discrete Fourier transform (DFT) to extract speech features such as mel-frequency cepstral coefficients (MFCCs). Even if past work has reported promising automatic speaker verification (ASV) results with Gaussian mixture model-based classifiers, the performance of multi-taper MFCCs with deep ASV systems remains an open question. Instead of a static-taper design, we propose to optimize the multi-taper estimator jointly with a deep neural network trained for ASV tasks. With a maximum improvement on the SITW corpus of 25.8% in terms of equal error rate over the static-taper, our method helps preserve a balanced level of leakage and variance, providing more robustness.
VoxCeleb Enrichment for Age and Gender Recognition
Sep 28, 2021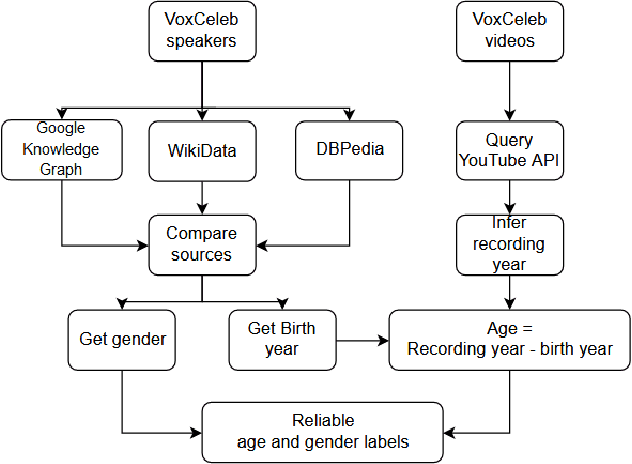
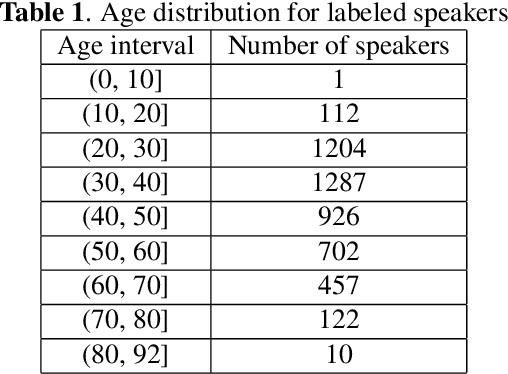
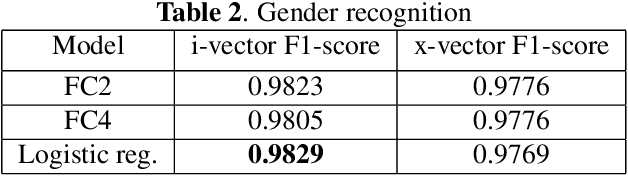
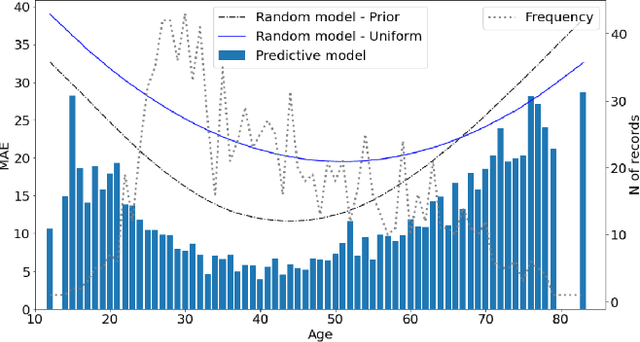
VoxCeleb datasets are widely used in speaker recognition studies. Our work serves two purposes. First, we provide speaker age labels and (an alternative) annotation of speaker gender. Second, we demonstrate the use of this metadata by constructing age and gender recognition models with different features and classifiers. We query different celebrity databases and apply consensus rules to derive age and gender labels. We also compare the original VoxCeleb gender labels with our labels to identify records that might be mislabeled in the original VoxCeleb data. On modeling side, we design a comprehensive study of multiple features and models for recognizing gender and age. Our best system, using i-vector features, achieved an F1-score of 0.9829 for gender recognition task using logistic regression, and the lowest mean absolute error (MAE) in age regression, 9.443 years, is obtained with ridge regression. This indicates challenge in age estimation from in-the-wild style speech data.