 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFROST-EMA: Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography Measurements with L1, L2 and Imitated L2 Accents
Jun 10, 2025We introduce a new FROST-EMA (Finnish and Russian Oral Speech Dataset of Electromagnetic Articulography) corpus. It consists of 18 bilingual speakers, who produced speech in their native language (L1), second language (L2), and imitated L2 (fake foreign accent). The new corpus enables research into language variability from phonetic and technological points of view. Accordingly, we include two preliminary case studies to demonstrate both perspectives. The first case study explores the impact of L2 and imitated L2 on the performance of an automatic speaker verification system, while the second illustrates the articulatory patterns of one speaker in L1, L2, and a fake accent.
Improving speaker de-identification with functional data analysis of f0 trajectories
Mar 31, 2022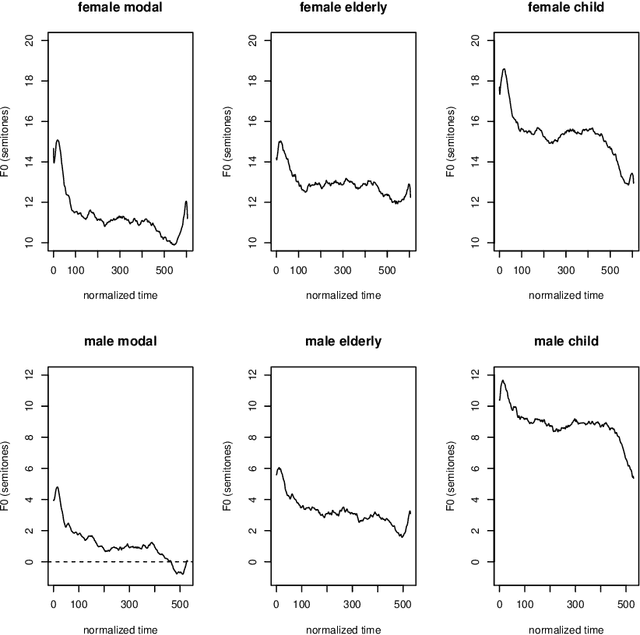
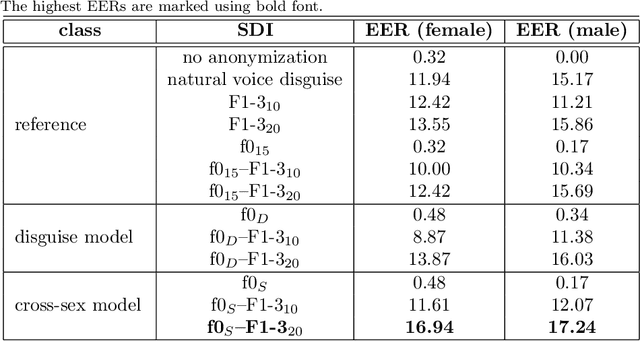
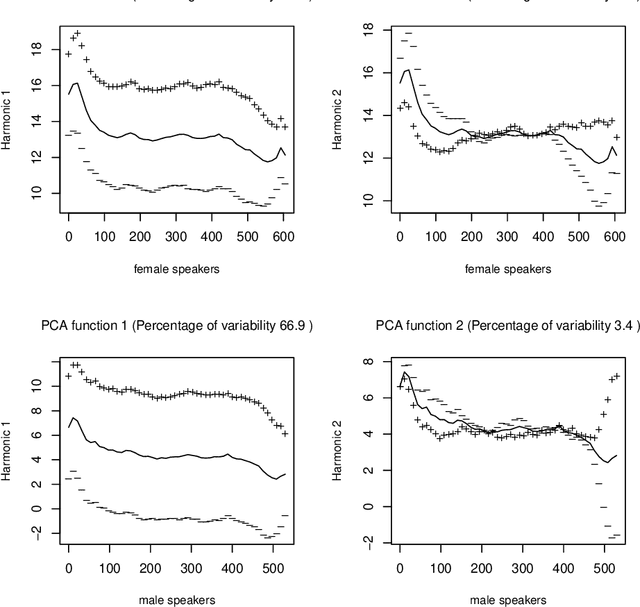
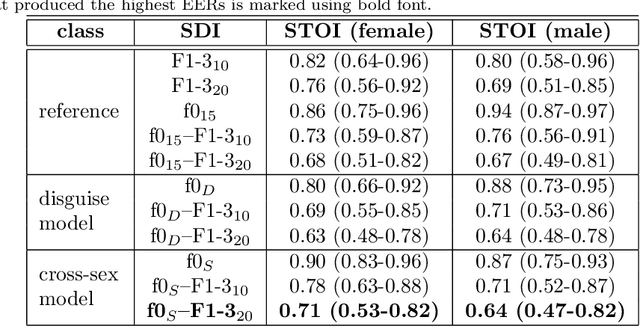
Due to a constantly increasing amount of speech data that is stored in different types of databases, voice privacy has become a major concern. To respond to such concern, speech researchers have developed various methods for speaker de-identification. The state-of-the-art solutions utilize deep learning solutions which can be effective but might be unavailable or impractical to apply for, for example, under-resourced languages. Formant modification is a simpler, yet effective method for speaker de-identification which requires no training data. Still, remaining intonational patterns in formant-anonymized speech may contain speaker-dependent cues. This study introduces a novel speaker de-identification method, which, in addition to simple formant shifts, manipulates f0 trajectories based on functional data analysis. The proposed speaker de-identification method will conceal plausibly identifying pitch characteristics in a phonetically controllable manner and improve formant-based speaker de-identification up to 25%.