 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Bi-Tempered Logistic Loss Based on Bregman Divergences
Jun 08, 2019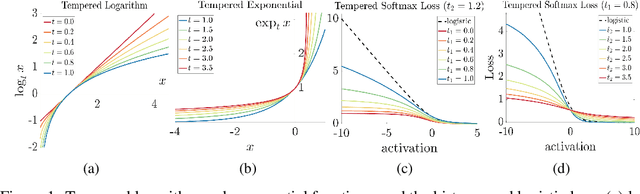
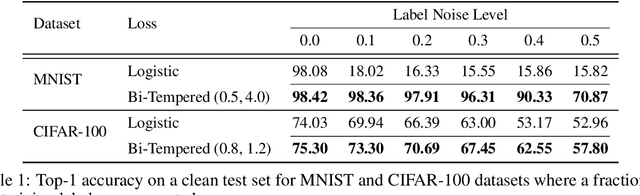
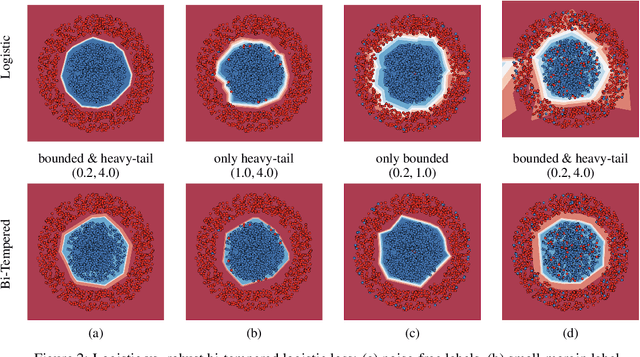

We introduce a temperature into the exponential function and replace the softmax output layer of neural nets by a high temperature generalization. Similarly, the logarithm in the log loss we use for training is replaced by a low temperature logarithm. By tuning the two temperatures we create loss functions that are non-convex already in the single layer case. When replacing the last layer of the neural nets by our two temperature generalization of logistic regression, the training becomes more robust to noise. We visualize the effect of tuning the two temperatures in a simple setting and show the efficacy of our method on large data sets. Our methodology is based on Bregman divergences and is superior to a related two-temperature method using the Tsallis divergence.
Semi-Cyclic Stochastic Gradient Descent
Apr 23, 2019
We consider convex SGD updates with a block-cyclic structure, i.e. where each cycle consists of a small number of blocks, each with many samples from a possibly different, block-specific, distribution. This situation arises, e.g., in Federated Learning where the mobile devices available for updates at different times during the day have different characteristics. We show that such block-cyclic structure can significantly deteriorate the performance of SGD, but propose a simple approach that allows prediction with the same performance guarantees as for i.i.d., non-cyclic, sampling.
Better Algorithms for Stochastic Bandits with Adversarial Corruptions
Mar 28, 2019We study the stochastic multi-armed bandits problem in the presence of adversarial corruption. We present a new algorithm for this problem whose regret is nearly optimal, substantially improving upon previous work. Our algorithm is agnostic to the level of adversarial contamination and can tolerate a significant amount of corruption with virtually no degradation in performance.
Learning Linear-Quadratic Regulators Efficiently with only $\sqrt{T}$ Regret
Feb 23, 2019We present the first computationally-efficient algorithm with $\widetilde O(\sqrt{T})$ regret for learning in Linear Quadratic Control systems with unknown dynamics. By that, we resolve an open question of Abbasi-Yadkori and Szepesv\'ari (2011) and Dean, Mania, Matni, Recht, and Tu (2018).
Memory-Efficient Adaptive Optimization for Large-Scale Learning
Jan 30, 2019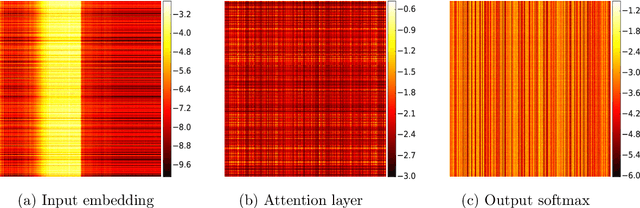
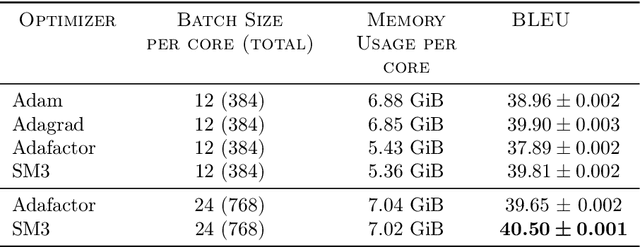
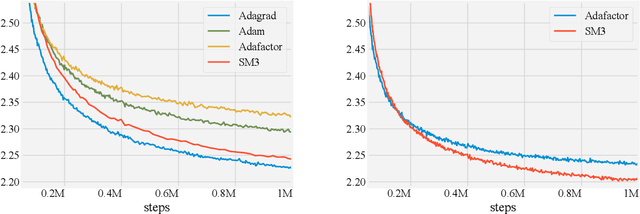
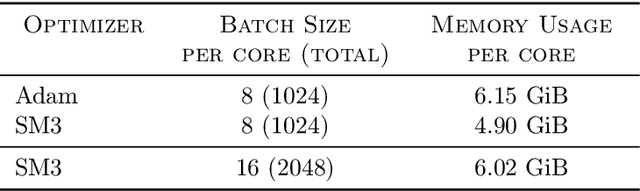
Adaptive gradient-based optimizers such as AdaGrad and Adam are among the methods of choice in modern machine learning. These methods maintain second-order statistics of each parameter, thus doubling the memory footprint of the optimizer. In behemoth-size applications, this memory overhead restricts the size of the model being used as well as the number of examples in a mini-batch. We describe a novel, simple, and flexible adaptive optimization method with sublinear memory cost that retains the benefits of per-parameter adaptivity while allowing for larger models and mini-batches. We give convergence guarantees for our method and demonstrate its effectiveness in training very large deep models.
Online Linear Quadratic Control
Jun 19, 2018
We study the problem of controlling linear time-invariant systems with known noisy dynamics and adversarially chosen quadratic losses. We present the first efficient online learning algorithms in this setting that guarantee $O(\sqrt{T})$ regret under mild assumptions, where $T$ is the time horizon. Our algorithms rely on a novel SDP relaxation for the steady-state distribution of the system. Crucially, and in contrast to previously proposed relaxations, the feasible solutions of our SDP all correspond to "strongly stable" policies that mix exponentially fast to a steady state.
Shampoo: Preconditioned Stochastic Tensor Optimization
Mar 02, 2018
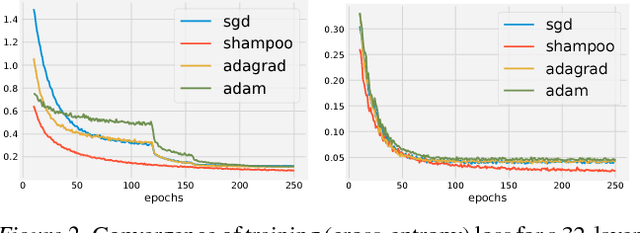
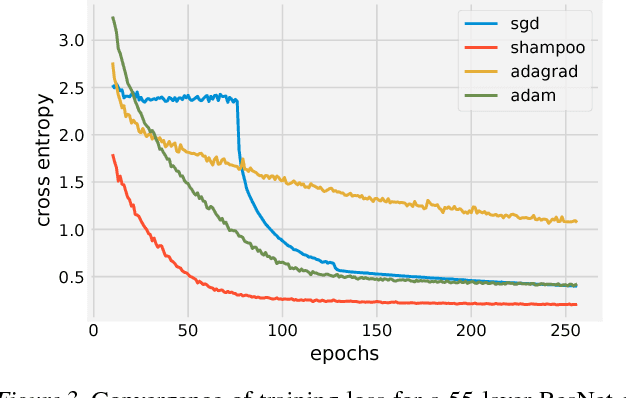
Preconditioned gradient methods are among the most general and powerful tools in optimization. However, preconditioning requires storing and manipulating prohibitively large matrices. We describe and analyze a new structure-aware preconditioning algorithm, called Shampoo, for stochastic optimization over tensor spaces. Shampoo maintains a set of preconditioning matrices, each of which operates on a single dimension, contracting over the remaining dimensions. We establish convergence guarantees in the stochastic convex setting, the proof of which builds upon matrix trace inequalities. Our experiments with state-of-the-art deep learning models show that Shampoo is capable of converging considerably faster than commonly used optimizers. Although it involves a more complex update rule, Shampoo's runtime per step is comparable to that of simple gradient methods such as SGD, AdaGrad, and Adam.
Multi-Armed Bandits with Metric Movement Costs
Oct 24, 2017We consider the non-stochastic Multi-Armed Bandit problem in a setting where there is a fixed and known metric on the action space that determines a cost for switching between any pair of actions. The loss of the online learner has two components: the first is the usual loss of the selected actions, and the second is an additional loss due to switching between actions. Our main contribution gives a tight characterization of the expected minimax regret in this setting, in terms of a complexity measure $\mathcal{C}$ of the underlying metric which depends on its covering numbers. In finite metric spaces with $k$ actions, we give an efficient algorithm that achieves regret of the form $\widetilde{O}(\max\{\mathcal{C}^{1/3}T^{2/3},\sqrt{kT}\})$, and show that this is the best possible. Our regret bound generalizes previous known regret bounds for some special cases: (i) the unit-switching cost regret $\widetilde{\Theta}(\max\{k^{1/3}T^{2/3},\sqrt{kT}\})$ where $\mathcal{C}=\Theta(k)$, and (ii) the interval metric with regret $\widetilde{\Theta}(\max\{T^{2/3},\sqrt{kT}\})$ where $\mathcal{C}=\Theta(1)$. For infinite metrics spaces with Lipschitz loss functions, we derive a tight regret bound of $\widetilde{\Theta}(T^{\frac{d+1}{d+2}})$ where $d \ge 1$ is the Minkowski dimension of the space, which is known to be tight even when there are no switching costs.
A Unified Approach to Adaptive Regularization in Online and Stochastic Optimization
Jun 20, 2017We describe a framework for deriving and analyzing online optimization algorithms that incorporate adaptive, data-dependent regularization, also termed preconditioning. Such algorithms have been proven useful in stochastic optimization by reshaping the gradients according to the geometry of the data. Our framework captures and unifies much of the existing literature on adaptive online methods, including the AdaGrad and Online Newton Step algorithms as well as their diagonal versions. As a result, we obtain new convergence proofs for these algorithms that are substantially simpler than previous analyses. Our framework also exposes the rationale for the different preconditioned updates used in common stochastic optimization methods.
Tight Bounds for Bandit Combinatorial Optimization
Feb 24, 2017
We revisit the study of optimal regret rates in bandit combinatorial optimization---a fundamental framework for sequential decision making under uncertainty that abstracts numerous combinatorial prediction problems. We prove that the attainable regret in this setting grows as $\widetilde{\Theta}(k^{3/2}\sqrt{dT})$ where $d$ is the dimension of the problem and $k$ is a bound over the maximal instantaneous loss, disproving a conjecture of Audibert, Bubeck, and Lugosi (2013) who argued that the optimal rate should be of the form $\widetilde{\Theta}(k\sqrt{dT})$. Our bounds apply to several important instances of the framework, and in particular, imply a tight bound for the well-studied bandit shortest path problem. By that, we also resolve an open problem posed by Cesa-Bianchi and Lugosi (2012).