 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression and Inference of Spiking Neural Networks on Resource-Constrained Hardware
Nov 15, 2025Spiking neural networks (SNNs) communicate via discrete spikes in time rather than continuous activations. Their event-driven nature offers advantages for temporal processing and energy efficiency on resource-constrained hardware, but training and deployment remain challenging. We present a lightweight C-based runtime for SNN inference on edge devices and optimizations that reduce latency and memory without sacrificing accuracy. Trained models exported from SNNTorch are translated to a compact C representation; static, cache-friendly data layouts and preallocation avoid interpreter and allocation overheads. We further exploit sparse spiking activity to prune inactive neurons and synapses, shrinking computation in upstream convolutional layers. Experiments on N-MNIST and ST-MNIST show functional parity with the Python baseline while achieving ~10 speedups on desktop CPU and additional gains with pruning, together with large memory reductions that enable microcontroller deployment (Arduino Portenta H7). Results indicate that SNNs can be executed efficiently on conventional embedded platforms when paired with an optimized runtime and spike-driven model compression. Code: https://github.com/karol-jurzec/snn-generator/
Higher-Order Graph Databases
Jun 24, 2025



Recent advances in graph databases (GDBs) have been driving interest in large-scale analytics, yet current systems fail to support higher-order (HO) interactions beyond first-order (one-hop) relations, which are crucial for tasks such as subgraph counting, polyadic modeling, and HO graph learning. We address this by introducing a new class of systems, higher-order graph databases (HO-GDBs) that use lifting and lowering paradigms to seamlessly extend traditional GDBs with HO. We provide a theoretical analysis of OLTP and OLAP queries, ensuring correctness, scalability, and ACID compliance. We implement a lightweight, modular, and parallelizable HO-GDB prototype that offers native support for hypergraphs, node-tuples, subgraphs, and other HO structures under a unified API. The prototype scales to large HO OLTP & OLAP workloads and shows how HO improves analytical tasks, for example enhancing accuracy of graph neural networks within a GDB by 44%. Our work ensures low latency and high query throughput, and generalizes both ACID-compliant and eventually consistent systems.
Benchmarking of CPU-intensive Stream Data Processing in The Edge Computing Systems
May 12, 2025Edge computing has emerged as a pivotal technology, offering significant advantages such as low latency, enhanced data security, and reduced reliance on centralized cloud infrastructure. These benefits are crucial for applications requiring real-time data processing or strict security measures. Despite these advantages, edge devices operating within edge clusters are often underutilized. This inefficiency is mainly due to the absence of a holistic performance profiling mechanism which can help dynamically adjust the desired system configuration for a given workload. Since edge computing environments involve a complex interplay between CPU frequency, power consumption, and application performance, a deeper understanding of these correlations is essential. By uncovering these relationships, it becomes possible to make informed decisions that enhance both computational efficiency and energy savings. To address this gap, this paper evaluates the power consumption and performance characteristics of a single processing node within an edge cluster using a synthetic microbenchmark by varying the workload size and CPU frequency. The results show how an optimal measure can lead to optimized usage of edge resources, given both performance and power consumption.
Device management and network connectivity as missing elements in TinyML landscape
Apr 23, 2023Deployment of solutions based on TinyML requires meeting several challenges. These include hardware heterogeneity, microprocessor (MCU) architectures, and resource availability constraints. Another challenge is the variety of operating systems for MCU, limited memory management implementations and limited software interoperability between devices. A number of these challenges are solved by dedicated programming libraries and the ability to compile code for specific devices. Nevertheless, the challenge discussed in the paper is the issue of network connectivity for such solutions. We point out that more emphasis should be placed on standard protocols, interoperability of solutions and security. Finally, the paper discusses how the LwM2M protocol can solve the identified challenges related to network connectivity and interoperability.
Online Anomaly Detection Based On Reservoir Sampling and LOF for IoT devices
Jun 28, 2022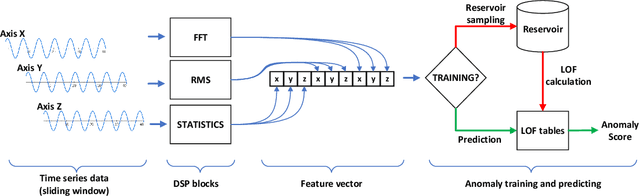

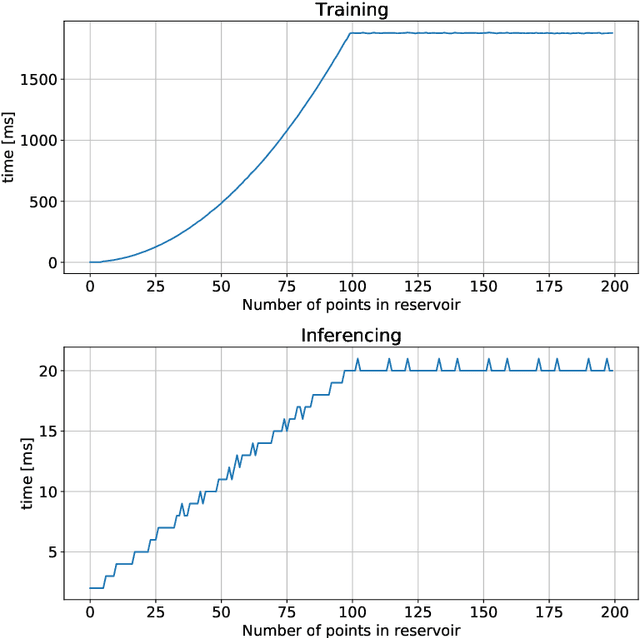
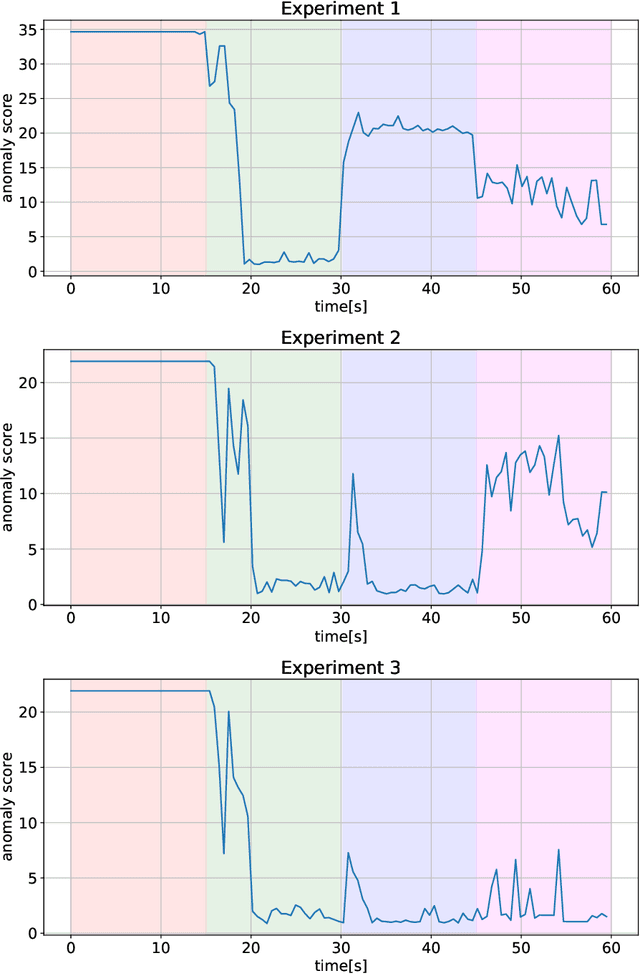
The growing number of IoT devices and their use to monitor the operation of machines and equipment increases interest in anomaly detection algorithms running on devices. However, the difficulty is the limitations of the available computational and memory resources on the devices. In the case of microcontrollers (MCUs), these are single megabytes of program and several hundred kilobytes of working memory. Consequently, algorithms must be appropriately matched to the capabilities of the devices. In the paper, we analyse the processing pipeline for anomaly detection and implementation of the Local Outliner Factor (LOF) algorithm on a MCU. We also show that it is possible to train such an algorithm directly on the device, which gives great potential to use the solution in real devices.
Machine Learning in the Internet of Things for Industry 4.0
May 22, 2020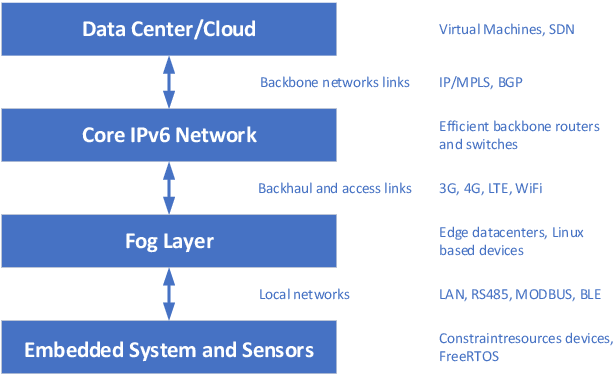
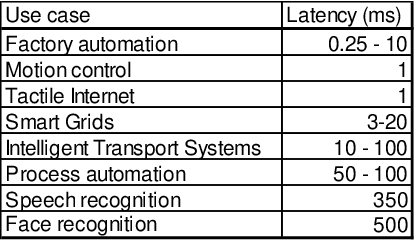

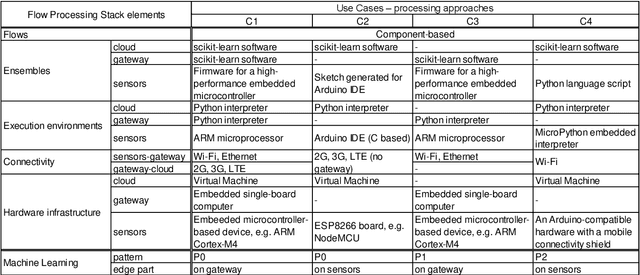
Number of IoT devices is constantly increasing which results in greater complexity of computations and high data velocity. One of the approach to process sensor data is dataflow programming. It enables the development of reactive software with short processing and rapid response times, especially when moved to the edge of the network. This is especially important in systems that utilize online machine learning algorithms to analyze ongoing processes such as those observed in Industry 4.0. In this paper, we show that organization of such systems depends on the entire processing stack, from the hardware layer all the way to the software layer, as well as on the required response times of the IoT system. We propose a flow processing stack for such systems along with the organizational machine learning architectural patterns that enable the possibility to spread the learning and inferencing on the edge and the cloud. In the paper, we analyse what latency is introduced by communication technologies used in the IoT for cloud connectivity and how they influence the response times of the system. Finally, we are providing recommendations which machine learning patterns should be used in the IoT systems depending on the application type.