 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
MAVEN: A Multi-stage Agentic Annotation Pipeline for Video Reasoning Tasks
May 21, 2026Training Vision Language Models (VLMs) for video event reasoning requires high-quality structured annotations capturing not only what happened, but when, where, why, and with what consequence, at a scale manual labelling cannot support. We present MAVEN (Multi-stage Agentic Video Event aNnotation), a multi-stage agentic pipeline that turns raw videos into multi-task training data with Chain-of-Thought (CoT) reasoning traces, organized around a designated Event of Focus. At its core, MAVEN synthesizes a Multi-Scale Spatio-Temporal Event Description (MSTED) from three complementary caption levels; this explicit intermediate serves as the sole input to downstream Q&A generation across multiple task formats. Crucially, MAVEN supports agent-driven domain adaptation: given a new video dataset and target question examples, the agent redesigns all prompts top-down without manual re-engineering. A hierarchical refinement loop further classifies annotation errors against a taxonomy, traces root causes to the originating pipeline stage, and applies targeted edits that rewrite prompts or modify the pipeline structure itself, iteratively improving data quality. We apply MAVEN to label over 5,300 traffic videos and fine-tune Cosmos-Reason2-8B on the resulting data. On a private CCTV evaluation set, fine-tuning surpasses both Gemini 2.5 Pro and 3.1 Flash, including a $+38.8$-point gain in MCQ accuracy over zero-shot. On AccidentBench, CCTV-only training lifts Cosmos-Reason2 by $+10.7$ MCQ points and matches Gemini 2.5 Pro despite seeing no dashcam videos; adding agent-adapted dashcam annotations narrows the gap to Gemini 3.1 Flash, and RL post-training pushes overall performance past both Gemini baselines. Qualitative results on warehouse surveillance and public safety videos further show the agentic workflow readily adapts the pipeline to new domains.
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Multi-Agent Dynamic Pricing in a Blockchain Protocol Using Gaussian Bandits
Dec 13, 2022



The Graph Protocol indexes historical blockchain transaction data and makes it available for querying. As the protocol is decentralized, there are many independent Indexers that index and compete with each other for serving queries to the Consumers. One dimension along which Indexers compete is pricing. In this paper, we propose a bandit-based algorithm for maximization of Indexers' revenue via Consumer budget discovery. We present the design and the considerations we had to make for a dynamic pricing algorithm being used by multiple agents simultaneously. We discuss the results achieved by our dynamic pricing bandits both in simulation and deployed into production on one of the Indexers operating on Ethereum. We have open-sourced both the simulation framework and tools we created, which other Indexers have since started to adapt into their own workflows.
A Fast and Robust BERT-based Dialogue State Tracker for Schema-Guided Dialogue Dataset
Aug 27, 2020

Dialog State Tracking (DST) is one of the most crucial modules for goal-oriented dialogue systems. In this paper, we introduce FastSGT (Fast Schema Guided Tracker), a fast and robust BERT-based model for state tracking in goal-oriented dialogue systems. The proposed model is designed for the Schema-Guided Dialogue (SGD) dataset which contains natural language descriptions for all the entities including user intents, services, and slots. The model incorporates two carry-over procedures for handling the extraction of the values not explicitly mentioned in the current user utterance. It also uses multi-head attention projections in some of the decoders to have a better modelling of the encoder outputs. In the conducted experiments we compared FastSGT to the baseline model for the SGD dataset. Our model keeps the efficiency in terms of computational and memory consumption while improving the accuracy significantly. Additionally, we present ablation studies measuring the impact of different parts of the model on its performance. We also show the effectiveness of data augmentation for improving the accuracy without increasing the amount of computational resources.
Transfer Learning in Visual and Relational Reasoning
Nov 27, 2019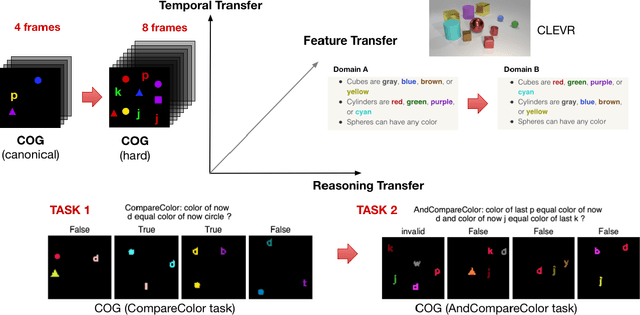
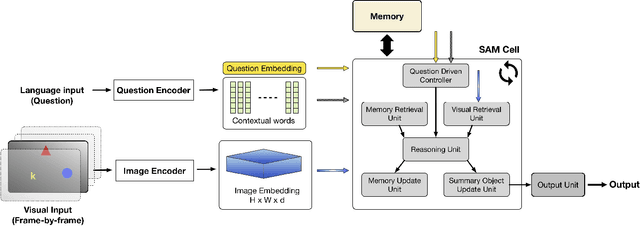

Transfer learning is becoming the de facto solution for vision and text encoders in the front-end processing of machine learning solutions. Utilizing vast amounts of knowledge in pre-trained models and subsequent fine-tuning allows achieving better performance in domains where labeled data is limited. In this paper, we analyze the efficiency of transfer learning in visual reasoning by introducing a new model (SAMNet) and testing it on two datasets: COG and CLEVR. Our new model achieves state-of-the-art accuracy on COG and shows significantly better generalization capabilities compared to the baseline. We also formalize a taxonomy of transfer learning for visual reasoning around three axes: feature, temporal, and reasoning transfer. Based on extensive experimentation of transfer learning on each of the two datasets, we show the performance of the new model along each axis.
PyTorchPipe: a framework for rapid prototyping of pipelines combining language and vision
Oct 18, 2019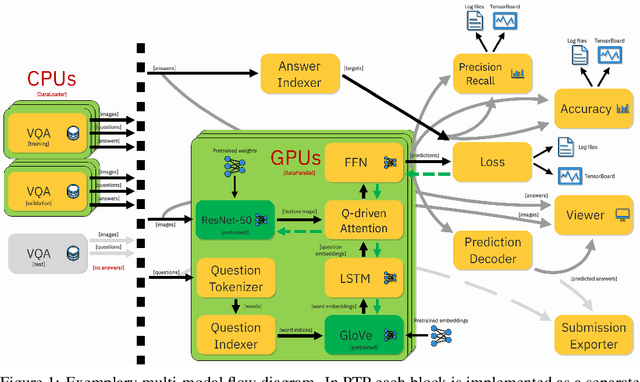

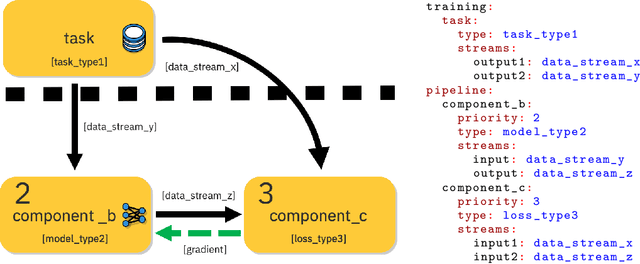
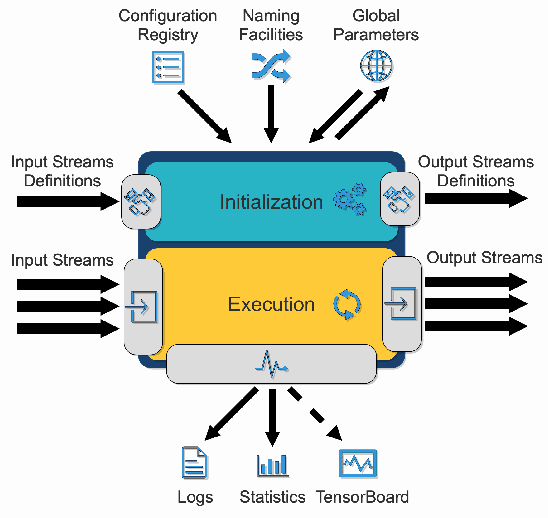
Access to vast amounts of data along with affordable computational power stimulated the reincarnation of neural networks. The progress could not be achieved without adequate software tools, lowering the entry bar for the next generations of researchers and developers. The paper introduces PyTorchPipe (PTP), a framework built on top of PyTorch. Answering the recent needs and trends in machine learning, PTP facilitates building and training of complex, multi-modal models combining language and vision (but is not limited to those two modalities). At its core, PTP employs a component-oriented approach and relies on the concept of a pipeline, defined as a directed acyclic graph of loosely coupled components. A user defines a pipeline using yaml-based (thus human-readable) configuration files, whereas PTP provides generic workers for their loading, training, and testing using all the computational power (CPUs and GPUs) that is available to the user. The paper covers the main concepts of PyTorchPipe, discusses its key features and briefly presents the currently implemented tasks, models and components.
Leveraging Medical Visual Question Answering with Supporting Facts
May 28, 2019
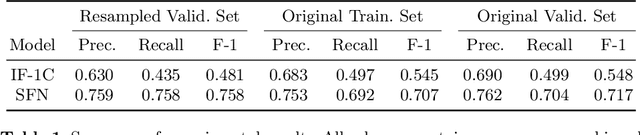
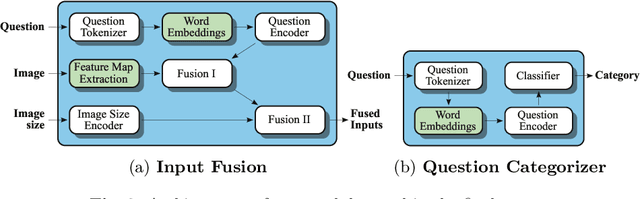
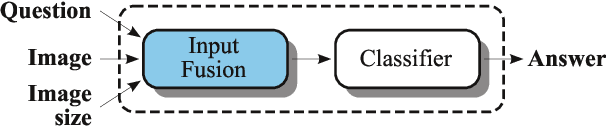
In this working notes paper, we describe IBM Research AI (Almaden) team's participation in the ImageCLEF 2019 VQA-Med competition. The challenge consists of four question-answering tasks based on radiology images. The diversity of imaging modalities, organs and disease types combined with a small imbalanced training set made this a highly complex problem. To overcome these difficulties, we implemented a modular pipeline architecture that utilized transfer learning and multi-task learning. Our findings led to the development of a novel model called Supporting Facts Network (SFN). The main idea behind SFN is to cross-utilize information from upstream tasks to improve the accuracy on harder downstream ones. This approach significantly improved the scores achieved in the validation set (18 point improvement in F-1 score). Finally, we submitted four runs to the competition and were ranked seventh.
On transfer learning using a MAC model variant
Nov 16, 2018
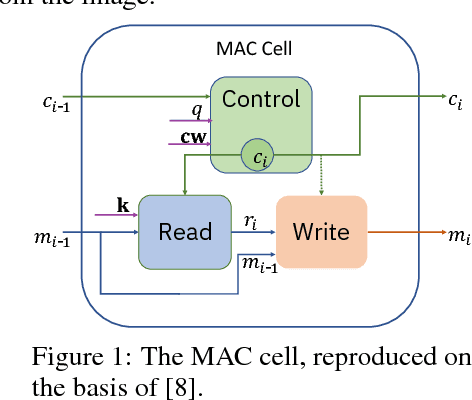
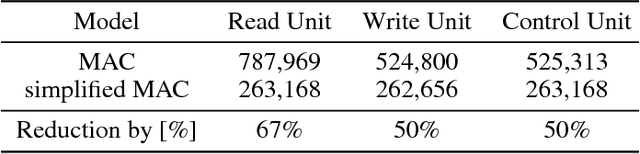

We introduce a variant of the MAC model (Hudson and Manning, ICLR 2018) with a simplified set of equations that achieves comparable accuracy, while training faster. We evaluate both models on CLEVR and CoGenT, and show that, transfer learning with fine-tuning results in a 15 point increase in accuracy, matching the state of the art. Finally, in contrast, we demonstrate that improper fine-tuning can actually reduce a model's accuracy as well.
Learning to Remember, Forget and Ignore using Attention Control in Memory
Sep 28, 2018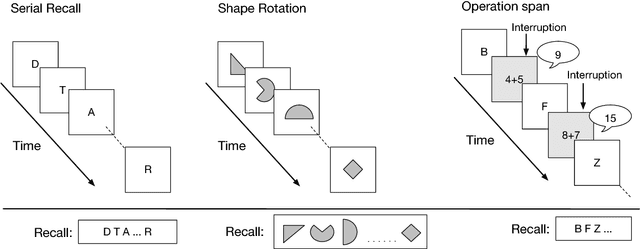


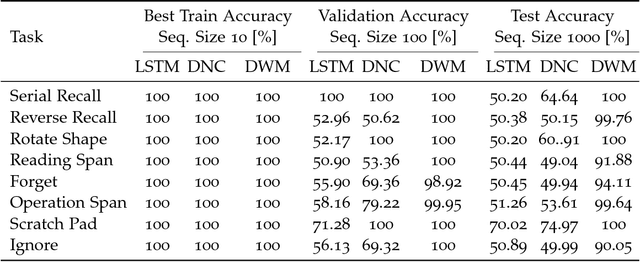
Typical neural networks with external memory do not effectively separate capacity for episodic and working memory as is required for reasoning in humans. Applying knowledge gained from psychological studies, we designed a new model called Differentiable Working Memory (DWM) in order to specifically emulate human working memory. As it shows the same functional characteristics as working memory, it robustly learns psychology inspired tasks and converges faster than comparable state-of-the-art models. Moreover, the DWM model successfully generalizes to sequences two orders of magnitude longer than the ones used in training. Our in-depth analysis shows that the behavior of DWM is interpretable and that it learns to have fine control over memory, allowing it to retain, ignore or forget information based on its relevance.