 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Instance-Specific Data Augmentations
May 31, 2022
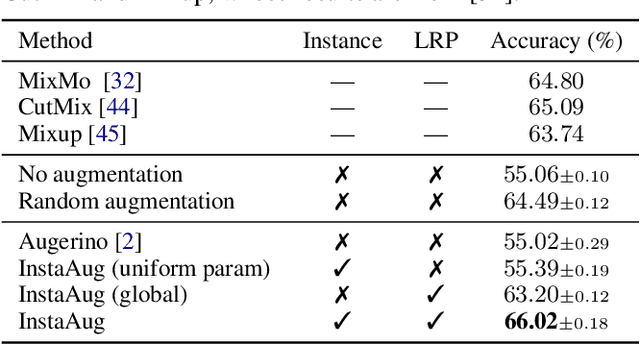
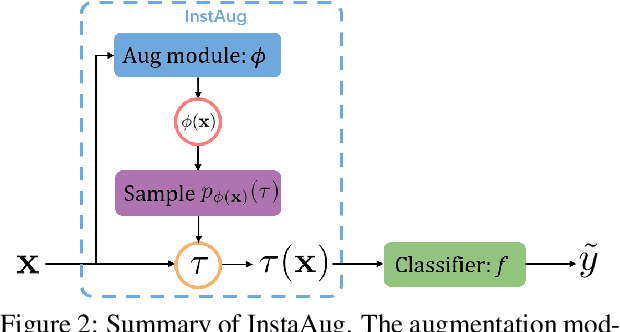
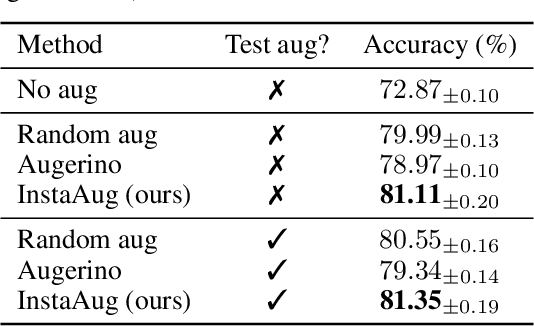
Existing data augmentation methods typically assume independence between transformations and inputs: they use the same transformation distribution for all input instances. We explain why this can be problematic and propose InstaAug, a method for automatically learning input-specific augmentations from data. This is achieved by introducing an augmentation module that maps an input to a distribution over transformations. This is simultaneously trained alongside the base model in a fully end-to-end manner using only the training data. We empirically demonstrate that InstaAug learns meaningful augmentations for a wide range of transformation classes, which in turn provides better performance on supervised and self-supervised tasks compared with augmentations that assume input--transformation independence.
A Continuous Time Framework for Discrete Denoising Models
May 30, 2022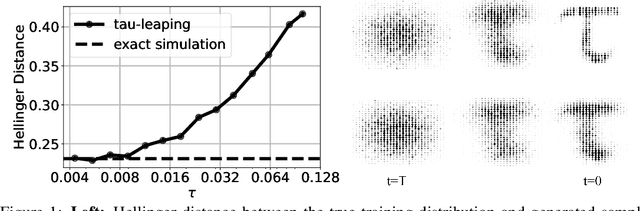
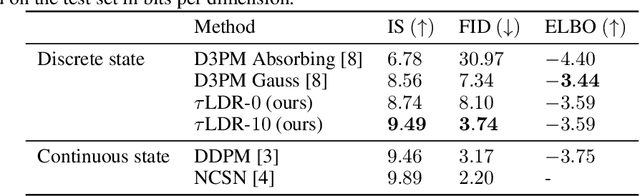


We provide the first complete continuous time framework for denoising diffusion models of discrete data. This is achieved by formulating the forward noising process and corresponding reverse time generative process as Continuous Time Markov Chains (CTMCs). The model can be efficiently trained using a continuous time version of the ELBO. We simulate the high dimensional CTMC using techniques developed in chemical physics and exploit our continuous time framework to derive high performance samplers that we show can outperform discrete time methods for discrete data. The continuous time treatment also enables us to derive a novel theoretical result bounding the error between the generated sample distribution and the true data distribution.
Active Surrogate Estimators: An Active Learning Approach to Label-Efficient Model Evaluation
Feb 14, 2022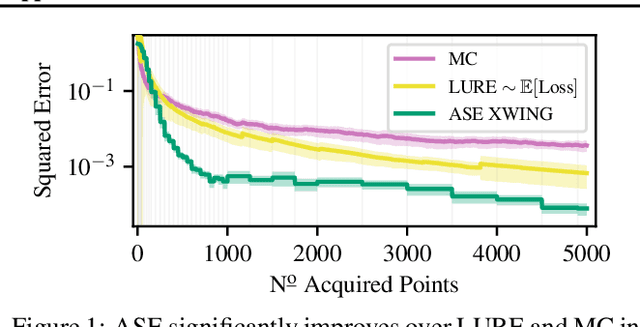
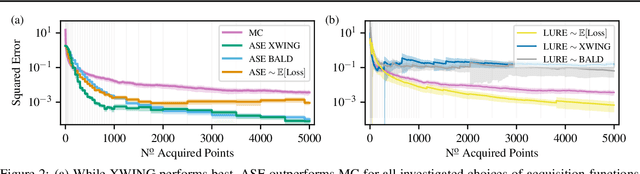
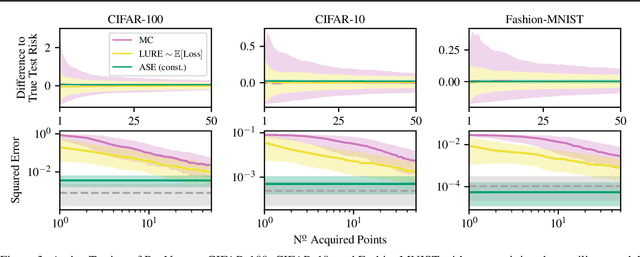
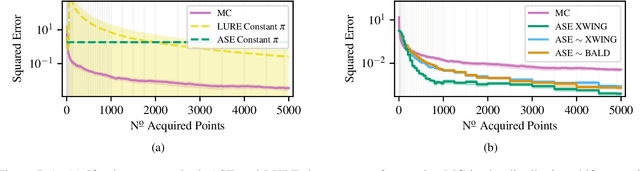
We propose Active Surrogate Estimators (ASEs), a new method for label-efficient model evaluation. Evaluating model performance is a challenging and important problem when labels are expensive. ASEs address this active testing problem using a surrogate-based estimation approach, whereas previous methods have focused on Monte Carlo estimates. ASEs actively learn the underlying surrogate, and we propose a novel acquisition strategy, XWING, that tailors this learning to the final estimation task. We find that ASEs offer greater label-efficiency than the current state-of-the-art when applied to challenging model evaluation problems for deep neural networks. We further theoretically analyze ASEs' errors.
Implicit Deep Adaptive Design: Policy-Based Experimental Design without Likelihoods
Nov 03, 2021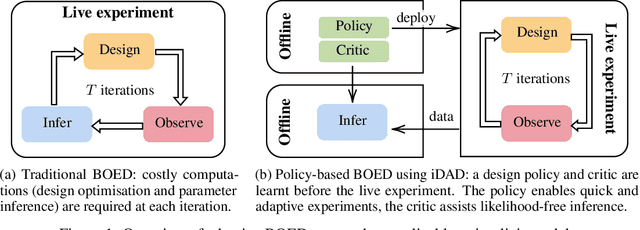
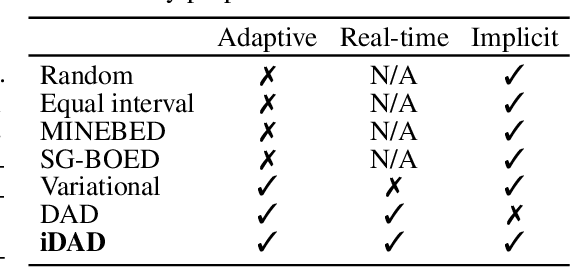
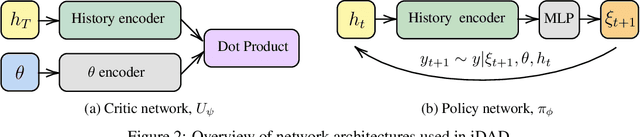
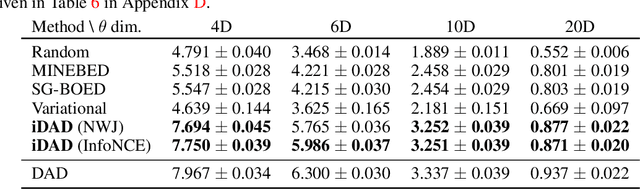
We introduce implicit Deep Adaptive Design (iDAD), a new method for performing adaptive experiments in real-time with implicit models. iDAD amortizes the cost of Bayesian optimal experimental design (BOED) by learning a design policy network upfront, which can then be deployed quickly at the time of the experiment. The iDAD network can be trained on any model which simulates differentiable samples, unlike previous design policy work that requires a closed form likelihood and conditionally independent experiments. At deployment, iDAD allows design decisions to be made in milliseconds, in contrast to traditional BOED approaches that require heavy computation during the experiment itself. We illustrate the applicability of iDAD on a number of experiments, and show that it provides a fast and effective mechanism for performing adaptive design with implicit models.
Online Variational Filtering and Parameter Learning
Oct 26, 2021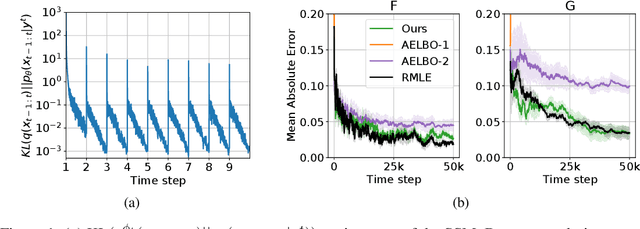
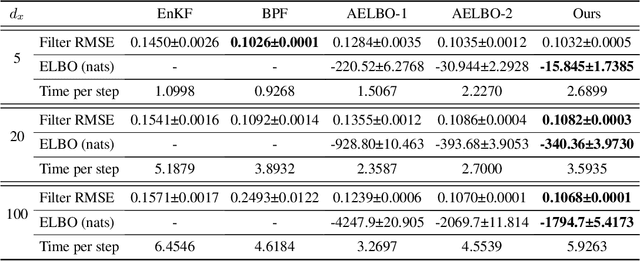
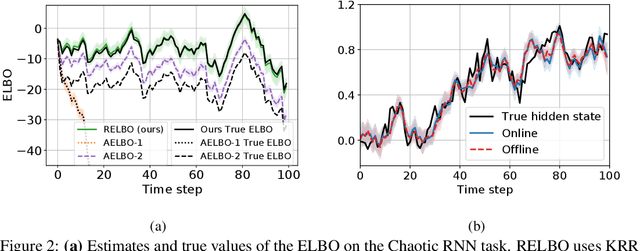

We present a variational method for online state estimation and parameter learning in state-space models (SSMs), a ubiquitous class of latent variable models for sequential data. As per standard batch variational techniques, we use stochastic gradients to simultaneously optimize a lower bound on the log evidence with respect to both model parameters and a variational approximation of the states' posterior distribution. However, unlike existing approaches, our method is able to operate in an entirely online manner, such that historic observations do not require revisitation after being incorporated and the cost of updates at each time step remains constant, despite the growing dimensionality of the joint posterior distribution of the states. This is achieved by utilizing backward decompositions of this joint posterior distribution and of its variational approximation, combined with Bellman-type recursions for the evidence lower bound and its gradients. We demonstrate the performance of this methodology across several examples, including high-dimensional SSMs and sequential Variational Auto-Encoders.
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021


Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
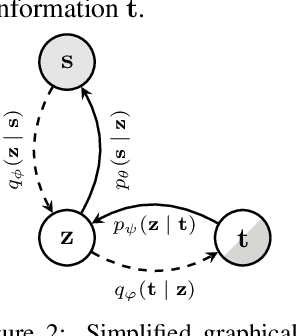
InteL-VAEs: Adding Inductive Biases to Variational Auto-Encoders via Intermediary Latents
Jun 25, 2021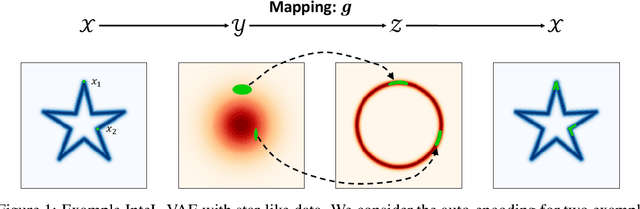


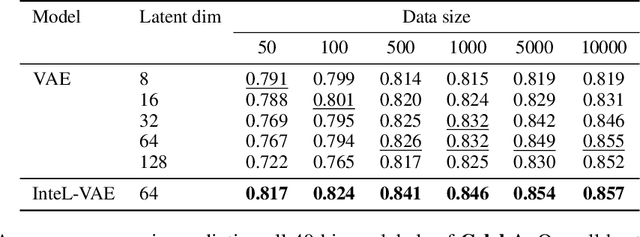
We introduce a simple and effective method for learning VAEs with controllable inductive biases by using an intermediary set of latent variables. This allows us to overcome the limitations of the standard Gaussian prior assumption. In particular, it allows us to impose desired properties like sparsity or clustering on learned representations, and incorporate prior information into the learned model. Our approach, which we refer to as the Intermediary Latent Space VAE (InteL-VAE), is based around controlling the stochasticity of the encoding process with the intermediary latent variables, before deterministically mapping them forward to our target latent representation, from which reconstruction is performed. This allows us to maintain all the advantages of the traditional VAE framework, while incorporating desired prior information, inductive biases, and even topological information through the latent mapping. We show that this, in turn, allows InteL-VAEs to learn both better generative models and representations.
Active Learning under Pool Set Distribution Shift and Noisy Data
Jun 22, 2021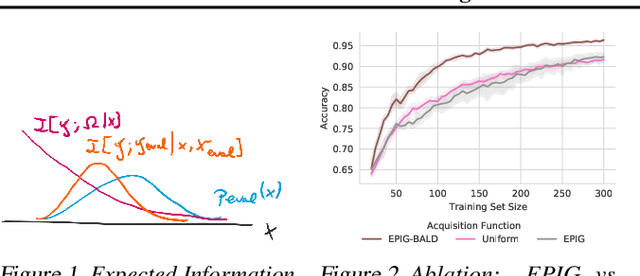
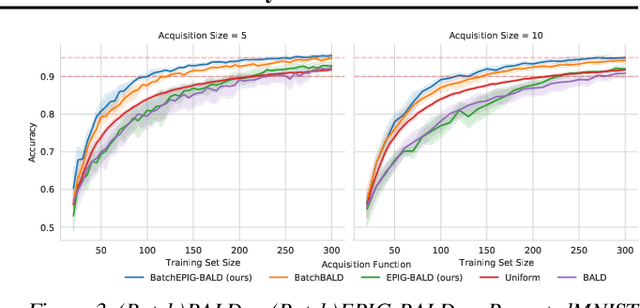
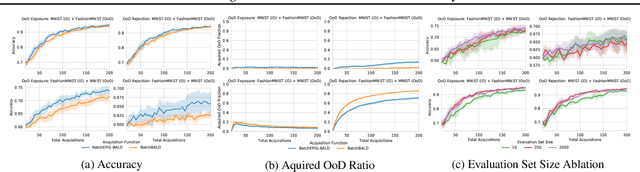
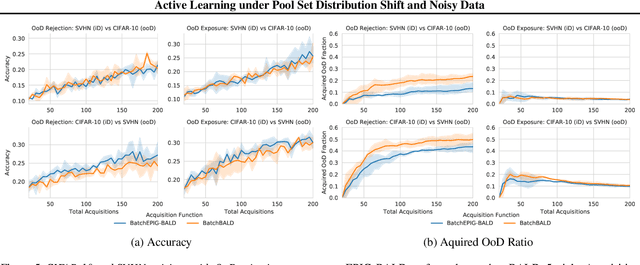
Active Learning is essential for more label-efficient deep learning. Bayesian Active Learning has focused on BALD, which reduces model parameter uncertainty. However, we show that BALD gets stuck on out-of-distribution or junk data that is not relevant for the task. We examine a novel *Expected Predictive Information Gain (EPIG)* to deal with distribution shifts of the pool set. EPIG reduces the uncertainty of *predictions* on an unlabelled *evaluation set* sampled from the test data distribution whose distribution might be different to the pool set distribution. Based on this, our new EPIG-BALD acquisition function for Bayesian Neural Networks selects samples to improve the performance on the test data distribution instead of selecting samples that reduce model uncertainty everywhere, including for out-of-distribution regions with low density in the test data distribution. Our method outperforms state-of-the-art Bayesian active learning methods on high-dimensional datasets and avoids out-of-distribution junk data in cases where current state-of-the-art methods fail.
Group Equivariant Subsampling
Jun 10, 2021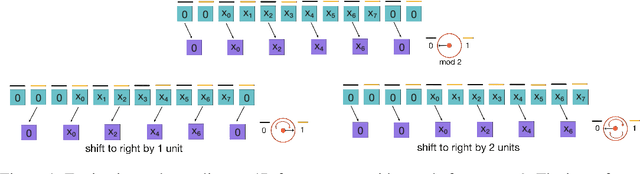

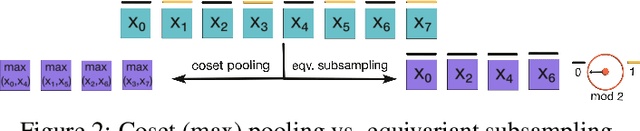
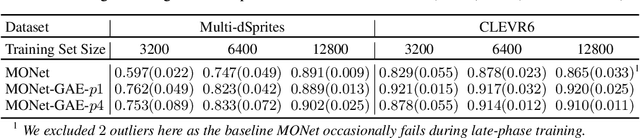
Subsampling is used in convolutional neural networks (CNNs) in the form of pooling or strided convolutions, to reduce the spatial dimensions of feature maps and to allow the receptive fields to grow exponentially with depth. However, it is known that such subsampling operations are not translation equivariant, unlike convolutions that are translation equivariant. Here, we first introduce translation equivariant subsampling/upsampling layers that can be used to construct exact translation equivariant CNNs. We then generalise these layers beyond translations to general groups, thus proposing group equivariant subsampling/upsampling. We use these layers to construct group equivariant autoencoders (GAEs) that allow us to learn low-dimensional equivariant representations. We empirically verify on images that the representations are indeed equivariant to input translations and rotations, and thus generalise well to unseen positions and orientations. We further use GAEs in models that learn object-centric representations on multi-object datasets, and show improved data efficiency and decomposition compared to non-equivariant baselines.
Expectation Programming
Jun 09, 2021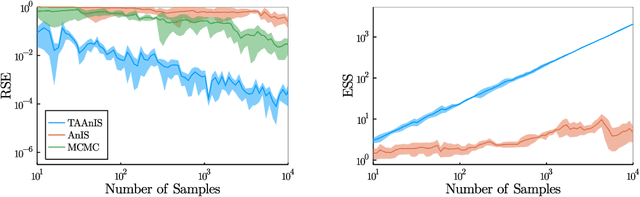
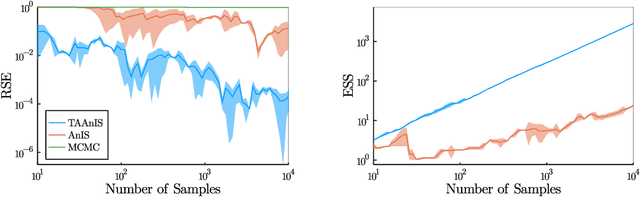
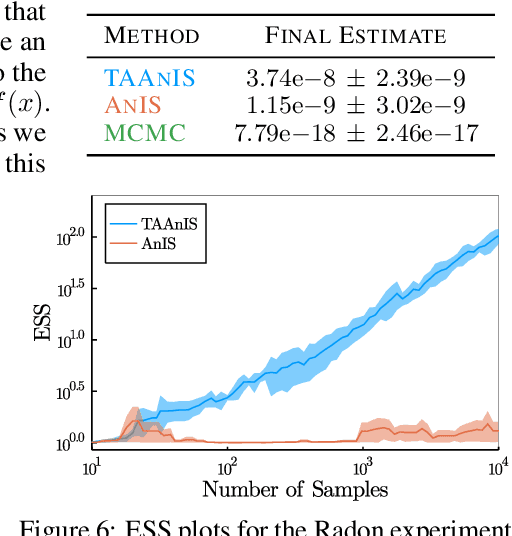
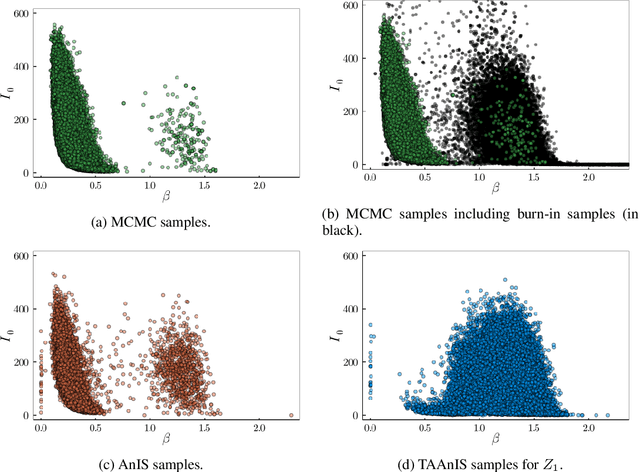
Building on ideas from probabilistic programming, we introduce the concept of an expectation programming framework (EPF) that automates the calculation of expectations. Analogous to a probabilistic program, an expectation program is comprised of a mix of probabilistic constructs and deterministic calculations that define a conditional distribution over its variables. However, the focus of the inference engine in an EPF is to directly estimate the resulting expectation of the program return values, rather than approximate the conditional distribution itself. This distinction allows us to achieve substantial performance improvements over the standard probabilistic programming pipeline by tailoring the inference to the precise expectation we care about. We realize a particular instantiation of our EPF concept by extending the probabilistic programming language Turing to allow so-called target-aware inference to be run automatically, and show that this leads to significant empirical gains compared to conventional posterior-based inference.