 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummaC: Re-Visiting NLI-based Models for Inconsistency Detection in Summarization
Nov 18, 2021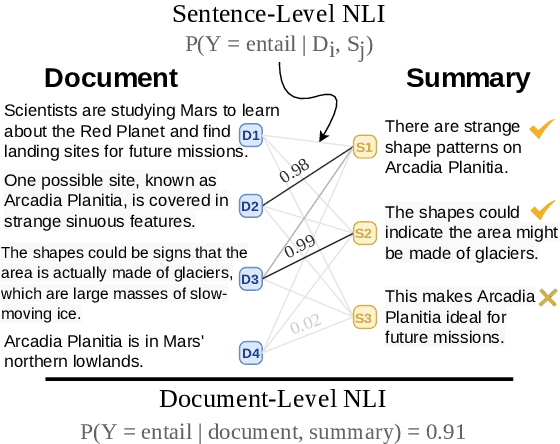
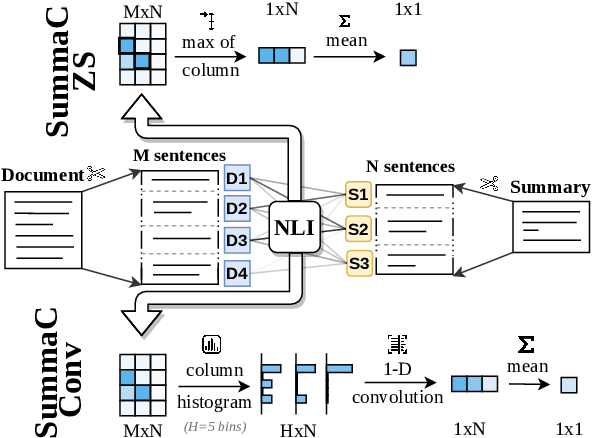
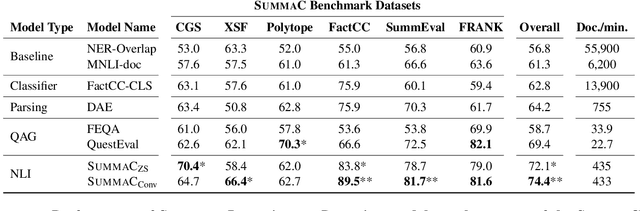
In the summarization domain, a key requirement for summaries is to be factually consistent with the input document. Previous work has found that natural language inference (NLI) models do not perform competitively when applied to inconsistency detection. In this work, we revisit the use of NLI for inconsistency detection, finding that past work suffered from a mismatch in input granularity between NLI datasets (sentence-level), and inconsistency detection (document level). We provide a highly effective and light-weight method called SummaCConv that enables NLI models to be successfully used for this task by segmenting documents into sentence units and aggregating scores between pairs of sentences. On our newly introduced benchmark called SummaC (Summary Consistency) consisting of six large inconsistency detection datasets, SummaCConv obtains state-of-the-art results with a balanced accuracy of 74.4%, a 5% point improvement compared to prior work. We make the models and datasets available: https://github.com/tingofurro/summac
Keep it Simple: Unsupervised Simplification of Multi-Paragraph Text
Jul 07, 2021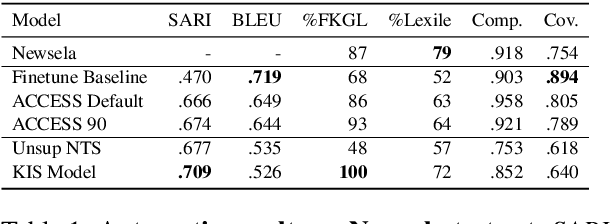
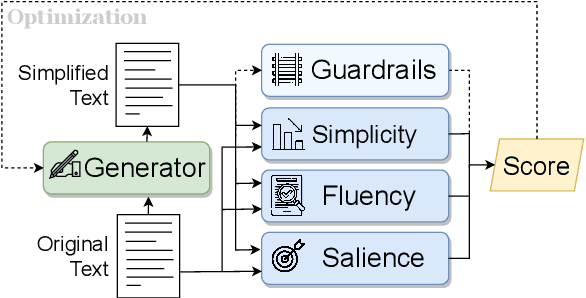
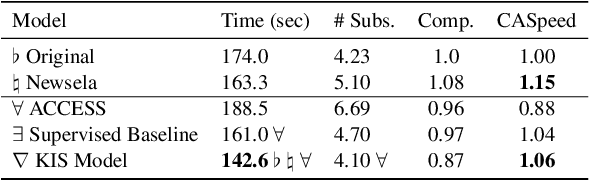

This work presents Keep it Simple (KiS), a new approach to unsupervised text simplification which learns to balance a reward across three properties: fluency, salience and simplicity. We train the model with a novel algorithm to optimize the reward (k-SCST), in which the model proposes several candidate simplifications, computes each candidate's reward, and encourages candidates that outperform the mean reward. Finally, we propose a realistic text comprehension task as an evaluation method for text simplification. When tested on the English news domain, the KiS model outperforms strong supervised baselines by more than 4 SARI points, and can help people complete a comprehension task an average of 18% faster while retaining accuracy, when compared to the original text. Code available: https://github.com/tingofurro/keep_it_simple
* Accepted at ACL-IJCNLP 2021, 14 pages, 7 figures
Deep Generalized Method of Moments for Instrumental Variable Analysis
May 29, 2019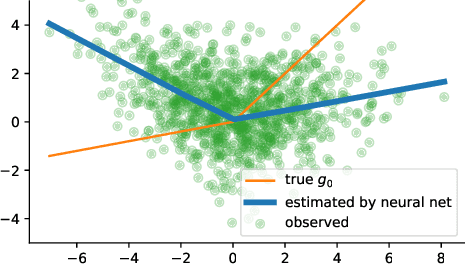
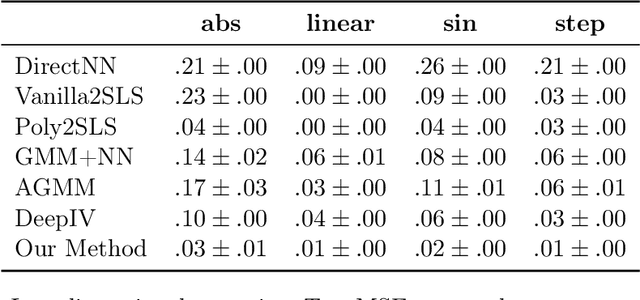
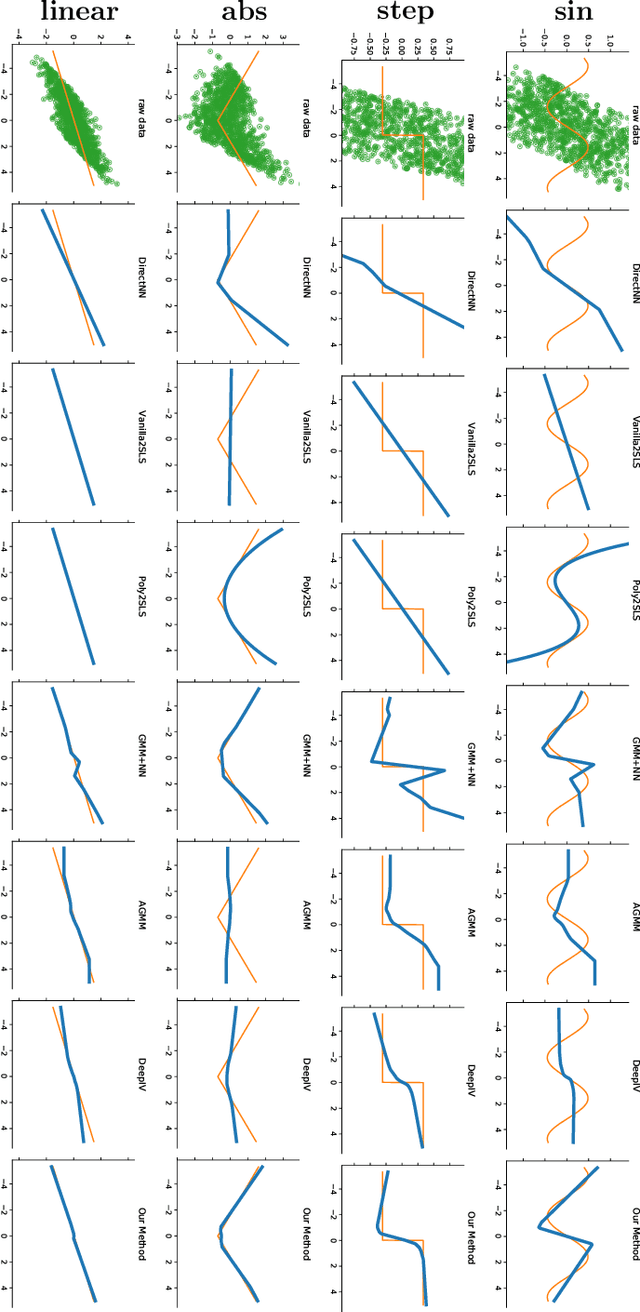

Instrumental variable analysis is a powerful tool for estimating causal effects when randomization or full control of confounders is not possible. The application of standard methods such as 2SLS, GMM, and more recent variants are significantly impeded when the causal effects are complex, the instruments are high-dimensional, and/or the treatment is high-dimensional. In this paper, we propose the DeepGMM algorithm to overcome this. Our algorithm is based on a new variational reformulation of GMM with optimal inverse-covariance weighting that allows us to efficiently control very many moment conditions. We further develop practical techniques for optimization and model selection that make it particularly successful in practice. Our algorithm is also computationally tractable and can handle large-scale datasets. Numerical results show our algorithm matches the performance of the best tuned methods in standard settings and continues to work in high-dimensional settings where even recent methods break.
Effective Evaluation using Logged Bandit Feedback from Multiple Loggers
Jun 26, 2017
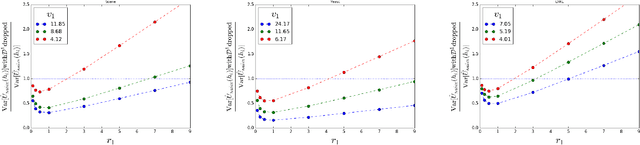
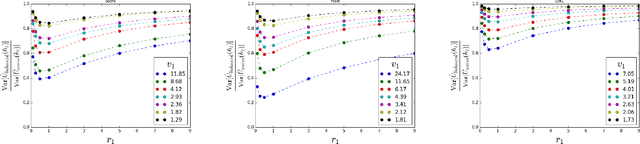
Accurately evaluating new policies (e.g. ad-placement models, ranking functions, recommendation functions) is one of the key prerequisites for improving interactive systems. While the conventional approach to evaluation relies on online A/B tests, recent work has shown that counterfactual estimators can provide an inexpensive and fast alternative, since they can be applied offline using log data that was collected from a different policy fielded in the past. In this paper, we address the question of how to estimate the performance of a new target policy when we have log data from multiple historic policies. This question is of great relevance in practice, since policies get updated frequently in most online systems. We show that naively combining data from multiple logging policies can be highly suboptimal. In particular, we find that the standard Inverse Propensity Score (IPS) estimator suffers especially when logging and target policies diverge -- to a point where throwing away data improves the variance of the estimator. We therefore propose two alternative estimators which we characterize theoretically and compare experimentally. We find that the new estimators can provide substantially improved estimation accuracy.
Unbiased Learning-to-Rank with Biased Feedback
Aug 16, 2016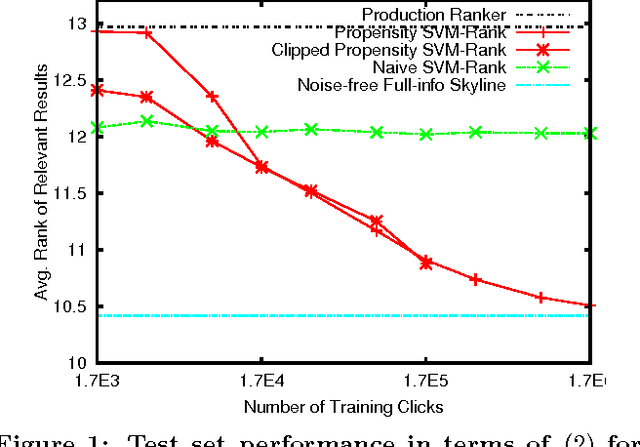
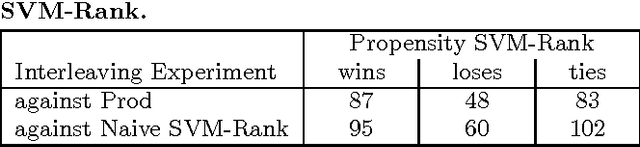
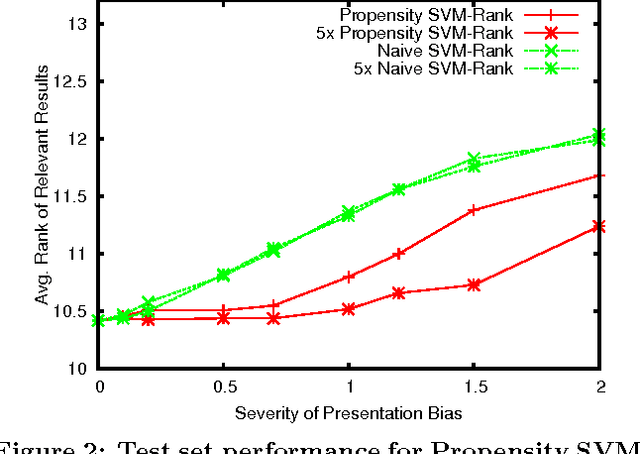
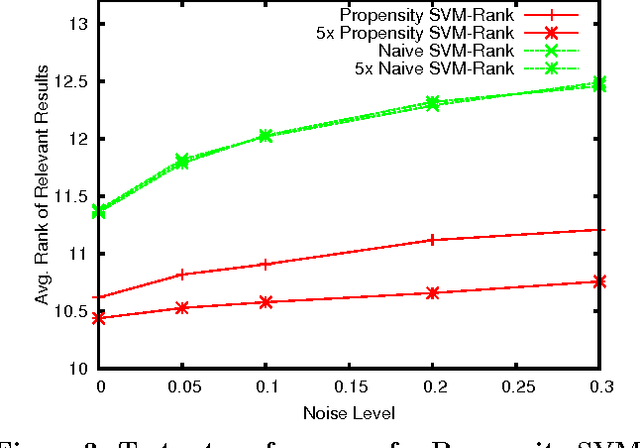
Implicit feedback (e.g., clicks, dwell times, etc.) is an abundant source of data in human-interactive systems. While implicit feedback has many advantages (e.g., it is inexpensive to collect, user centric, and timely), its inherent biases are a key obstacle to its effective use. For example, position bias in search rankings strongly influences how many clicks a result receives, so that directly using click data as a training signal in Learning-to-Rank (LTR) methods yields sub-optimal results. To overcome this bias problem, we present a counterfactual inference framework that provides the theoretical basis for unbiased LTR via Empirical Risk Minimization despite biased data. Using this framework, we derive a Propensity-Weighted Ranking SVM for discriminative learning from implicit feedback, where click models take the role of the propensity estimator. In contrast to most conventional approaches to de-bias the data using click models, this allows training of ranking functions even in settings where queries do not repeat. Beyond the theoretical support, we show empirically that the proposed learning method is highly effective in dealing with biases, that it is robust to noise and propensity model misspecification, and that it scales efficiently. We also demonstrate the real-world applicability of our approach on an operational search engine, where it substantially improves retrieval performance.
Recommendations as Treatments: Debiasing Learning and Evaluation
May 27, 2016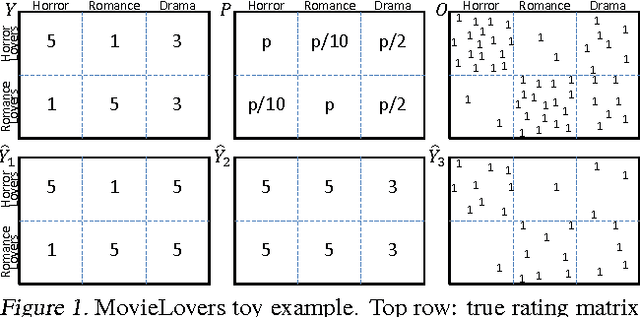
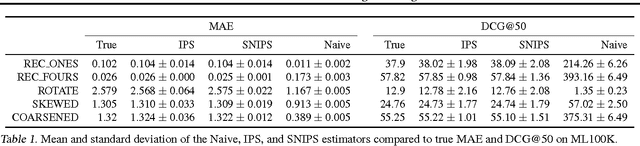
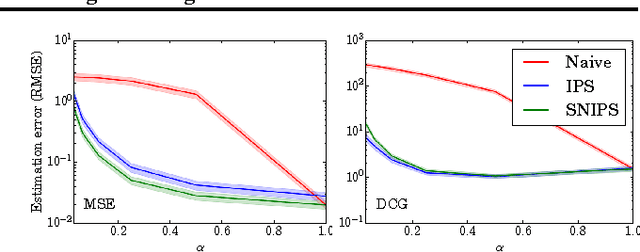
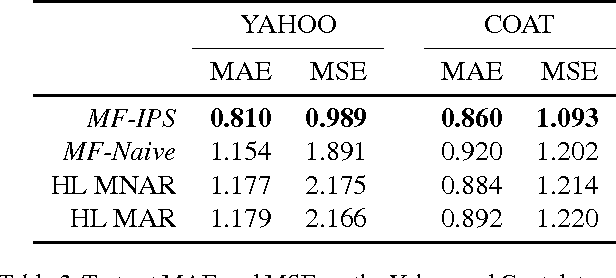
Most data for evaluating and training recommender systems is subject to selection biases, either through self-selection by the users or through the actions of the recommendation system itself. In this paper, we provide a principled approach to handling selection biases, adapting models and estimation techniques from causal inference. The approach leads to unbiased performance estimators despite biased data, and to a matrix factorization method that provides substantially improved prediction performance on real-world data. We theoretically and empirically characterize the robustness of the approach, finding that it is highly practical and scalable.
Unbiased Comparative Evaluation of Ranking Functions
Apr 25, 2016
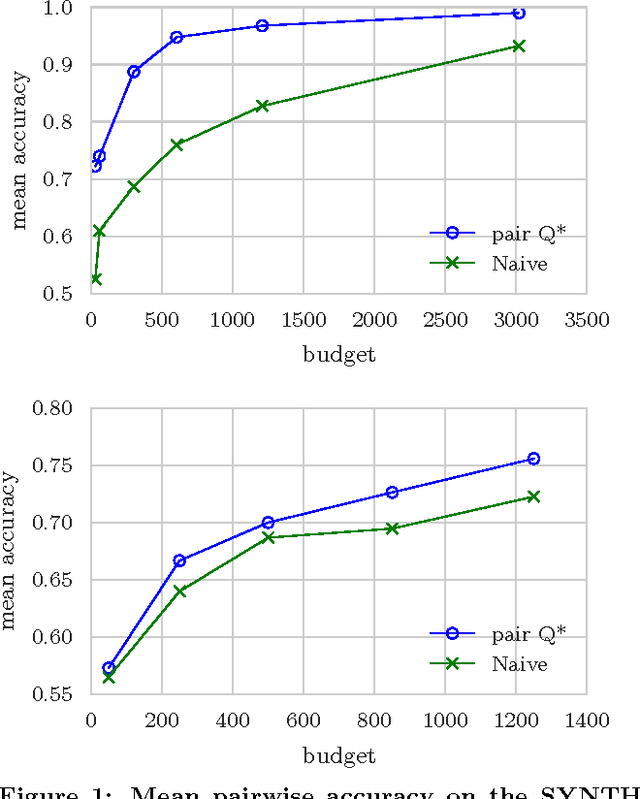
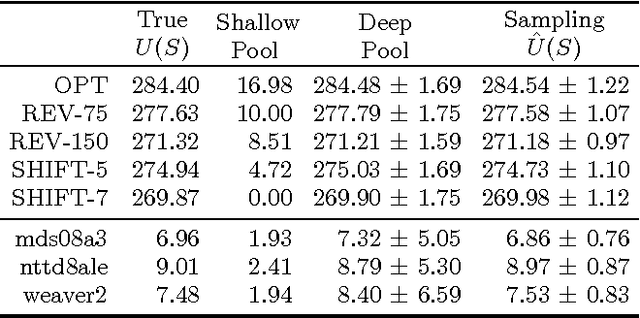
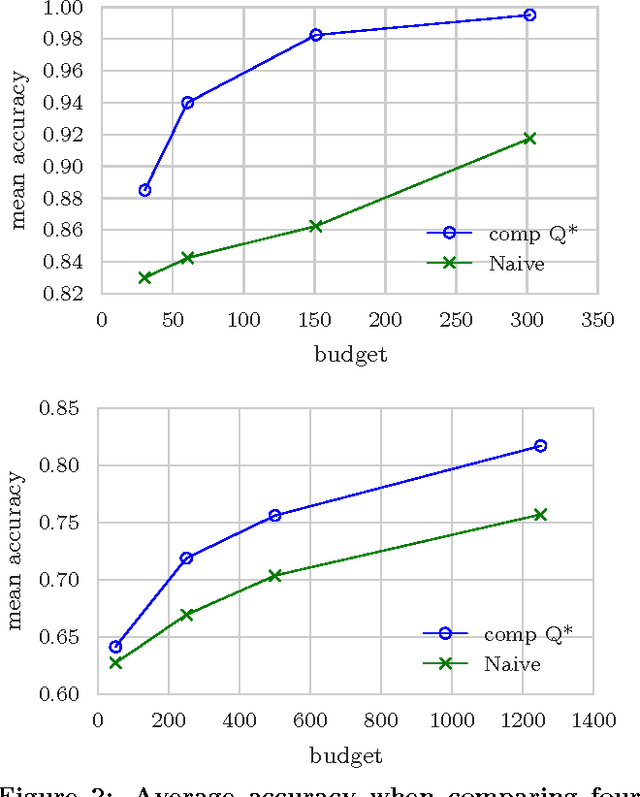
Eliciting relevance judgments for ranking evaluation is labor-intensive and costly, motivating careful selection of which documents to judge. Unlike traditional approaches that make this selection deterministically, probabilistic sampling has shown intriguing promise since it enables the design of estimators that are provably unbiased even when reusing data with missing judgments. In this paper, we first unify and extend these sampling approaches by viewing the evaluation problem as a Monte Carlo estimation task that applies to a large number of common IR metrics. Drawing on the theoretical clarity that this view offers, we tackle three practical evaluation scenarios: comparing two systems, comparing $k$ systems against a baseline, and ranking $k$ systems. For each scenario, we derive an estimator and a variance-optimizing sampling distribution while retaining the strengths of sampling-based evaluation, including unbiasedness, reusability despite missing data, and ease of use in practice. In addition to the theoretical contribution, we empirically evaluate our methods against previously used sampling heuristics and find that they generally cut the number of required relevance judgments at least in half.
Online Updating of Word Representations for Part-of-Speech Tagging
Apr 02, 2016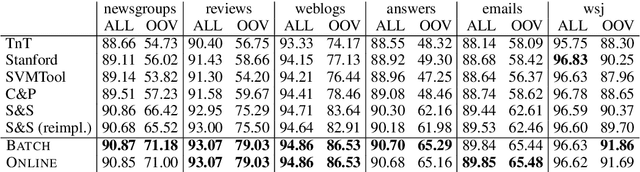
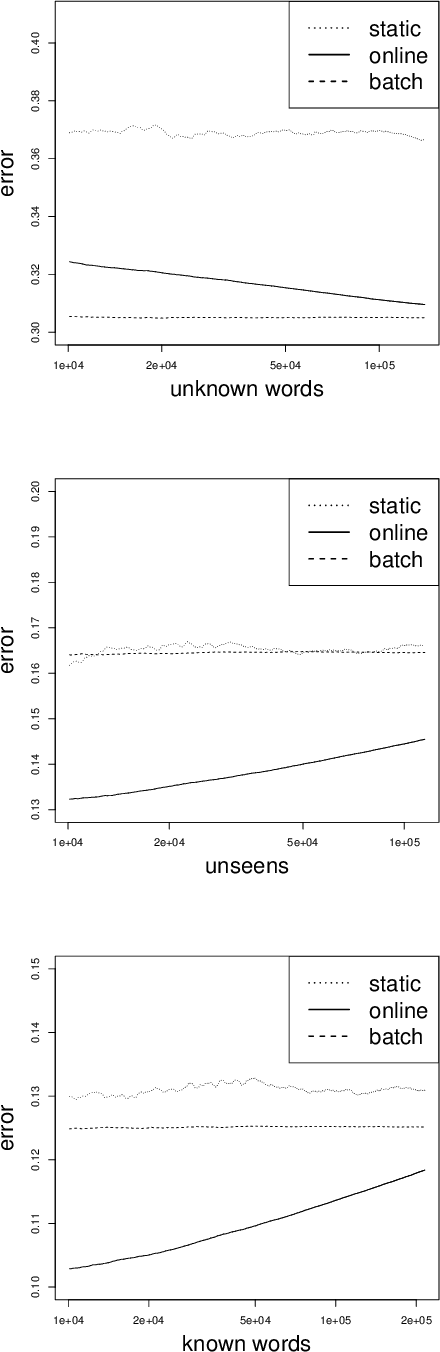
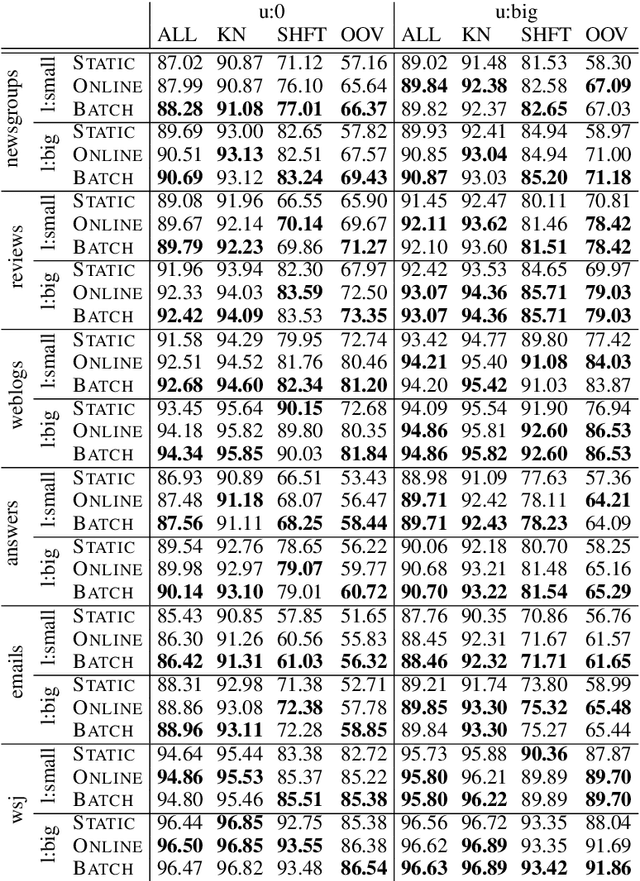
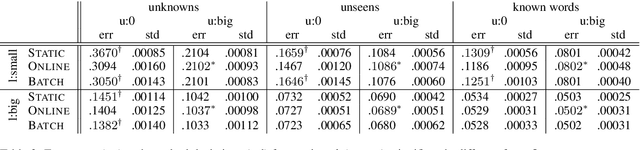
We propose online unsupervised domain adaptation (DA), which is performed incrementally as data comes in and is applicable when batch DA is not possible. In a part-of-speech (POS) tagging evaluation, we find that online unsupervised DA performs as well as batch DA.
Using Shortlists to Support Decision Making and Improve Recommender System Performance
Feb 08, 2016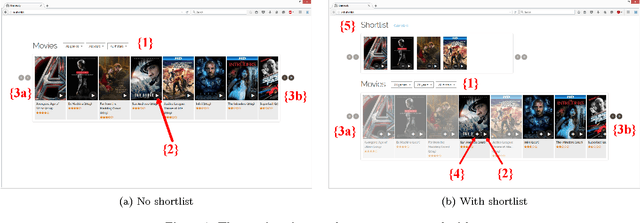

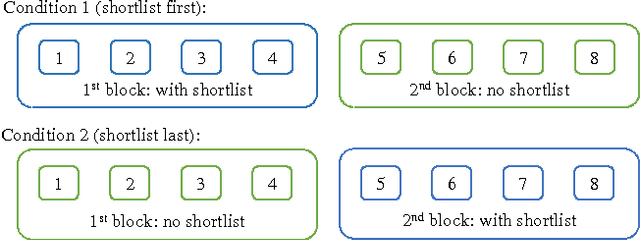
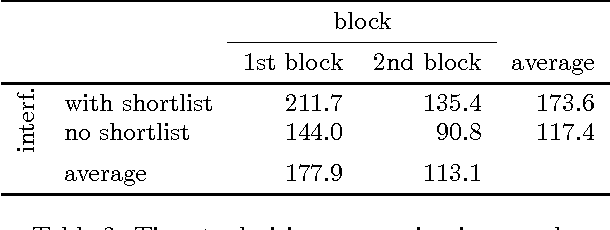
In this paper, we study shortlists as an interface component for recommender systems with the dual goal of supporting the user's decision process, as well as improving implicit feedback elicitation for increased recommendation quality. A shortlist is a temporary list of candidates that the user is currently considering, e.g., a list of a few movies the user is currently considering for viewing. From a cognitive perspective, shortlists serve as digital short-term memory where users can off-load the items under consideration -- thereby decreasing their cognitive load. From a machine learning perspective, adding items to the shortlist generates a new implicit feedback signal as a by-product of exploration and decision making which can improve recommendation quality. Shortlisting therefore provides additional data for training recommendation systems without the increases in cognitive load that requesting explicit feedback would incur. We perform an user study with a movie recommendation setup to compare interfaces that offer shortlist support with those that do not. From the user studies we conclude: (i) users make better decisions with a shortlist; (ii) users prefer an interface with shortlist support; and (iii) the additional implicit feedback from sessions with a shortlist improves the quality of recommendations by nearly a factor of two.
Towards a Better Understanding of Predict and Count Models
Nov 06, 2015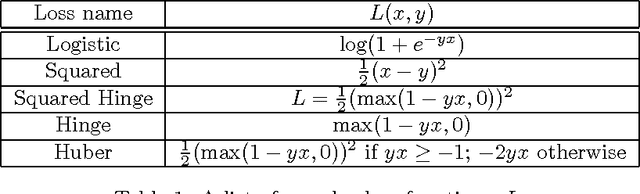

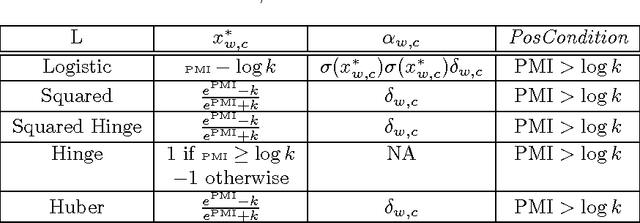
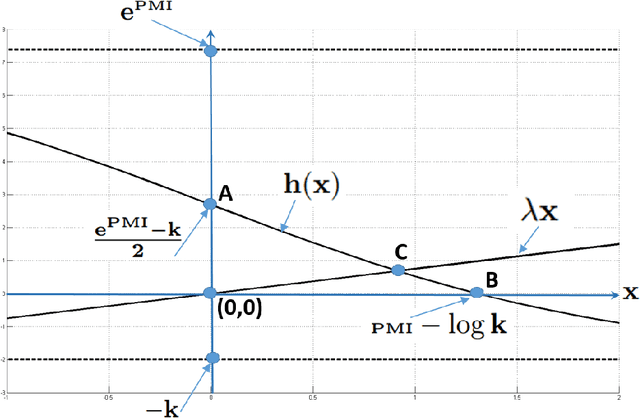
In a recent paper, Levy and Goldberg pointed out an interesting connection between prediction-based word embedding models and count models based on pointwise mutual information. Under certain conditions, they showed that both models end up optimizing equivalent objective functions. This paper explores this connection in more detail and lays out the factors leading to differences between these models. We find that the most relevant differences from an optimization perspective are (i) predict models work in a low dimensional space where embedding vectors can interact heavily; (ii) since predict models have fewer parameters, they are less prone to overfitting. Motivated by the insight of our analysis, we show how count models can be regularized in a principled manner and provide closed-form solutions for L1 and L2 regularization. Finally, we propose a new embedding model with a convex objective and the additional benefit of being intelligible.