 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Aware Weight Initialization for Point Convolutional Neural Networks
Dec 07, 2021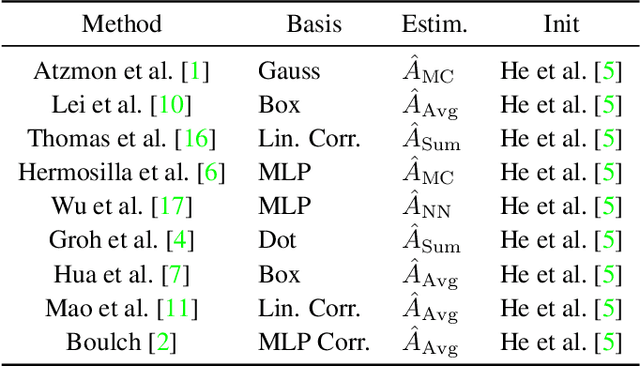
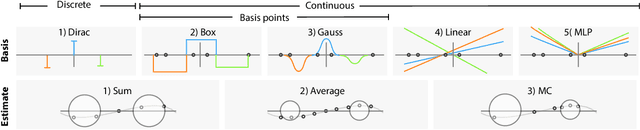
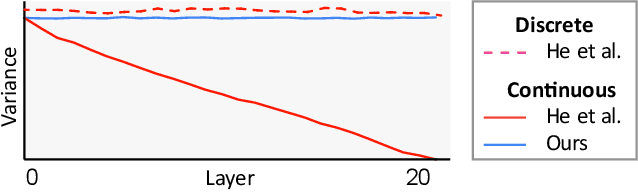
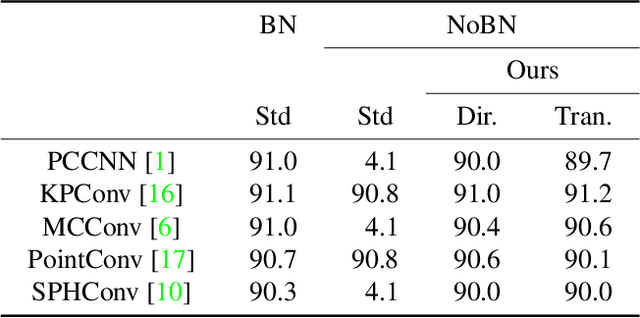
Appropriate weight initialization has been of key importance to successfully train neural networks. Recently, batch normalization has diminished the role of weight initialization by simply normalizing each layer based on batch statistics. Unfortunately, batch normalization has several drawbacks when applied to small batch sizes, as they are required to cope with memory limitations when learning on point clouds. While well-founded weight initialization strategies can render batch normalization unnecessary and thus avoid these drawbacks, no such approaches have been proposed for point convolutional networks. To fill this gap, we propose a framework to unify the multitude of continuous convolutions. This enables our main contribution, variance-aware weight initialization. We show that this initialization can avoid batch normalization while achieving similar and, in some cases, better performance.
Data-driven deep density estimation
Jul 23, 2021
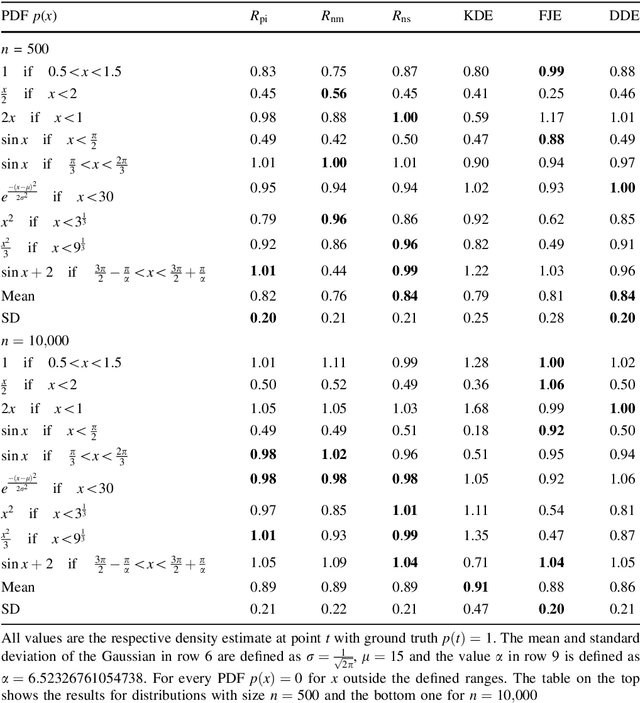
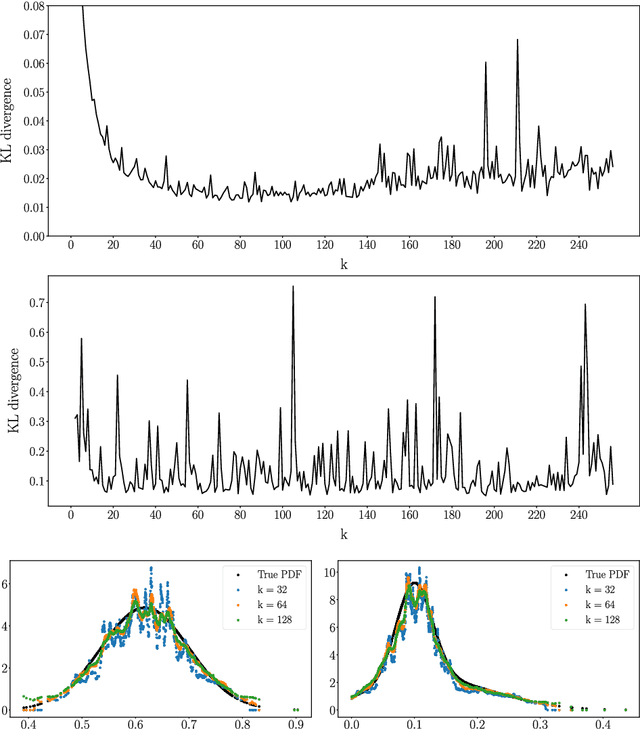

Density estimation plays a crucial role in many data analysis tasks, as it infers a continuous probability density function (PDF) from discrete samples. Thus, it is used in tasks as diverse as analyzing population data, spatial locations in 2D sensor readings, or reconstructing scenes from 3D scans. In this paper, we introduce a learned, data-driven deep density estimation (DDE) to infer PDFs in an accurate and efficient manner, while being independent of domain dimensionality or sample size. Furthermore, we do not require access to the original PDF during estimation, neither in parametric form, nor as priors, or in the form of many samples. This is enabled by training an unstructured convolutional neural network on an infinite stream of synthetic PDFs, as unbound amounts of synthetic training data generalize better across a deck of natural PDFs than any natural finite training data will do. Thus, we hope that our publicly available DDE method will be beneficial in many areas of data analysis, where continuous models are to be estimated from discrete observations.
Unsupervised Learning of 3D Object Categories from Videos in the Wild
Mar 30, 2021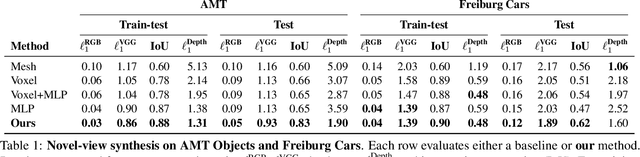
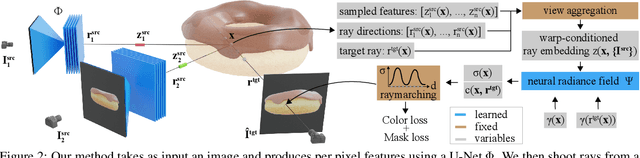
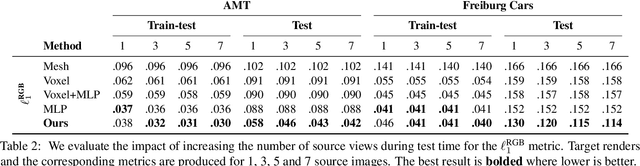
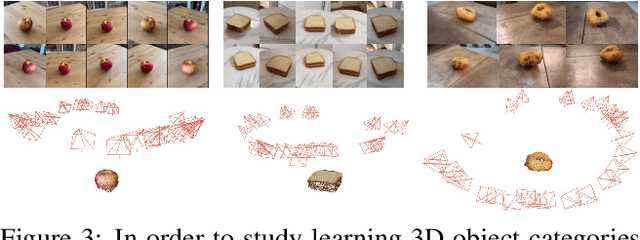
Our goal is to learn a deep network that, given a small number of images of an object of a given category, reconstructs it in 3D. While several recent works have obtained analogous results using synthetic data or assuming the availability of 2D primitives such as keypoints, we are interested in working with challenging real data and with no manual annotations. We thus focus on learning a model from multiple views of a large collection of object instances. We contribute with a new large dataset of object centric videos suitable for training and benchmarking this class of models. We show that existing techniques leveraging meshes, voxels, or implicit surfaces, which work well for reconstructing isolated objects, fail on this challenging data. Finally, we propose a new neural network design, called warp-conditioned ray embedding (WCR), which significantly improves reconstruction while obtaining a detailed implicit representation of the object surface and texture, also compensating for the noise in the initial SfM reconstruction that bootstrapped the learning process. Our evaluation demonstrates performance improvements over several deep monocular reconstruction baselines on existing benchmarks and on our novel dataset.
Generative Modelling of BRDF Textures from Flash Images
Feb 23, 2021
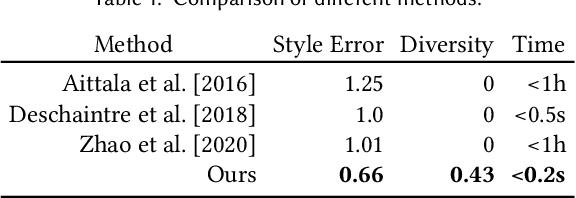
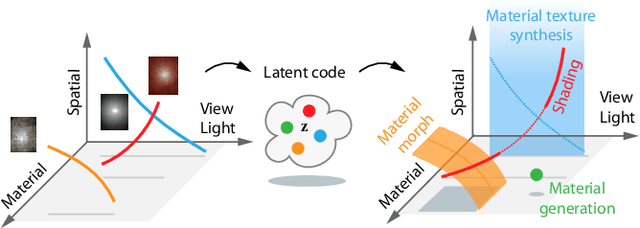
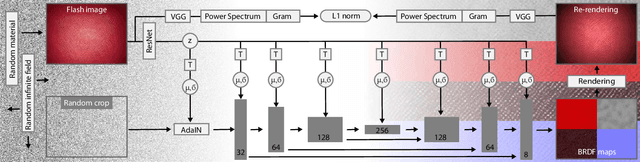
We learn a latent space for easy capture, semantic editing, consistent interpolation, and efficient reproduction of visual material appearance. When users provide a photo of a stationary natural material captured under flash light illumination, it is converted in milliseconds into a latent material code. In a second step, conditioned on the material code, our method, again in milliseconds, produces an infinite and diverse spatial field of BRDF model parameters (diffuse albedo, specular albedo, roughness, normals) that allows rendering in complex scenes and illuminations, matching the appearance of the input picture. Technically, we jointly embed all flash images into a latent space using a convolutional encoder, and -- conditioned on these latent codes -- convert random spatial fields into fields of BRDF parameters using a convolutional neural network (CNN). We condition these BRDF parameters to match the visual characteristics (statistics and spectra of visual features) of the input under matching light. A user study confirms that the semantics of the latent material space agree with user expectations and compares our approach favorably to previous work.
Neural BRDF Representation and Importance Sampling
Feb 12, 2021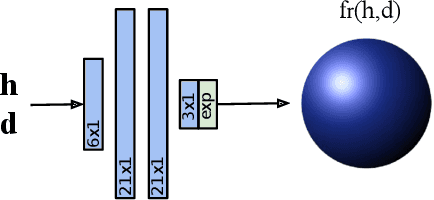



Controlled capture of real-world material appearance yields tabulated sets of highly realistic reflectance data. In practice, however, its high memory footprint requires compressing into a representation that can be used efficiently in rendering while remaining faithful to the original. Previous works in appearance encoding often prioritised one of these requirements at the expense of the other, by either applying high-fidelity array compression strategies not suited for efficient queries during rendering, or by fitting a compact analytic model that lacks expressiveness. We present a compact neural network-based representation of BRDF data that combines high-accuracy reconstruction with efficient practical rendering via built-in interpolation of reflectance. We encode BRDFs as lightweight networks, and propose a training scheme with adaptive angular sampling, critical for the accurate reconstruction of specular highlights. Additionally, we propose a novel approach to make our representation amenable to importance sampling: rather than inverting the trained networks, we learn an embedding that can be mapped to parameters of an analytic BRDF for which importance sampling is known. We evaluate encoding results on isotropic and anisotropic BRDFs from multiple real-world datasets, and importance sampling performance for isotropic BRDFs mapped to two different analytic models.
HDR Denoising and Deblurring by Learning Spatio-temporal Distortion Models
Dec 23, 2020
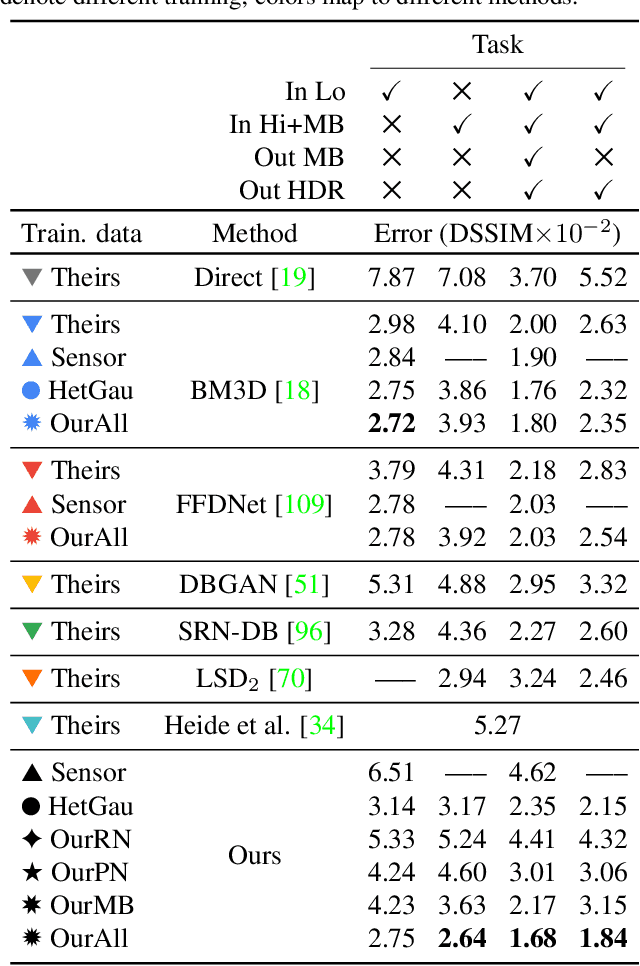
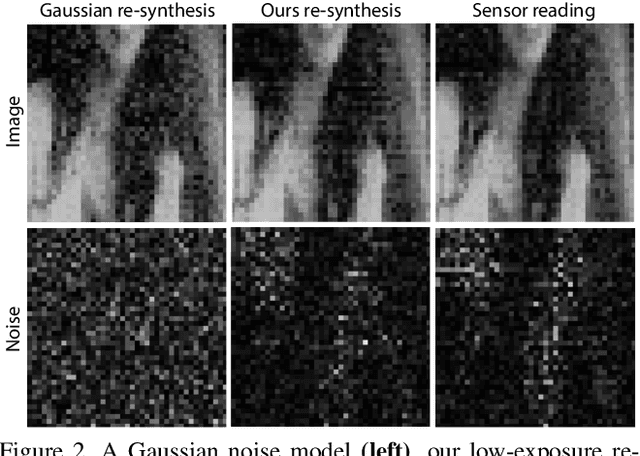
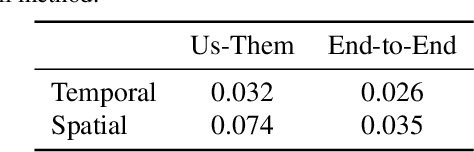
We seek to reconstruct sharp and noise-free high-dynamic range (HDR) video from a dual-exposure sensor that records different low-dynamic range (LDR) information in different pixel columns: Odd columns provide low-exposure, sharp, but noisy information; even columns complement this with less noisy, high-exposure, but motion-blurred data. Previous LDR work learns to deblur and denoise (DISTORTED->CLEAN) supervised by pairs of CLEAN and DISTORTED images. Regrettably, capturing DISTORTED sensor readings is time-consuming; as well, there is a lack of CLEAN HDR videos. We suggest a method to overcome those two limitations. First, we learn a different function instead: CLEAN->DISTORTED, which generates samples containing correlated pixel noise, and row and column noise, as well as motion blur from a low number of CLEAN sensor readings. Second, as there is not enough CLEAN HDR video available, we devise a method to learn from LDR video in-stead. Our approach compares favorably to several strong baselines, and can boost existing methods when they are re-trained on our data. Combined with spatial and temporal super-resolution, it enables applications such as re-lighting with low noise or blur.
Curiosity-driven 3D Scene Structure from Single-image Self-supervision
Dec 02, 2020
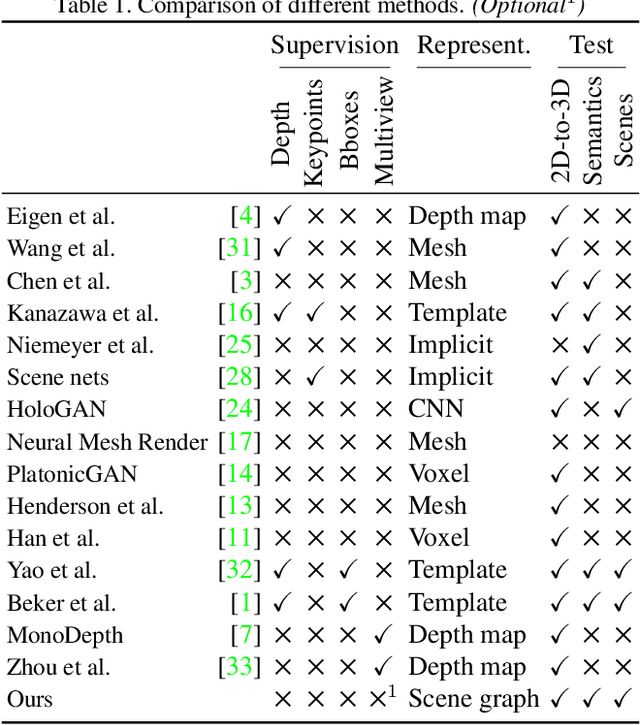
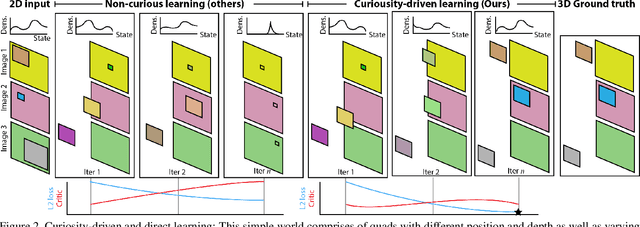
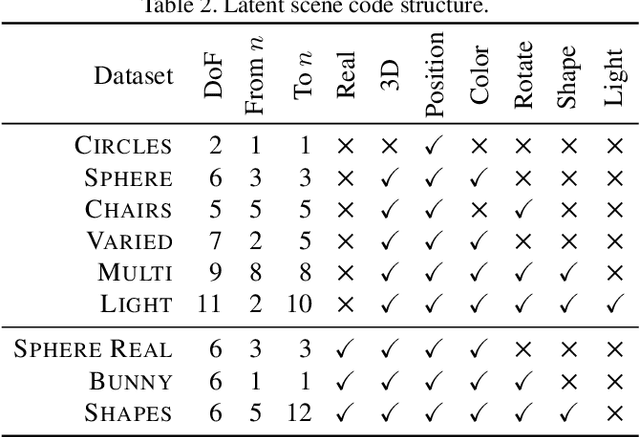
Previous work has demonstrated learning isolated 3D objects (voxel grids, point clouds, meshes, etc.) from 2D-only self-supervision. We here set out to extend this to entire 3D scenes made out of multiple objects, including their location, orientation and type, and the scenes illumination. Once learned, we can map arbitrary 2D images to 3D scene structure. We analyze why analysis-by-synthesis-like losses for supervision of 3D scene structure using differentiable rendering is not practical, as it almost always gets stuck in local minima of visual ambiguities. This can be overcome by a novel form of training: we use an additional network to steer the optimization itself to explore the full gamut of possible solutions i.e. to be curious, and hence, to resolve those ambiguities and find workable minima. The resulting system converts 2D images of different virtual or real images into complete 3D scenes, learned only from 2D images of those scenes.
Deep Generative Modelling of Human Reach-and-Place Action
Oct 05, 2020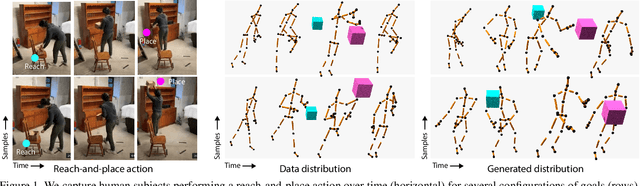

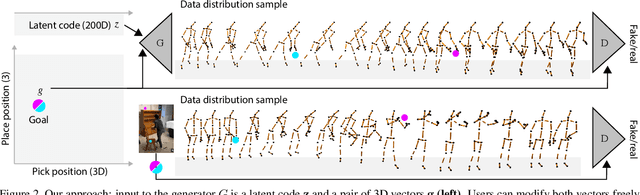

The motion of picking up and placing an object in 3D space is full of subtle detail. Typically these motions are formed from the same constraints, optimizing for swiftness, energy efficiency, as well as physiological limits. Yet, even for identical goals, the motion realized is always subject to natural variation. To capture these aspects computationally, we suggest a deep generative model for human reach-and-place action, conditioned on a start and end position.We have captured a dataset of 600 such human 3D actions, to sample the 2x3-D space of 3D source and targets. While temporal variation is often modeled with complex learning machinery like recurrent neural networks or networks with memory or attention, we here demonstrate a much simpler approach that is convolutional in time and makes use of(periodic) temporal encoding. Provided a latent code and conditioned on start and end position, the model generates a complete 3D character motion in linear time as a sequence of convolutions. Our evaluation includes several ablations, analysis of generative diversity and applications.
X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
Oct 01, 2020
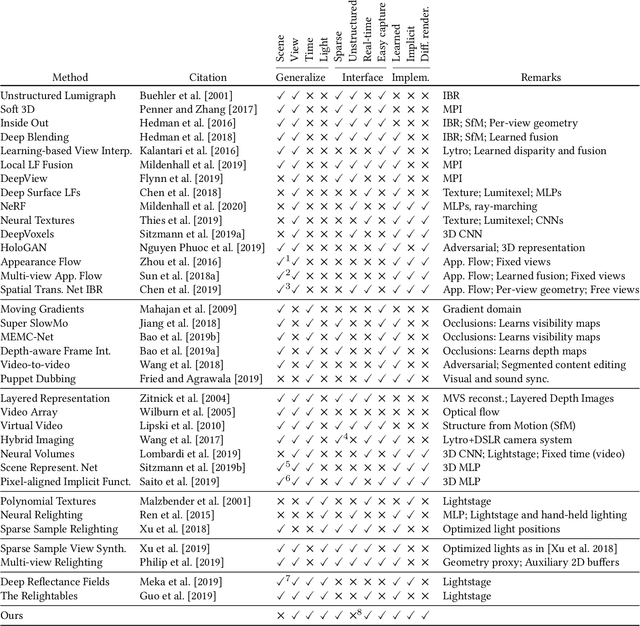
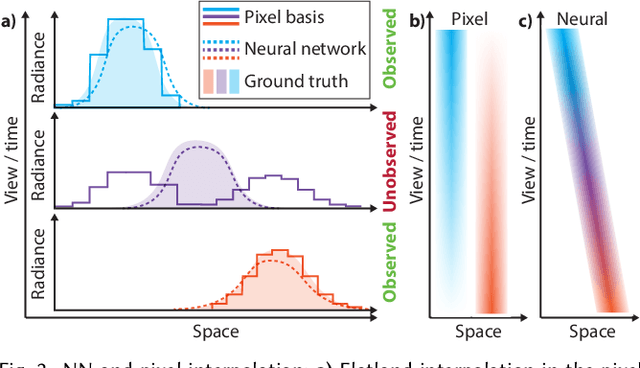
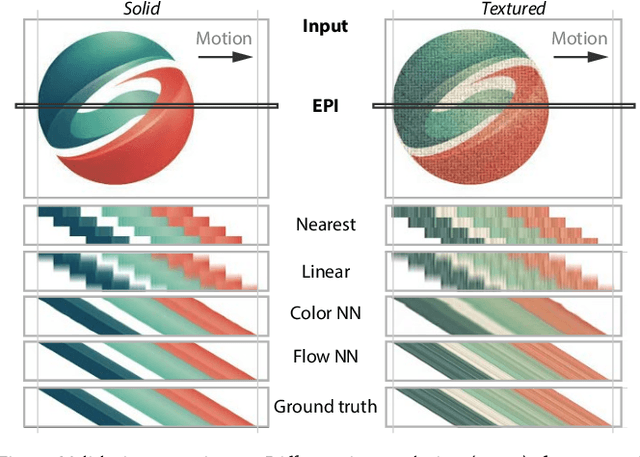
We suggest to represent an X-Field -a set of 2D images taken across different view, time or illumination conditions, i.e., video, light field, reflectance fields or combinations thereof-by learning a neural network (NN) to map their view, time or light coordinates to 2D images. Executing this NN at new coordinates results in joint view, time or light interpolation. The key idea to make this workable is a NN that already knows the "basic tricks" of graphics (lighting, 3D projection, occlusion) in a hard-coded and differentiable form. The NN represents the input to that rendering as an implicit map, that for any view, time, or light coordinate and for any pixel can quantify how it will move if view, time or light coordinates change (Jacobian of pixel position with respect to view, time, illumination, etc.). Our X-Field representation is trained for one scene within minutes, leading to a compact set of trainable parameters and hence real-time navigation in view, time and illumination.
ProteiNN: Intrinsic-Extrinsic Convolution and Pooling for Scalable Deep Protein Analysis
Jul 13, 2020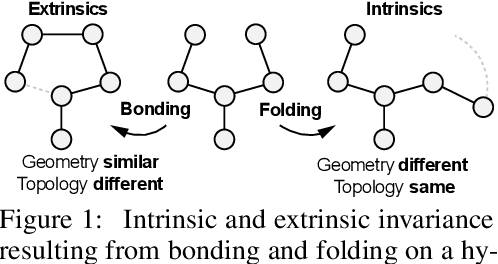
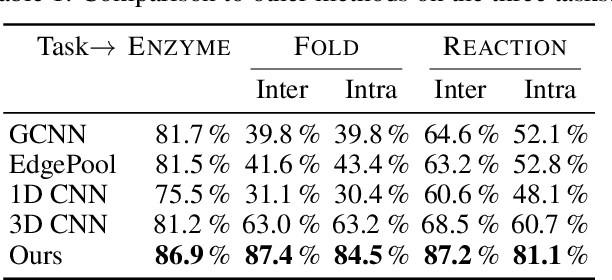

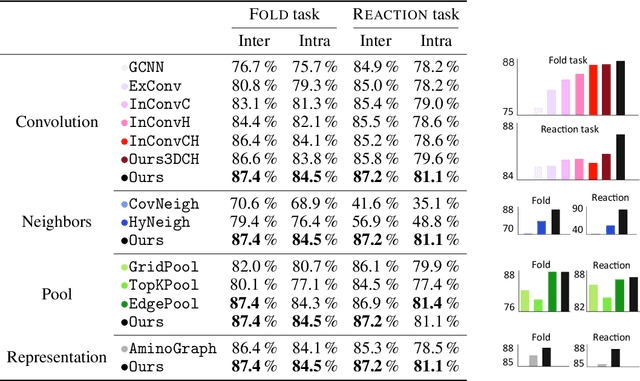
Proteins perform a large variety of functions in living organisms, thus playing a key role in biology. As of now, available learning algorithms to process protein data do not consider several particularities of such data and/or do not scale well for large protein conformations. To fill this gap, we propose two new learning operations enabling deep 3D analysis of large-scale protein data. First, we introduce a novel convolution operator which considers both, the intrinsic (invariant under protein folding) as well as extrinsic (invariant under bonding) structure, by using $n$-D convolutions defined on both the Euclidean distance, as well as multiple geodesic distances between atoms in a multi-graph. Second, we enable a multi-scale protein analysis by introducing hierarchical pooling operators, exploiting the fact that proteins are a recombination of a finite set of amino acids, which can be pooled using shared pooling matrices. Lastly, we evaluate the accuracy of our algorithms on several large-scale data sets for common protein analysis tasks, where we outperform state-of-the-art methods.