 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Modelling of Human Reach-and-Place Action
Oct 05, 2020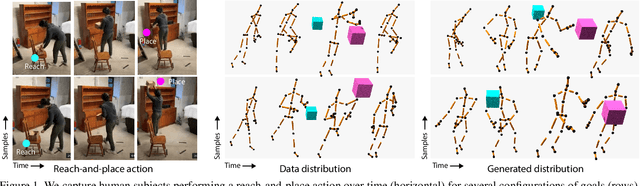

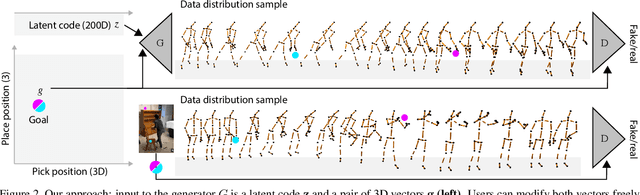

The motion of picking up and placing an object in 3D space is full of subtle detail. Typically these motions are formed from the same constraints, optimizing for swiftness, energy efficiency, as well as physiological limits. Yet, even for identical goals, the motion realized is always subject to natural variation. To capture these aspects computationally, we suggest a deep generative model for human reach-and-place action, conditioned on a start and end position.We have captured a dataset of 600 such human 3D actions, to sample the 2x3-D space of 3D source and targets. While temporal variation is often modeled with complex learning machinery like recurrent neural networks or networks with memory or attention, we here demonstrate a much simpler approach that is convolutional in time and makes use of(periodic) temporal encoding. Provided a latent code and conditioned on start and end position, the model generates a complete 3D character motion in linear time as a sequence of convolutions. Our evaluation includes several ablations, analysis of generative diversity and applications.
Recognition and Synthesis of Object Transport Motion
Sep 27, 2020



Deep learning typically requires vast numbers of training examples in order to be used successfully. Conversely, motion capture data is often expensive to generate, requiring specialist equipment, along with actors to generate the prescribed motions, meaning that motion capture datasets tend to be relatively small. Motion capture data does however provide a rich source of information that is becoming increasingly useful in a wide variety of applications, from gesture recognition in human-robot interaction, to data driven animation. This project illustrates how deep convolutional networks can be used, alongside specialized data augmentation techniques, on a small motion capture dataset to learn detailed information from sequences of a specific type of motion (object transport). The project shows how these same augmentation techniques can be scaled up for use in the more complex task of motion synthesis. By exploring recent developments in the concept of Generative Adversarial Models (GANs), specifically the Wasserstein GAN, this project outlines a model that is able to successfully generate lifelike object transportation motions, with the generated samples displaying varying styles and transport strategies.