 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Field Convolutions by Repeated Differentiation
Apr 04, 2023



Neural fields are evolving towards a general-purpose continuous representation for visual computing. Yet, despite their numerous appealing properties, they are hardly amenable to signal processing. As a remedy, we present a method to perform general continuous convolutions with general continuous signals such as neural fields. Observing that piecewise polynomial kernels reduce to a sparse set of Dirac deltas after repeated differentiation, we leverage convolution identities and train a repeated integral field to efficiently execute large-scale convolutions. We demonstrate our approach on a variety of data modalities and spatially-varying kernels.
Plateau-free Differentiable Path Tracing
Nov 30, 2022



Current differentiable renderers provide light transport gradients with respect to arbitrary scene parameters. However, the mere existence of these gradients does not guarantee useful update steps in an optimization. Instead, inverse rendering might not converge due to inherent plateaus, i.e., regions of zero gradient, in the objective function. We propose to alleviate this by convolving the high-dimensional rendering function that maps scene parameters to images with an additional kernel that blurs the parameter space. We describe two Monte Carlo estimators to compute plateau-free gradients efficiently, i.e., with low variance, and show that these translate into net-gains in optimization error and runtime performance. Our approach is a straightforward extension to both black-box and differentiable renderers and enables optimization of problems with intricate light transport, such as caustics or global illumination, that existing differentiable renderers do not converge on.
3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene
Nov 27, 2022We introduce 3inGAN, an unconditional 3D generative model trained from 2D images of a single self-similar 3D scene. Such a model can be used to produce 3D "remixes" of a given scene, by mapping spatial latent codes into a 3D volumetric representation, which can subsequently be rendered from arbitrary views using physically based volume rendering. By construction, the generated scenes remain view-consistent across arbitrary camera configurations, without any flickering or spatio-temporal artifacts. During training, we employ a combination of 2D, obtained through differentiable volume tracing, and 3D Generative Adversarial Network (GAN) losses, across multiple scales, enforcing realism on both its 3D structure and the 2D renderings. We show results on semi-stochastic scenes of varying scale and complexity, obtained from real and synthetic sources. We demonstrate, for the first time, the feasibility of learning plausible view-consistent 3D scene variations from a single exemplar scene and provide qualitative and quantitative comparisons against recent related methods.
Learning to Rasterize Differentiable
Nov 23, 2022Differentiable rasterization changes the common formulation of primitive rasterization -- which has zero gradients almost everywhere, due to discontinuous edges and occlusion -- to an alternative one, which is not subject to this limitation and has similar optima. These alternative versions in general are ''soft'' versions of the original one. Unfortunately, it is not clear, what exact way of softening will provide the best performance in terms of converging the most reliability to a desired goal. Previous work has analyzed and compared several combinations of softening. In this work, we take it a step further and, instead of making a combinatorical choice of softening operations, parametrize the continuous space of all softening operations. We study meta-learning a parametric S-shape curve as well as an MLP over a set of inverse rendering tasks, so that it generalizes to new and unseen differentiable rendering tasks with optimal softness.
Learning to Learn and Sample BRDFs
Oct 07, 2022
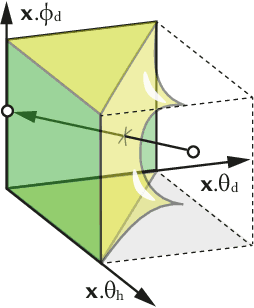

We propose a method to accelerate the joint process of physically acquiring and learning neural Bi-directional Reflectance Distribution Function (BRDF) models. While BRDF learning alone can be accelerated by meta-learning, acquisition remains slow as it relies on a mechanical process. We show that meta-learning can be extended to optimize the physical sampling pattern, too. After our method has been meta-trained for a set of fully-sampled BRDFs, it is able to quickly train on new BRDFs with up to five orders of magnitude fewer physical acquisition samples at similar quality. Our approach also extends to other linear and non-linear BRDF models, which we show in an extensive evaluation.
ReLU Fields: The Little Non-linearity That Could
May 22, 2022
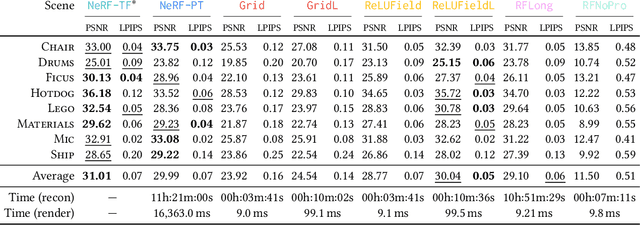

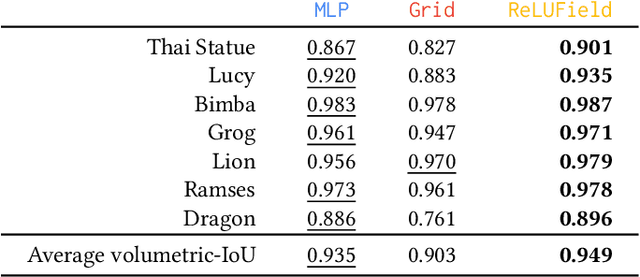
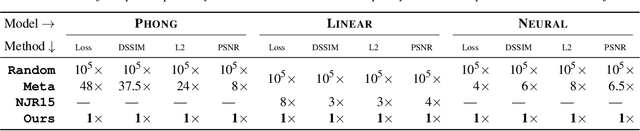
In many recent works, multi-layer perceptions (MLPs) have been shown to be suitable for modeling complex spatially-varying functions including images and 3D scenes. Although the MLPs are able to represent complex scenes with unprecedented quality and memory footprint, this expressive power of the MLPs, however, comes at the cost of long training and inference times. On the other hand, bilinear/trilinear interpolation on regular grid based representations can give fast training and inference times, but cannot match the quality of MLPs without requiring significant additional memory. Hence, in this work, we investigate what is the smallest change to grid-based representations that allows for retaining the high fidelity result of MLPs while enabling fast reconstruction and rendering times. We introduce a surprisingly simple change that achieves this task -- simply allowing a fixed non-linearity (ReLU) on interpolated grid values. When combined with coarse to-fine optimization, we show that such an approach becomes competitive with the state-of-the-art. We report results on radiance fields, and occupancy fields, and compare against multiple existing alternatives. Code and data for the paper are available at https://geometry.cs.ucl.ac.uk/projects/2022/relu_fields.
OutCast: Outdoor Single-image Relighting with Cast Shadows
Apr 20, 2022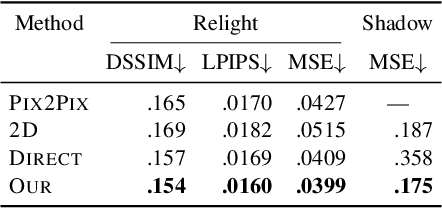
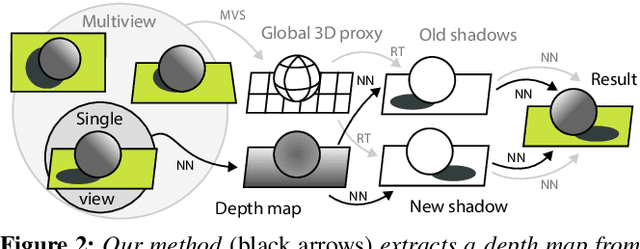
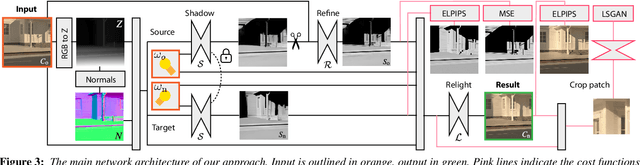
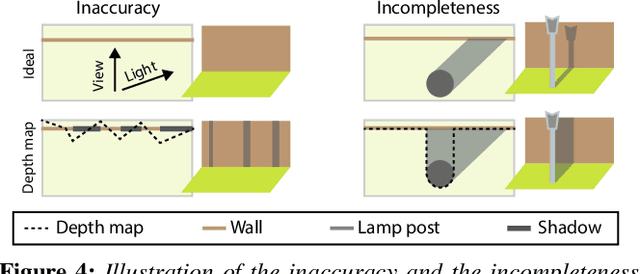
We propose a relighting method for outdoor images. Our method mainly focuses on predicting cast shadows in arbitrary novel lighting directions from a single image while also accounting for shading and global effects such the sun light color and clouds. Previous solutions for this problem rely on reconstructing occluder geometry, e.g. using multi-view stereo, which requires many images of the scene. Instead, in this work we make use of a noisy off-the-shelf single-image depth map estimation as a source of geometry. Whilst this can be a good guide for some lighting effects, the resulting depth map quality is insufficient for directly ray-tracing the shadows. Addressing this, we propose a learned image space ray-marching layer that converts the approximate depth map into a deep 3D representation that is fused into occlusion queries using a learned traversal. Our proposed method achieves, for the first time, state-of-the-art relighting results, with only a single image as input. For supplementary material visit our project page at: https://dgriffiths.uk/outcast.
Clean Implicit 3D Structure from Noisy 2D STEM Images
Mar 29, 2022
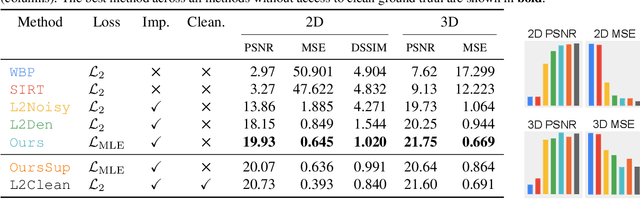
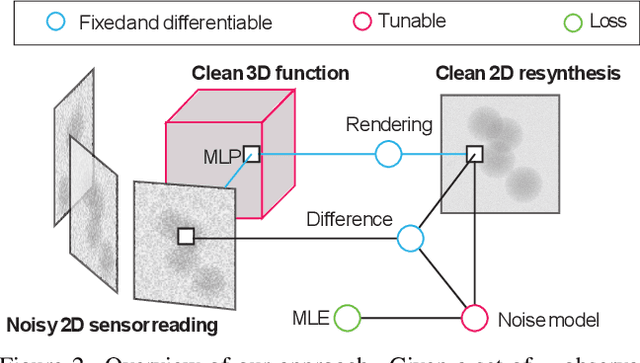

Scanning Transmission Electron Microscopes (STEMs) acquire 2D images of a 3D sample on the scale of individual cell components. Unfortunately, these 2D images can be too noisy to be fused into a useful 3D structure and facilitating good denoisers is challenging due to the lack of clean-noisy pairs. Additionally, representing a detailed 3D structure can be difficult even for clean data when using regular 3D grids. Addressing these two limitations, we suggest a differentiable image formation model for STEM, allowing to learn a joint model of 2D sensor noise in STEM together with an implicit 3D model. We show, that the combination of these models are able to successfully disentangle 3D signal and noise without supervision and outperform at the same time several baselines on synthetic and real data.
ONIX: an X-ray deep-learning tool for 3D reconstructions from sparse views
Mar 01, 2022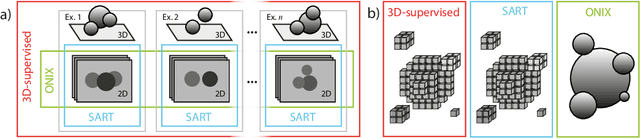
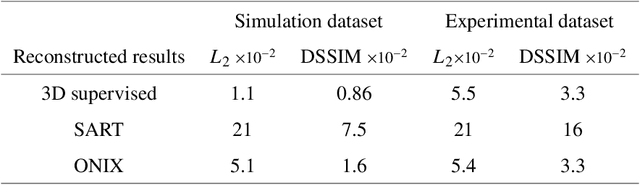
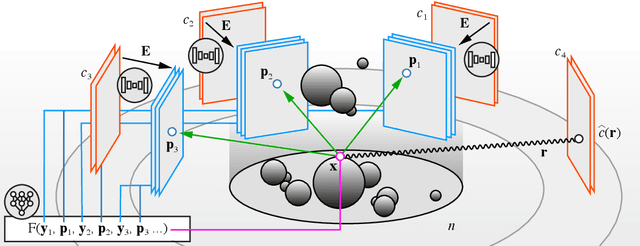
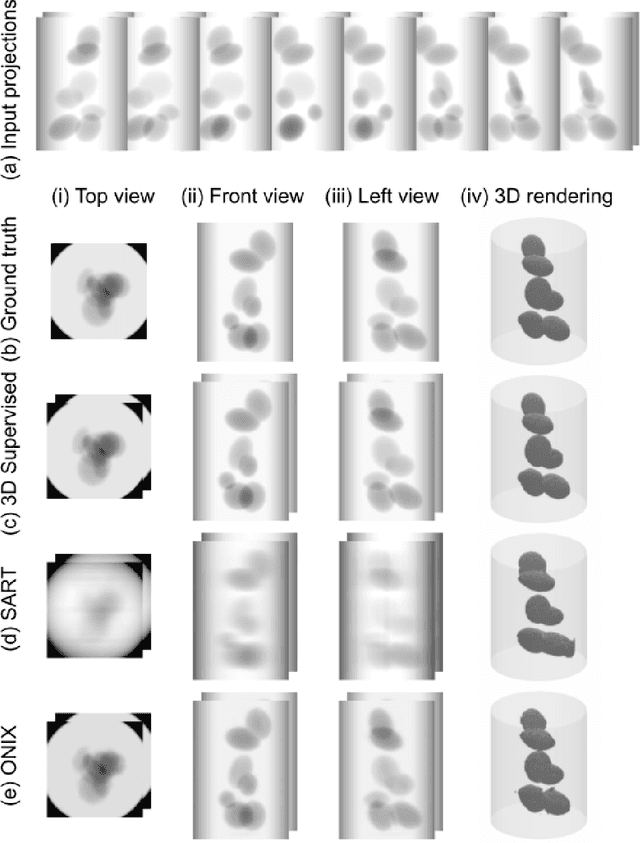
Three-dimensional (3D) X-ray imaging techniques like tomography and confocal microscopy are crucial for academic and industrial applications. These approaches access 3D information by scanning the sample with respect to the X-ray source. However, the scanning process limits the temporal resolution when studying dynamics and is not feasible for some applications, such as surgical guidance in medical applications. Alternatives to obtaining 3D information when scanning is not possible are X-ray stereoscopy and multi-projection imaging. However, these approaches suffer from limited volumetric information as they only acquire a small number of views or projections compared to traditional 3D scanning techniques. Here, we present ONIX (Optimized Neural Implicit X-ray imaging), a deep-learning algorithm capable of retrieving 3D objects with arbitrary large resolution from only a set of sparse projections. ONIX, although it does not have access to any volumetric information, outperforms current 3D reconstruction approaches because it includes the physics of image formation with X-rays, and it generalizes across different experiments over similar samples to overcome the limited volumetric information provided by sparse views. We demonstrate the capabilities of ONIX compared to state-of-the-art tomographic reconstruction algorithms by applying it to simulated and experimental datasets, where a maximum of eight projections are acquired. We anticipate that ONIX will become a crucial tool for the X-ray community by i) enabling the study of fast dynamics not possible today when implemented together with X-ray multi-projection imaging, and ii) enhancing the volumetric information and capabilities of X-ray stereoscopic imaging in medical applications.
Eikonal Fields for Refractive Novel-View Synthesis
Feb 11, 2022
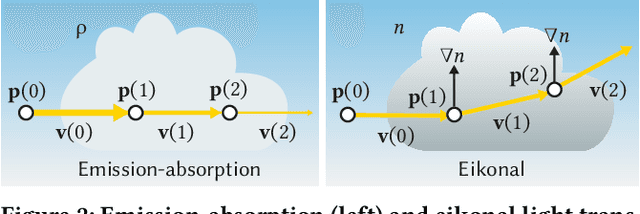

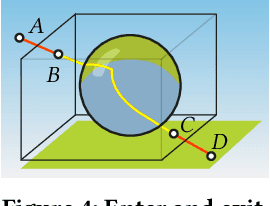
We tackle the problem of generating novel-view images from collections of 2D images showing refractive and reflective objects. Current solutions assume opaque or transparent light transport along straight paths following the emission-absorption model. Instead, we optimize for a field of 3D-varying Index of Refraction (IoR) and trace light through it that bends toward the spatial gradients of said IoR according to the laws of eikonal light transport.