 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting
Mar 25, 2021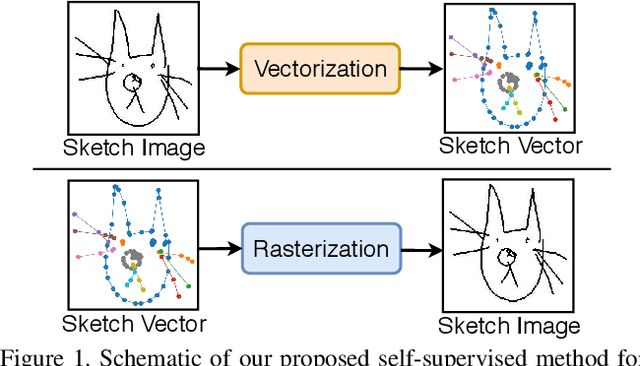
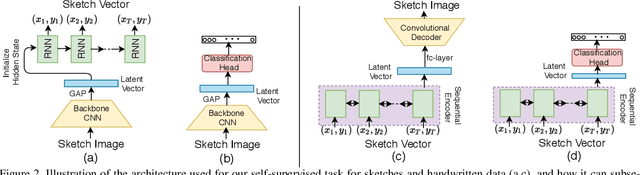
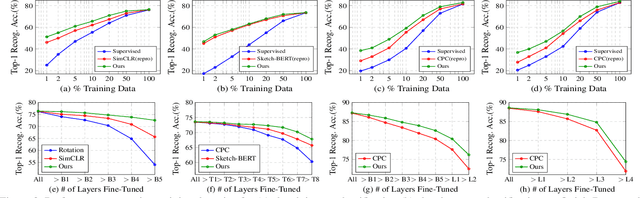
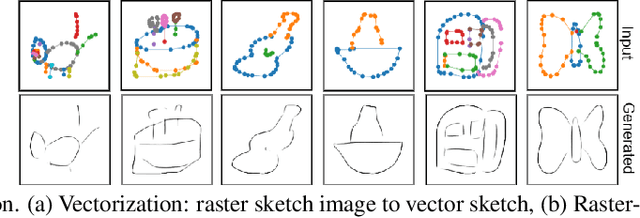
Self-supervised learning has gained prominence due to its efficacy at learning powerful representations from unlabelled data that achieve excellent performance on many challenging downstream tasks. However supervision-free pre-text tasks are challenging to design and usually modality specific. Although there is a rich literature of self-supervised methods for either spatial (such as images) or temporal data (sound or text) modalities, a common pre-text task that benefits both modalities is largely missing. In this paper, we are interested in defining a self-supervised pre-text task for sketches and handwriting data. This data is uniquely characterised by its existence in dual modalities of rasterized images and vector coordinate sequences. We address and exploit this dual representation by proposing two novel cross-modal translation pre-text tasks for self-supervised feature learning: Vectorization and Rasterization. Vectorization learns to map image space to vector coordinates and rasterization maps vector coordinates to image space. We show that the our learned encoder modules benefit both raster-based and vector-based downstream approaches to analysing hand-drawn data. Empirical evidence shows that our novel pre-text tasks surpass existing single and multi-modal self-supervision methods.
Searching for Robustness: Loss Learning for Noisy Classification Tasks
Feb 27, 2021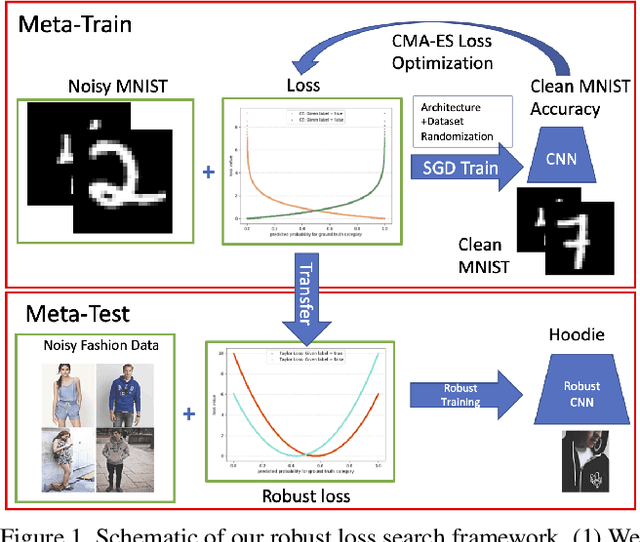
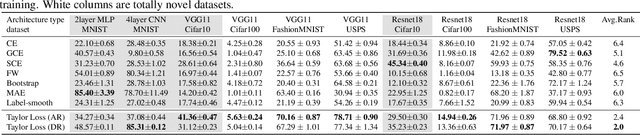
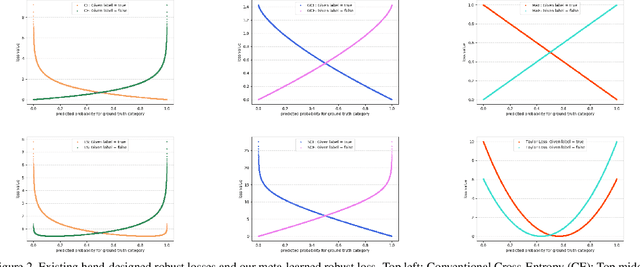
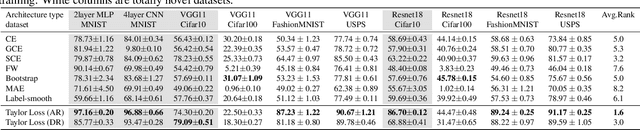
We present a "learning to learn" approach for automatically constructing white-box classification loss functions that are robust to label noise in the training data. We parameterize a flexible family of loss functions using Taylor polynomials, and apply evolutionary strategies to search for noise-robust losses in this space. To learn re-usable loss functions that can apply to new tasks, our fitness function scores their performance in aggregate across a range of training dataset and architecture combinations. The resulting white-box loss provides a simple and fast "plug-and-play" module that enables effective noise-robust learning in diverse downstream tasks, without requiring a special training procedure or network architecture. The efficacy of our method is demonstrated on a variety of datasets with both synthetic and real label noise, where we compare favourably to previous work.
FedH2L: Federated Learning with Model and Statistical Heterogeneity
Jan 27, 2021
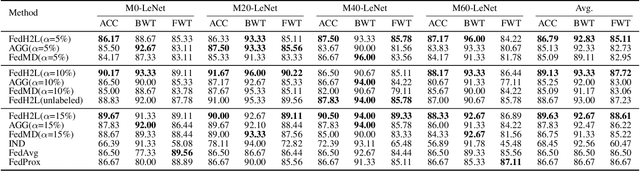
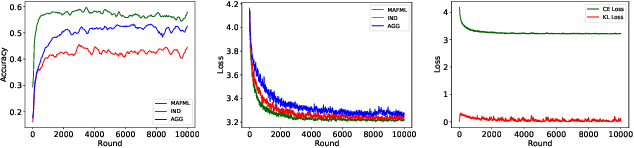
Federated learning (FL) enables distributed participants to collectively learn a strong global model without sacrificing their individual data privacy. Mainstream FL approaches require each participant to share a common network architecture and further assume that data are are sampled IID across participants. However, in real-world deployments participants may require heterogeneous network architectures; and the data distribution is almost certainly non-uniform across participants. To address these issues we introduce FedH2L, which is agnostic to both the model architecture and robust to different data distributions across participants. In contrast to approaches sharing parameters or gradients, FedH2L relies on mutual distillation, exchanging only posteriors on a shared seed set between participants in a decentralized manner. This makes it extremely bandwidth efficient, model agnostic, and crucially produces models capable of performing well on the whole data distribution when learning from heterogeneous silos.
Tensor Composition Net for Visual Relationship Prediction
Dec 10, 2020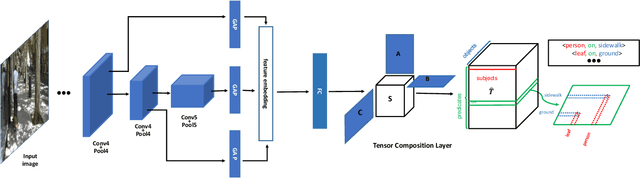

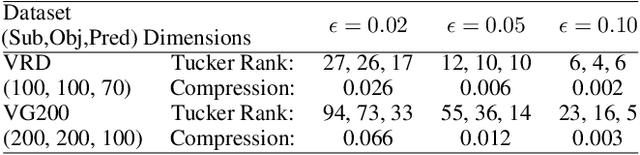

We present a novel Tensor Composition Network (TCN) to predict visual relationships in images. Visual Relationships in subject-predicate-object form provide a more powerful query modality than simple image tags. However Visual Relationship Prediction (VRP) also provides a more challenging test of image understanding than conventional image tagging, and is difficult to learn due to a large label-space and incomplete annotation. The key idea of our TCN is to exploit the low rank property of the visual relationship tensor, so as to leverage correlations within and across objects and relationships, and make a structured prediction of all objects and their relations in an image. To show the effectiveness of our method, we first empirically compare our model with multi-label classification alternatives on VRP, and show that our model outperforms state-of-the-art MLIC methods. We then show that, thanks to our tensor (de)composition layer, our model can predict visual relationships which have not been seen in training dataset. We finally show our TCN's image-level visual relationship prediction provides a simple and efficient mechanism for relation-based image retrieval.
How Well Do Self-Supervised Models Transfer?
Nov 26, 2020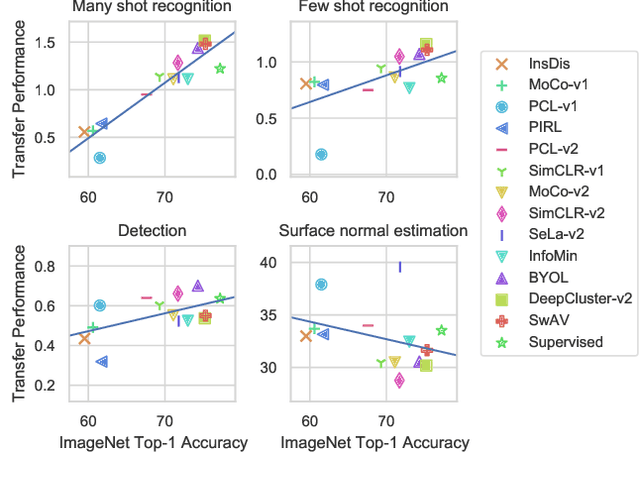
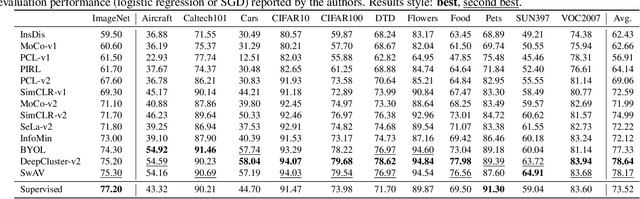
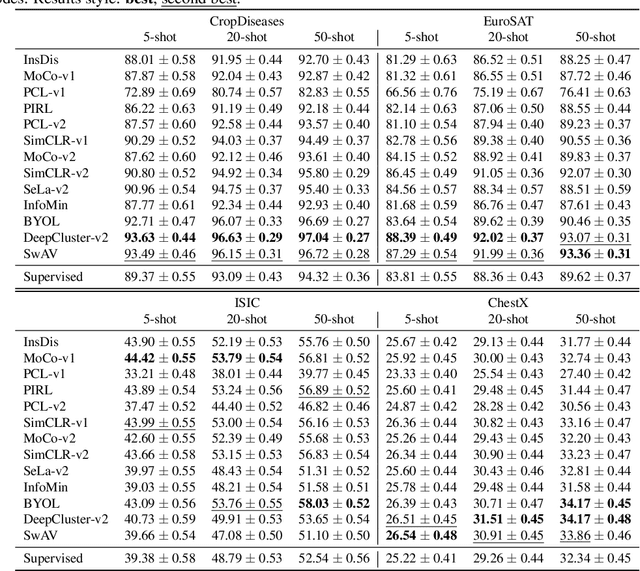
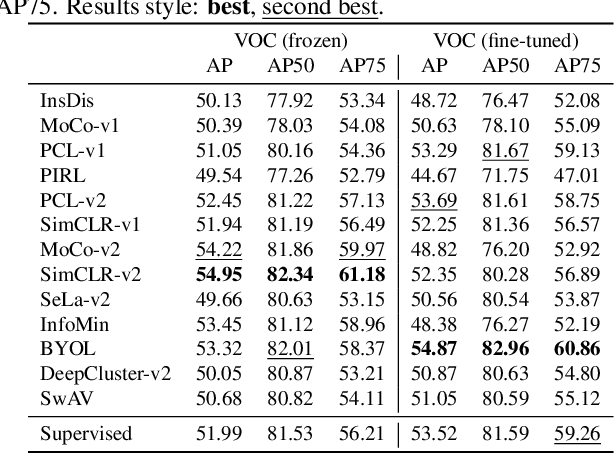
Self-supervised visual representation learning has seen huge progress in recent months. However, no large scale evaluation has compared the many pre-trained models that are now available. In this paper, we evaluate the transfer performance of 13 top self-supervised models on 25 downstream tasks, including many-shot classification, few-shot classification, object detection and dense prediction. We compare their performance to a supervised baseline and conclude that on most datasets, the best self-supervised models outperform supervision, confirming the recently observed trend in the literature. We find ImageNet Top-1 accuracy to be highly correlated with transfer to many-shot recognition, but increasingly less so for few-shot, object detection and dense prediction, as well as to unstructured data. There is no single self-supervised method which dominates overall, but notably DeepCluster-v2 comes out on top in recognition and SimCLR-v2 in detection and dense prediction. Our analysis of feature properties suggests that top self-supervised learners struggle to preserve colour information as well as supervised (likely due to use of augmentation), but exhibit better calibration for recognition and suffer from less attentive overfitting than supervised learners.
On Learning Semantic Representations for Million-Scale Free-Hand Sketches
Jul 07, 2020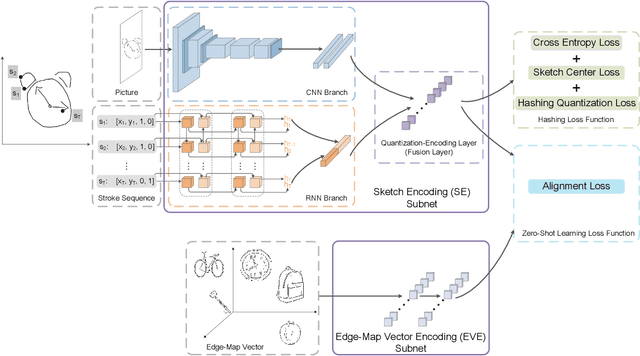
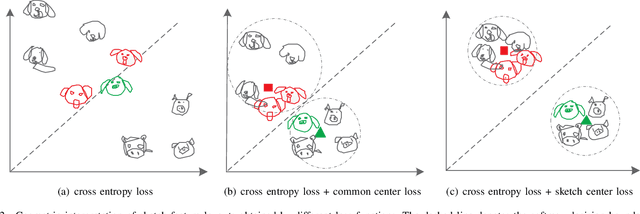
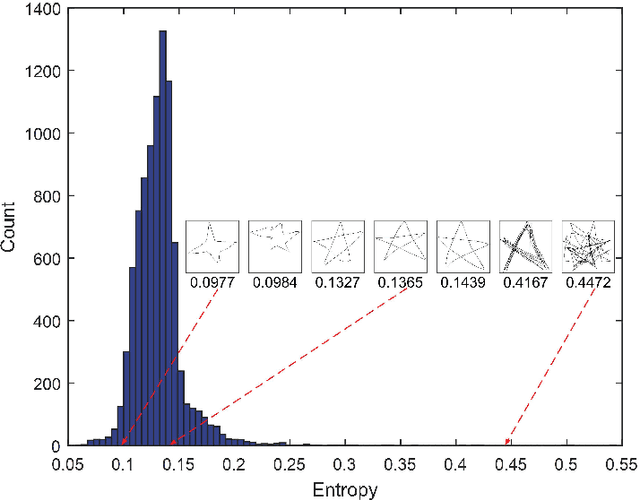

In this paper, we study learning semantic representations for million-scale free-hand sketches. This is highly challenging due to the domain-unique traits of sketches, e.g., diverse, sparse, abstract, noisy. We propose a dual-branch CNNRNN network architecture to represent sketches, which simultaneously encodes both the static and temporal patterns of sketch strokes. Based on this architecture, we further explore learning the sketch-oriented semantic representations in two challenging yet practical settings, i.e., hashing retrieval and zero-shot recognition on million-scale sketches. Specifically, we use our dual-branch architecture as a universal representation framework to design two sketch-specific deep models: (i) We propose a deep hashing model for sketch retrieval, where a novel hashing loss is specifically designed to accommodate both the abstract and messy traits of sketches. (ii) We propose a deep embedding model for sketch zero-shot recognition, via collecting a large-scale edge-map dataset and proposing to extract a set of semantic vectors from edge-maps as the semantic knowledge for sketch zero-shot domain alignment. Both deep models are evaluated by comprehensive experiments on million-scale sketches and outperform the state-of-the-art competitors.
Don't Wait, Just Weight: Improving Unsupervised Representations by Learning Goal-Driven Instance Weights
Jun 22, 2020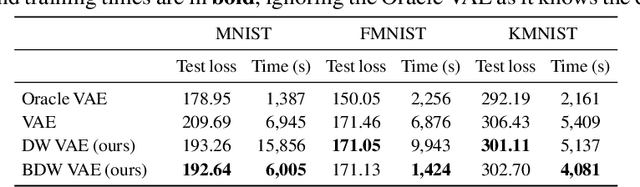
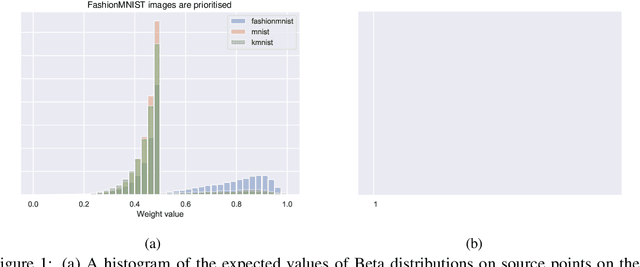
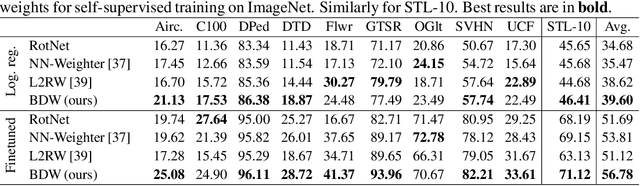
In the absence of large labelled datasets, self-supervised learning techniques can boost performance by learning useful representations from unlabelled data, which is often more readily available. However, there is often a domain shift between the unlabelled collection and the downstream target problem data. We show that by learning Bayesian instance weights for the unlabelled data, we can improve the downstream classification accuracy by prioritising the most useful instances. Additionally, we show that the training time can be reduced by discarding unnecessary datapoints. Our method, BetaDataWeighter is evaluated using the popular self-supervised rotation prediction task on STL-10 and Visual Decathlon. We compare to related instance weighting schemes, both hand-designed heuristics and meta-learning, as well as conventional self-supervised learning. BetaDataWeighter achieves both the highest average accuracy and rank across datasets, and on STL-10 it prunes up to 78% of unlabelled images without significant loss in accuracy, corresponding to over 50% reduction in training time.
Online Meta-Critic Learning for Off-Policy Actor-Critic Methods
Mar 11, 2020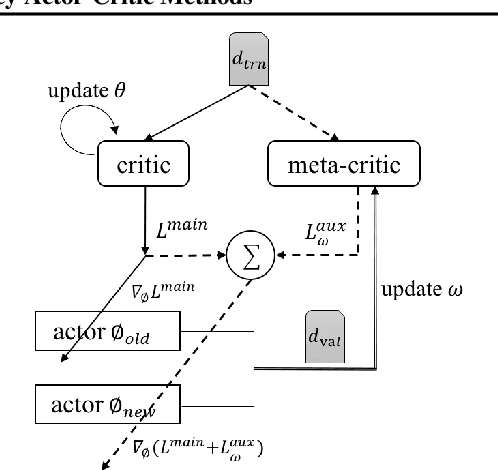
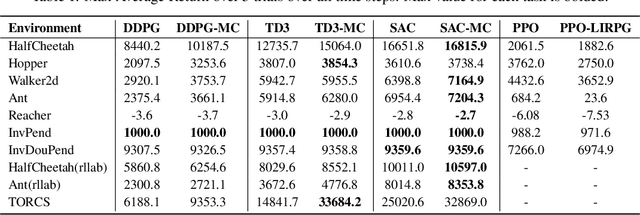
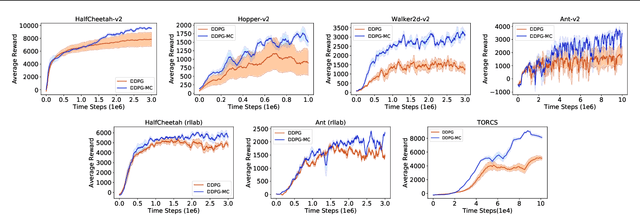

Off-Policy Actor-Critic (Off-PAC) methods have proven successful in a variety of continuous control tasks. Normally, the critic's action-value function is updated using temporal-difference, and the critic in turn provides a loss for the actor that trains it to take actions with higher expected return. In this paper, we introduce a novel and flexible meta-critic that observes the learning process and meta-learns an additional loss for the actor that accelerates and improves actor-critic learning. Compared to the vanilla critic, the meta-critic network is explicitly trained to accelerate the learning process; and compared to existing meta-learning algorithms, meta-critic is rapidly learned online for a single task, rather than slowly over a family of tasks. Crucially, our meta-critic framework is designed for off-policy based learners, which currently provide state-of-the-art reinforcement learning sample efficiency. We demonstrate that online meta-critic learning leads to improvements in avariety of continuous control environments when combined with contemporary Off-PAC methods DDPG, TD3 and the state-of-the-art SAC.
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
Mar 05, 2020
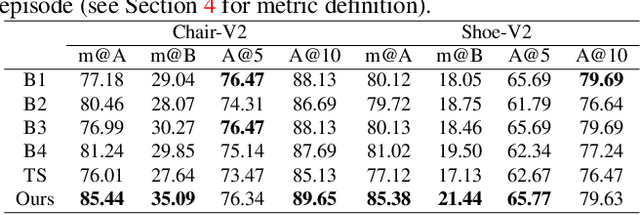
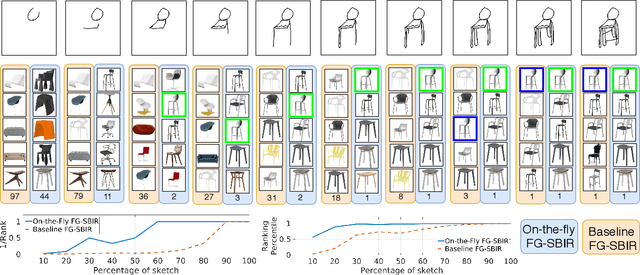
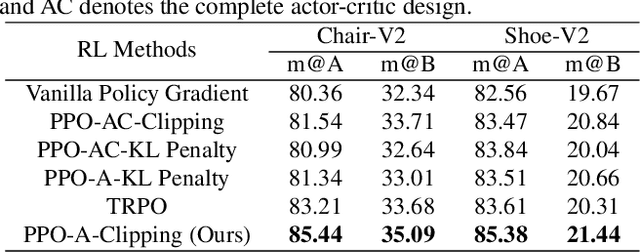
Fine-grained sketch-based image retrieval (FG-SBIR) addresses the problem of retrieving a particular photo instance given a user's query sketch. Its widespread applicability is however hindered by the fact that drawing a sketch takes time, and most people struggle to draw a complete and faithful sketch. In this paper, we reformulate the conventional FG-SBIR framework to tackle these challenges, with the ultimate goal of retrieving the target photo with the least number of strokes possible. We further propose an on-the-fly design that starts retrieving as soon as the user starts drawing. To accomplish this, we devise a reinforcement learning-based cross-modal retrieval framework that directly optimizes rank of the ground-truth photo over a complete sketch drawing episode. Additionally, we introduce a novel reward scheme that circumvents the problems related to irrelevant sketch strokes, and thus provides us with a more consistent rank list during the retrieval. We achieve superior early-retrieval efficiency over state-of-the-art methods and alternative baselines on two publicly available fine-grained sketch retrieval datasets.
Unlimited Resolution Image Generation with R2D2-GANs
Mar 02, 2020

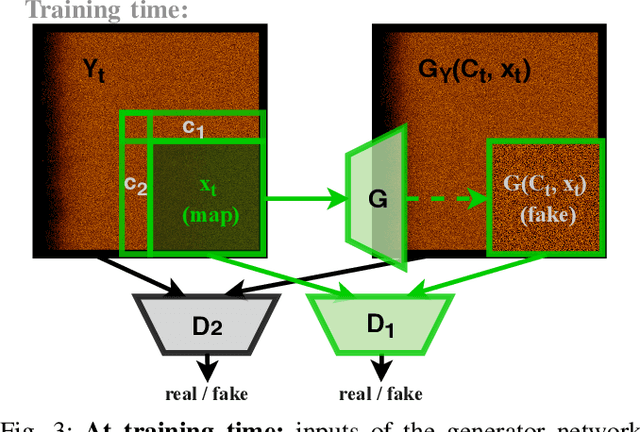
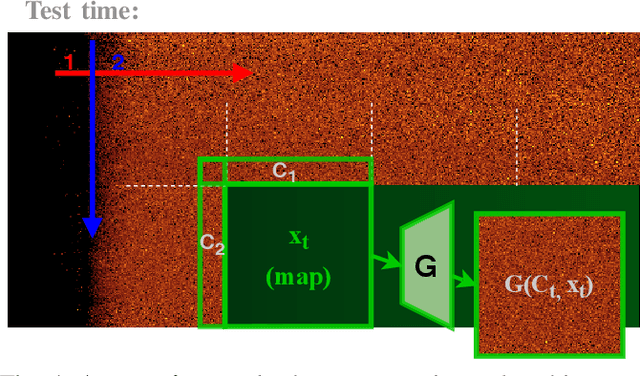
In this paper we present a novel simulation technique for generating high quality images of any predefined resolution. This method can be used to synthesize sonar scans of size equivalent to those collected during a full-length mission, with across track resolutions of any chosen magnitude. In essence, our model extends Generative Adversarial Networks (GANs) based architecture into a conditional recursive setting, that facilitates the continuity of the generated images. The data produced is continuous, realistically-looking, and can also be generated at least two times faster than the real speed of acquisition for the sonars with higher resolutions, such as EdgeTech. The seabed topography can be fully controlled by the user. The visual assessment tests demonstrate that humans cannot distinguish the simulated images from real. Moreover, experimental results suggest that in the absence of real data the autonomous recognition systems can benefit greatly from training with the synthetic data, produced by the R2D2-GANs.