 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClore: Interactive Pathology Image Segmentation with Click-based Local Refinement
Mar 29, 2026Recent advancements in deep learning-based interactive segmentation methods have significantly improved pathology image segmentation. Most existing approaches utilize user-provided positive and negative clicks to guide the segmentation process. However, these methods primarily rely on iterative global updates for refinement, which lead to redundant re-prediction and often fail to capture fine-grained structures or correct subtle errors during localized adjustments. To address this limitation, we propose the Click-based Local Refinement (Clore) pipeline, a simple yet efficient method designed to enhance interactive segmentation. The key innovation of Clore lies in its hierarchical interaction paradigm: the initial clicks drive global segmentation to rapidly outline large target regions, while subsequent clicks progressively refine local details to achieve precise boundaries. This approach not only improves the ability to handle fine-grained segmentation tasks but also achieves high-quality results with fewer interactions. Experimental results on four datasets demonstrate that Clore achieves the best balance between segmentation accuracy and interaction cost, making it an effective solution for efficient and accurate interactive pathology image segmentation.
MPU: Towards Secure and Privacy-Preserving Knowledge Unlearning for Large Language Models
Feb 27, 2026Machine unlearning for large language models often faces a privacy dilemma in which strict constraints prohibit sharing either the server's parameters or the client's forget set. To address this dual non-disclosure constraint, we propose MPU, an algorithm-agnostic privacy-preserving Multiple Perturbed Copies Unlearning framework that primarily introduces two server-side modules: Pre-Process for randomized copy generation and Post-Process for update aggregation. In Pre-Process, the server distributes multiple perturbed and reparameterized model instances, allowing the client to execute unlearning locally on its private forget set without accessing the server's exact original parameters. After local unlearning, the server performs Post-Process by inverting the reparameterization and aggregating updates with a harmonic denoising procedure to alleviate the impact of perturbation. Experiments with seven unlearning algorithms show that MPU achieves comparable unlearning performance to noise-free baselines, with most algorithms' average degradation well below 1% under 10% noise, and can even outperform the noise-free baseline for some algorithms under 1% noise. Code is available at https://github.com/Tristan-SHU/MPU.
M-Loss: Quantifying Model Merging Compatibility with Limited Unlabeled Data
Feb 09, 2026Training of large-scale models is both computationally intensive and often constrained by the availability of labeled data. Model merging offers a compelling alternative by directly integrating the weights of multiple source models without requiring additional data or extensive training. However, conventional model merging techniques, such as parameter averaging, often suffer from the unintended combination of non-generalizable features, especially when source models exhibit significant weight disparities. Comparatively, model ensembling generally provides more stable and superior performance that aggregates multiple models by averaging outputs. However, it incurs higher inference costs and increased storage requirements. While previous studies experimentally showed the similarities between model merging and ensembling, theoretical evidence and evaluation metrics remain lacking. To address this gap, we introduce Merging-ensembling loss (M-Loss), a novel evaluation metric that quantifies the compatibility of merging source models using very limited unlabeled data. By measuring the discrepancy between parameter averaging and model ensembling at layer and node levels, M-Loss facilitates more effective merging strategies. Specifically, M-Loss serves both as a quantitative criterion of the theoretical feasibility of model merging, and a guide for parameter significance in model pruning. Our theoretical analysis and empirical evaluations demonstrate that incorporating M-Loss into the merging process significantly improves the alignment between merged models and model ensembling, providing a scalable and efficient framework for accurate model consolidation.
Artificial Intelligence without Restriction Surpassing Human Intelligence with Probability One: Theoretical Insight into Secrets of the Brain with AI Twins of the Brain
Dec 04, 2024



Artificial Intelligence (AI) has apparently become one of the most important techniques discovered by humans in history while the human brain is widely recognized as one of the most complex systems in the universe. One fundamental critical question which would affect human sustainability remains open: Will artificial intelligence (AI) evolve to surpass human intelligence in the future? This paper shows that in theory new AI twins with fresh cellular level of AI techniques for neuroscience could approximate the brain and its functioning systems (e.g. perception and cognition functions) with any expected small error and AI without restrictions could surpass human intelligence with probability one in the end. This paper indirectly proves the validity of the conjecture made by Frank Rosenblatt 70 years ago about the potential capabilities of AI, especially in the realm of artificial neural networks. Intelligence is just one of fortuitous but sophisticated creations of the nature which has not been fully discovered. Like mathematics and physics, with no restrictions artificial intelligence would lead to a new subject with its self-contained systems and principles. We anticipate that this paper opens new doors for 1) AI twins and other AI techniques to be used in cellular level of efficient neuroscience dynamic analysis, functioning analysis of the brain and brain illness solutions; 2) new worldwide collaborative scheme for interdisciplinary teams concurrently working on and modelling different types of neurons and synapses and different level of functioning subsystems of the brain with AI techniques; 3) development of low energy of AI techniques with the aid of fundamental neuroscience properties; and 4) new controllable, explainable and safe AI techniques with reasoning capabilities of discovering principles in nature.
EarthquakeGen: Earthquake Simulation Using Generative Adversarial Networks
Nov 10, 2019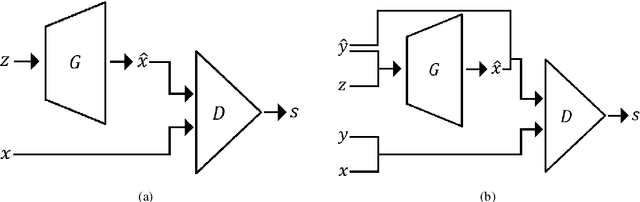
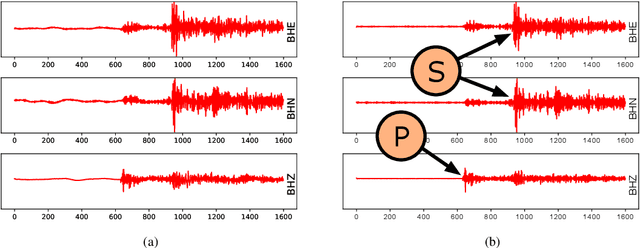
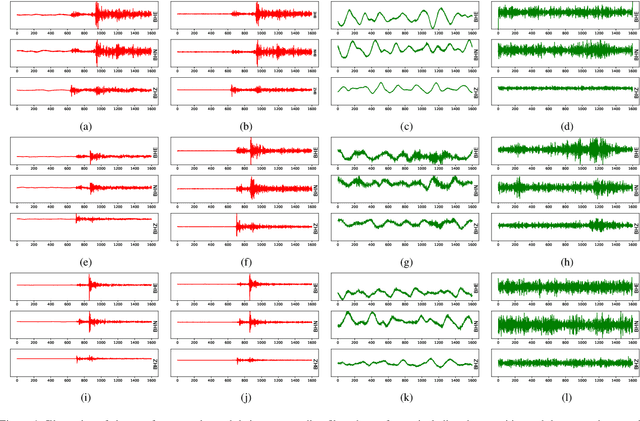
Detecting earthquake events from seismic time series has proved itself a challenging task. Manual detection can be expensive and tedious due to the intensive labor and large scale data set. In recent years, automatic detection methods based on machine learning have been developed to improve accuracy and efficiency. However, the accuracy of those methods relies on a sufficient amount of high-quality training data, which itself can be expensive to obtain due to the requirement of domain knowledge and subject matter expertise. This paper is to resolve this dilemma by answering two questions: (1) provided with a limited number of reliable labels, can we use them to generate more synthetic labels; (2) Can we use those synthetic labels to improve the detectability? Among all the existing generative models, the generative adversarial network (GAN) shows its supreme capability in generating high-quality synthetic samples in multiple domains. We designed our model based on GAN. In particular, we studied several different network structures. By comparing the generated results, our GAN-based generative model yields the highest quality. We further combine the dataset with synthetic samples generated by our generative model and show that the detectability of our earthquake classification model is significantly improved than the one trained without augmenting the training set.