 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fully Dense Neural Networks for Image Semantic Segmentation
May 22, 2019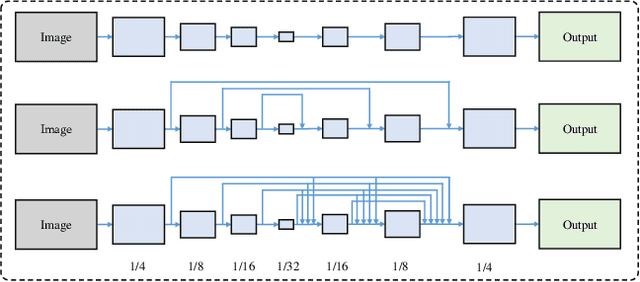
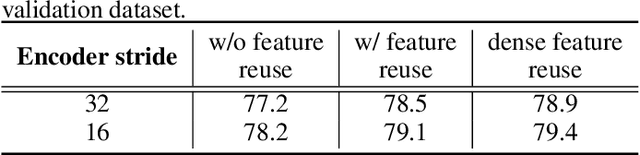

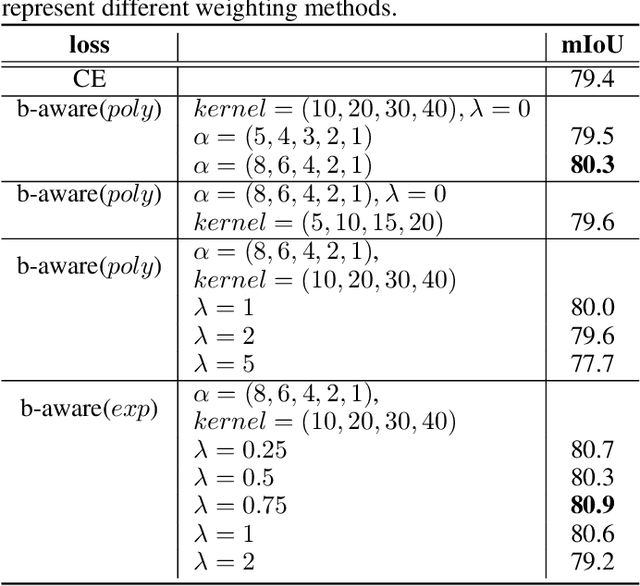
Semantic segmentation is pixel-wise classification which retains critical spatial information. The "feature map reuse" has been commonly adopted in CNN based approaches to take advantage of feature maps in the early layers for the later spatial reconstruction. Along this direction, we go a step further by proposing a fully dense neural network with an encoder-decoder structure that we abbreviate as FDNet. For each stage in the decoder module, feature maps of all the previous blocks are adaptively aggregated to feed-forward as input. On the one hand, it reconstructs the spatial boundaries accurately. On the other hand, it learns more efficiently with the more efficient gradient backpropagation. In addition, we propose the boundary-aware loss function to focus more attention on the pixels near the boundary, which boosts the "hard examples" labeling. We have demonstrated the best performance of the FDNet on the two benchmark datasets: PASCAL VOC 2012, NYUDv2 over previous works when not considering training on other datasets.
ContextDesc: Local Descriptor Augmentation with Cross-Modality Context
Apr 08, 2019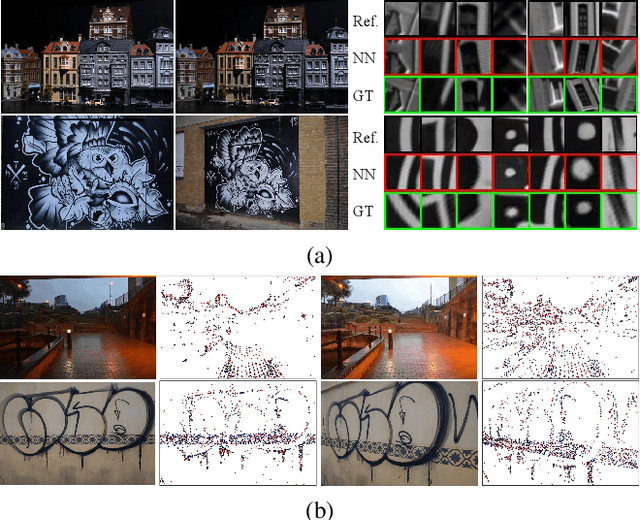

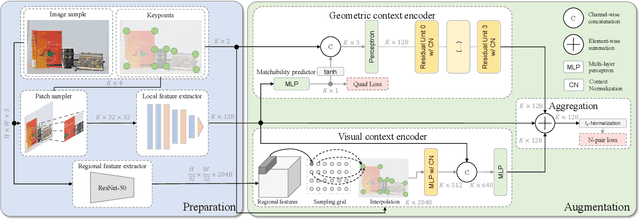
Most existing studies on learning local features focus on the patch-based descriptions of individual keypoints, whereas neglecting the spatial relations established from their keypoint locations. In this paper, we go beyond the local detail representation by introducing context awareness to augment off-the-shelf local feature descriptors. Specifically, we propose a unified learning framework that leverages and aggregates the cross-modality contextual information, including (i) visual context from high-level image representation, and (ii) geometric context from 2D keypoint distribution. Moreover, we propose an effective N-pair loss that eschews the empirical hyper-parameter search and improves the convergence. The proposed augmentation scheme is lightweight compared with the raw local feature description, meanwhile improves remarkably on several large-scale benchmarks with diversified scenes, which demonstrates both strong practicality and generalization ability in geometric matching applications.
Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference
Feb 27, 2019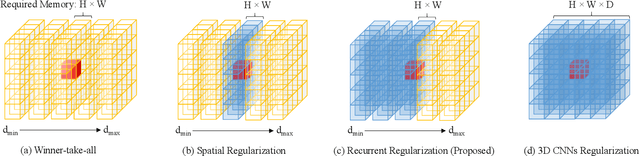
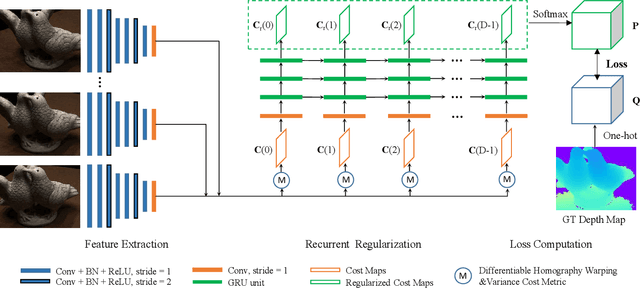

Deep learning has recently demonstrated its excellent performance for multi-view stereo (MVS). However, one major limitation of current learned MVS approaches is the scalability: the memory-consuming cost volume regularization makes the learned MVS hard to be applied to high-resolution scenes. In this paper, we introduce a scalable multi-view stereo framework based on the recurrent neural network. Instead of regularizing the entire 3D cost volume in one go, the proposed Recurrent Multi-view Stereo Network (R-MVSNet) sequentially regularizes the 2D cost maps along the depth direction via the gated recurrent unit (GRU). This reduces dramatically the memory consumption and makes high-resolution reconstruction feasible. We first show the state-of-the-art performance achieved by the proposed R-MVSNet on the recent MVS benchmarks. Then, we further demonstrate the scalability of the proposed method on several large-scale scenarios, where previous learned approaches often fail due to the memory constraint. Code is available at https://github.com/YoYo000/MVSNet.
Beyond Photometric Loss for Self-Supervised Ego-Motion Estimation
Feb 25, 2019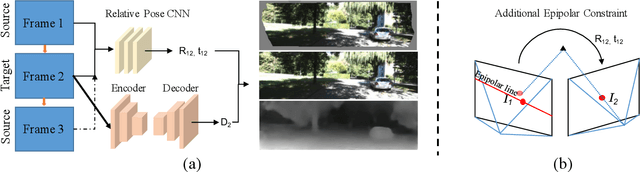


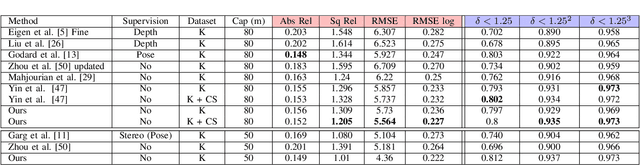
Accurate relative pose is one of the key components in visual odometry (VO) and simultaneous localization and mapping (SLAM). Recently, the self-supervised learning framework that jointly optimizes the relative pose and target image depth has attracted the attention of the community. Previous works rely on the photometric error generated from depths and poses between adjacent frames, which contains large systematic error under realistic scenes due to reflective surfaces and occlusions. In this paper, we bridge the gap between geometric loss and photometric loss by introducing the matching loss constrained by epipolar geometry in a self-supervised framework. Evaluated on the KITTI dataset, our method outperforms the state-of-the-art unsupervised ego-motion estimation methods by a large margin. The code and data are available at https://github.com/hlzz/DeepMatchVO.
Matchable Image Retrieval by Learning from Surface Reconstruction
Dec 10, 2018
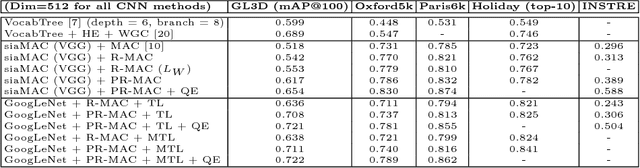

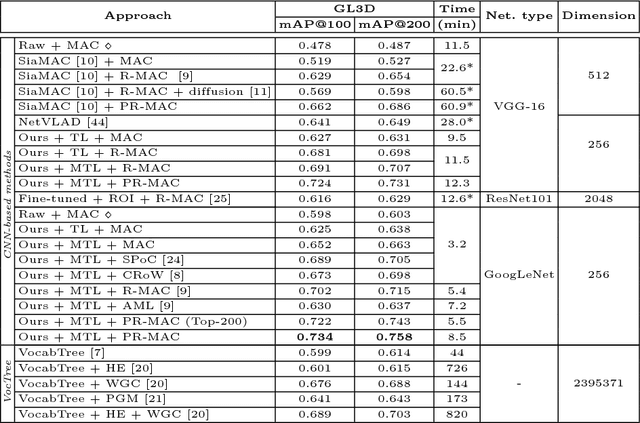
Convolutional Neural Networks (CNNs) have achieved superior performance on object image retrieval, while Bag-of-Words (BoW) models with handcrafted local features still dominate the retrieval of overlapping images in 3D reconstruction. In this paper, we narrow down this gap by presenting an efficient CNN-based method to retrieve images with overlaps, which we refer to as the matchable image retrieval problem. Different from previous methods that generates training data based on sparse reconstruction, we create a large-scale image database with rich 3D geometrics and exploit information from surface reconstruction to obtain fine-grained training data. We propose a batched triplet-based loss function combined with mesh re-projection to effectively learn the CNN representation. The proposed method significantly accelerates the image retrieval process in 3D reconstruction and outperforms the state-of-the-art CNN-based and BoW methods for matchable image retrieval. The code and data are available at https://github.com/hlzz/mirror.
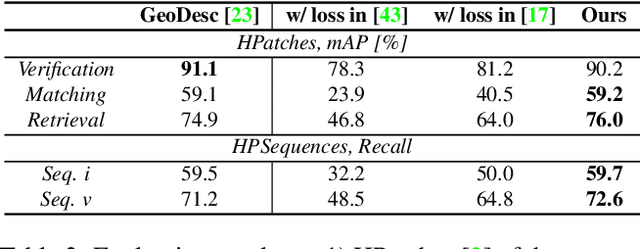
GeoDesc: Learning Local Descriptors by Integrating Geometry Constraints
Aug 16, 2018
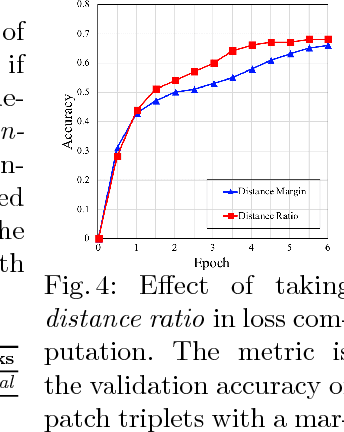

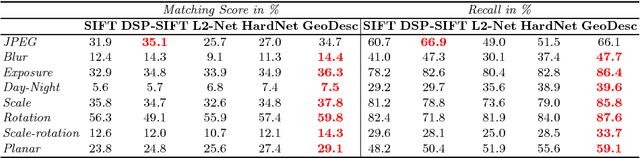
Learned local descriptors based on Convolutional Neural Networks (CNNs) have achieved significant improvements on patch-based benchmarks, whereas not having demonstrated strong generalization ability on recent benchmarks of image-based 3D reconstruction. In this paper, we mitigate this limitation by proposing a novel local descriptor learning approach that integrates geometry constraints from multi-view reconstructions, which benefits the learning process in terms of data generation, data sampling and loss computation. We refer to the proposed descriptor as GeoDesc, and demonstrate its superior performance on various large-scale benchmarks, and in particular show its great success on challenging reconstruction tasks. Moreover, we provide guidelines towards practical integration of learned descriptors in Structure-from-Motion (SfM) pipelines, showing the good trade-off that GeoDesc delivers to 3D reconstruction tasks between accuracy and efficiency.
MVSNet: Depth Inference for Unstructured Multi-view Stereo
Jul 17, 2018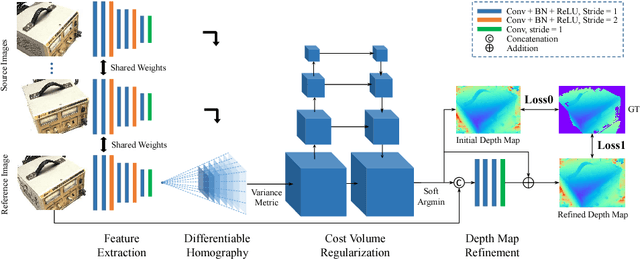
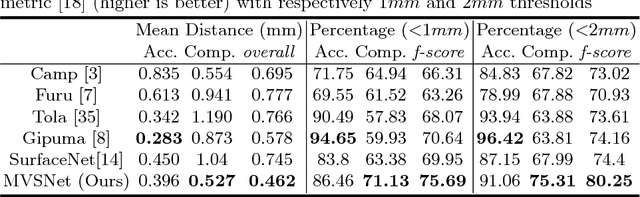
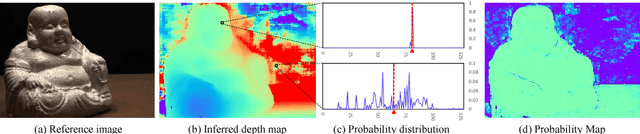
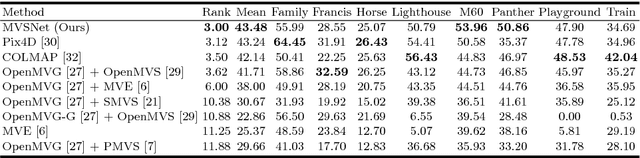
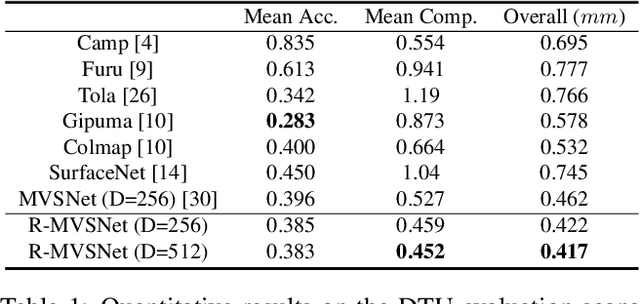
We present an end-to-end deep learning architecture for depth map inference from multi-view images. In the network, we first extract deep visual image features, and then build the 3D cost volume upon the reference camera frustum via the differentiable homography warping. Next, we apply 3D convolutions to regularize and regress the initial depth map, which is then refined with the reference image to generate the final output. Our framework flexibly adapts arbitrary N-view inputs using a variance-based cost metric that maps multiple features into one cost feature. The proposed MVSNet is demonstrated on the large-scale indoor DTU dataset. With simple post-processing, our method not only significantly outperforms previous state-of-the-arts, but also is several times faster in runtime. We also evaluate MVSNet on the complex outdoor Tanks and Temples dataset, where our method ranks first before April 18, 2018 without any fine-tuning, showing the strong generalization ability of MVSNet.
Learning and Matching Multi-View Descriptors for Registration of Point Clouds
Jul 16, 2018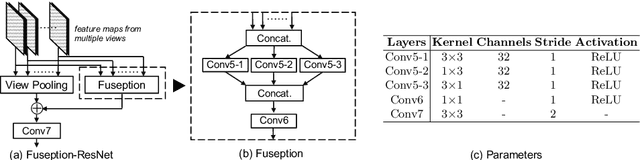

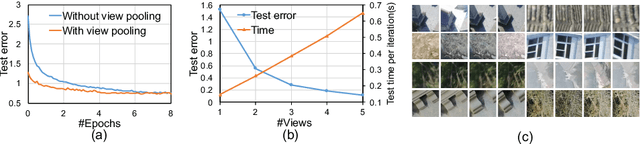

Critical to the registration of point clouds is the establishment of a set of accurate correspondences between points in 3D space. The correspondence problem is generally addressed by the design of discriminative 3D local descriptors on the one hand, and the development of robust matching strategies on the other hand. In this work, we first propose a multi-view local descriptor, which is learned from the images of multiple views, for the description of 3D keypoints. Then, we develop a robust matching approach, aiming at rejecting outlier matches based on the efficient inference via belief propagation on the defined graphical model. We have demonstrated the boost of our approaches to registration on the public scanning and multi-view stereo datasets. The superior performance has been verified by the intensive comparisons against a variety of descriptors and matching methods.
Parallel Structure from Motion from Local Increment to Global Averaging
Jun 05, 2017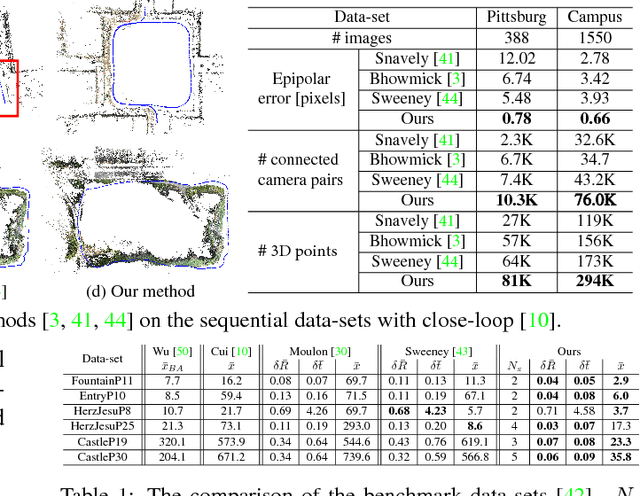

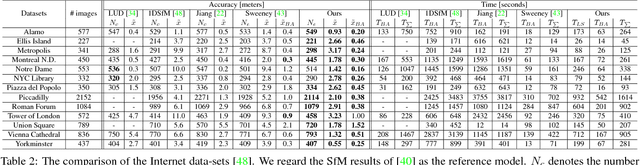
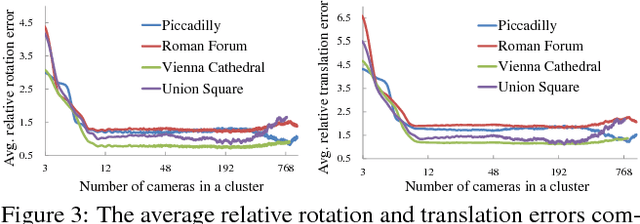
In this paper, we tackle the accurate and consistent Structure from Motion (SfM) problem, in particular camera registration, far exceeding the memory of a single computer in parallel. Different from the previous methods which drastically simplify the parameters of SfM and sacrifice the accuracy of the final reconstruction, we try to preserve the connectivities among cameras by proposing a camera clustering algorithm to divide a large SfM problem into smaller sub-problems in terms of camera clusters with overlapping. We then exploit a hybrid formulation that applies the relative poses from local incremental SfM into a global motion averaging framework and produce accurate and consistent global camera poses. Our scalable formulation in terms of camera clusters is highly applicable to the whole SfM pipeline including track generation, local SfM, 3D point triangulation and bundle adjustment. We are even able to reconstruct the camera poses of a city-scale data-set containing more than one million high-resolution images with superior accuracy and robustness evaluated on benchmark, Internet, and sequential data-sets.