 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking with Slot Constraints
Oct 27, 2023We introduce the problem of ranking with slot constraints, which can be used to model a wide range of application problems -- from college admission with limited slots for different majors, to composing a stratified cohort of eligible participants in a medical trial. We show that the conventional Probability Ranking Principle (PRP) can be highly sub-optimal for slot-constrained ranking problems, and we devise a new ranking algorithm, called MatchRank. The goal of MatchRank is to produce rankings that maximize the number of filled slots if candidates are evaluated by a human decision maker in the order of the ranking. In this way, MatchRank generalizes the PRP, and it subsumes the PRP as a special case when there are no slot constraints. Our theoretical analysis shows that MatchRank has a strong approximation guarantee without any independence assumptions between slots or candidates. Furthermore, we show how MatchRank can be implemented efficiently. Beyond the theoretical guarantees, empirical evaluations show that MatchRank can provide substantial improvements over a range of synthetic and real-world tasks.
GPT as a Baseline for Recommendation Explanation Texts
Sep 16, 2023



In this work, we establish a baseline potential for how modern model-generated text explanations of movie recommendations may help users, and explore what different components of these text explanations that users like or dislike, especially in contrast to existing human movie reviews. We found that participants gave no significantly different rankings between movies, nor did they give significantly different individual quality scores to reviews of movies that they had never seen before. However, participants did mark reviews as significantly better when they were movies they had seen before. We also explore specific aspects of movie review texts that participants marked as important for each quality. Overall, we establish that modern LLMs are a promising source of recommendation explanations, and we intend on further exploring personalizable text explanations in the future.
Fair Ranking under Disparate Uncertainty
Sep 04, 2023Ranking is a ubiquitous method for focusing the attention of human evaluators on a manageable subset of options. Its use ranges from surfacing potentially relevant products on an e-commerce site to prioritizing college applications for human review. While ranking can make human evaluation far more effective by focusing attention on the most promising options, we argue that it can introduce unfairness if the uncertainty of the underlying relevance model differs between groups of options. Unfortunately, such disparity in uncertainty appears widespread, since the relevance estimates for minority groups tend to have higher uncertainty due to a lack of data or appropriate features. To overcome this fairness issue, we propose Equal-Opportunity Ranking (EOR) as a new fairness criterion for ranking that provably corrects for the disparity in uncertainty between groups. Furthermore, we present a practical algorithm for computing EOR rankings in time $O(n \log(n))$ and prove its close approximation guarantee to the globally optimal solution. In a comprehensive empirical evaluation on synthetic data, a US Census dataset, and a real-world case study of Amazon search queries, we find that the algorithm reliably guarantees EOR fairness while providing effective rankings.
Ranking with Long-Term Constraints
Jul 10, 2023



The feedback that users provide through their choices (e.g., clicks, purchases) is one of the most common types of data readily available for training search and recommendation algorithms. However, myopically training systems based on choice data may only improve short-term engagement, but not the long-term sustainability of the platform and the long-term benefits to its users, content providers, and other stakeholders. In this paper, we thus develop a new framework in which decision makers (e.g., platform operators, regulators, users) can express long-term goals for the behavior of the platform (e.g., fairness, revenue distribution, legal requirements). These goals take the form of exposure or impact targets that go well beyond individual sessions, and we provide new control-based algorithms to achieve these goals. In particular, the controllers are designed to achieve the stated long-term goals with minimum impact on short-term engagement. Beyond the principled theoretical derivation of the controllers, we evaluate the algorithms on both synthetic and real-world data. While all controllers perform well, we find that they provide interesting trade-offs in efficiency, robustness, and the ability to plan ahead.
Augmenting Holistic Review in University Admission using Natural Language Processing for Essays and Recommendation Letters
Jun 30, 2023


University admission at many highly selective institutions uses a holistic review process, where all aspects of the application, including protected attributes (e.g., race, gender), grades, essays, and recommendation letters are considered, to compose an excellent and diverse class. In this study, we empirically evaluate how influential protected attributes are for predicting admission decisions using a machine learning (ML) model, and in how far textual information (e.g., personal essay, teacher recommendation) may substitute for the loss of protected attributes in the model. Using data from 14,915 applicants to an undergraduate admission office at a selective U.S. institution in the 2022-2023 cycle, we find that the exclusion of protected attributes from the ML model leads to substantially reduced admission-prediction performance. The inclusion of textual information via both a TF-IDF representation and a Latent Dirichlet allocation (LDA) model partially restores model performance, but does not appear to provide a full substitute for admitting a similarly diverse class. In particular, while the text helps with gender diversity, the proportion of URM applicants is severely impacted by the exclusion of protected attributes, and the inclusion of new attributes generated from the textual information does not recover this performance loss.
Off-Policy Evaluation for Large Action Spaces via Conjunct Effect Modeling
May 14, 2023



We study off-policy evaluation (OPE) of contextual bandit policies for large discrete action spaces where conventional importance-weighting approaches suffer from excessive variance. To circumvent this variance issue, we propose a new estimator, called OffCEM, that is based on the conjunct effect model (CEM), a novel decomposition of the causal effect into a cluster effect and a residual effect. OffCEM applies importance weighting only to action clusters and addresses the residual causal effect through model-based reward estimation. We show that the proposed estimator is unbiased under a new condition, called local correctness, which only requires that the residual-effect model preserves the relative expected reward differences of the actions within each cluster. To best leverage the CEM and local correctness, we also propose a new two-step procedure for performing model-based estimation that minimizes bias in the first step and variance in the second step. We find that the resulting OffCEM estimator substantially improves bias and variance compared to a range of conventional estimators. Experiments demonstrate that OffCEM provides substantial improvements in OPE especially in the presence of many actions.
Off-policy evaluation for learning-to-rank via interpolating the item-position model and the position-based model
Oct 15, 2022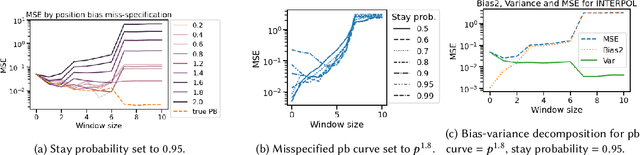
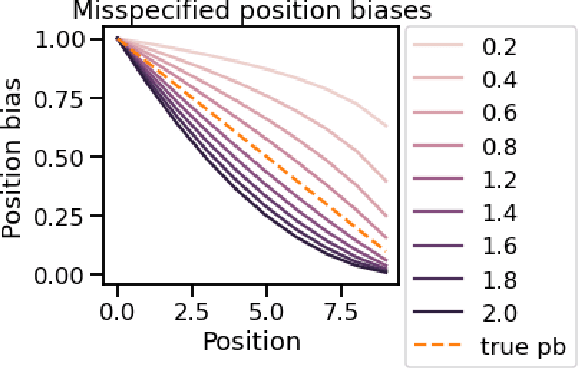
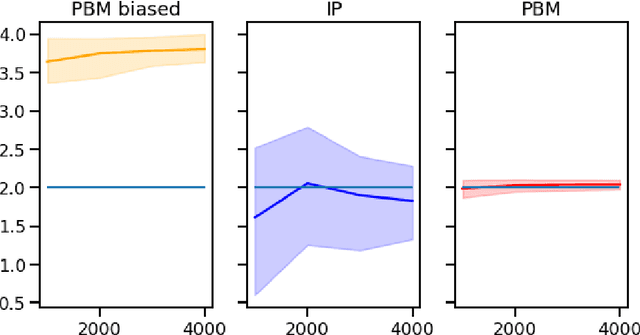
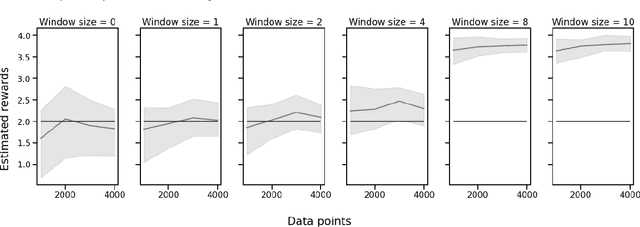
A critical need for industrial recommender systems is the ability to evaluate recommendation policies offline, before deploying them to production. Unfortunately, widely used off-policy evaluation methods either make strong assumptions about how users behave that can lead to excessive bias, or they make fewer assumptions and suffer from large variance. We tackle this problem by developing a new estimator that mitigates the problems of the two most popular off-policy estimators for rankings, namely the position-based model and the item-position model. In particular, the new estimator, called INTERPOL, addresses the bias of a potentially misspecified position-based model, while providing an adaptable bias-variance trade-off compared to the item-position model. We provide theoretical arguments as well as empirical results that highlight the performance of our novel estimation approach.
Boosted Off-Policy Learning
Aug 01, 2022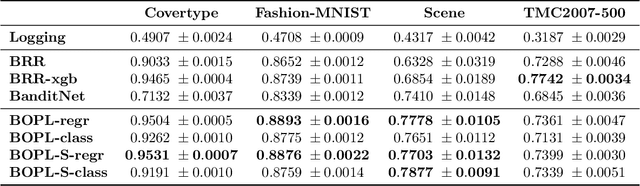
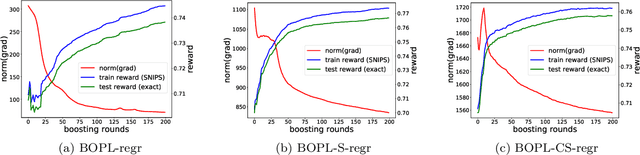


We investigate boosted ensemble models for off-policy learning from logged bandit feedback. Toward this goal, we propose a new boosting algorithm that directly optimizes an estimate of the policy's expected reward. We analyze this algorithm and prove that the empirical risk decreases (possibly exponentially fast) with each round of boosting, provided a "weak" learning condition is satisfied. We further show how the base learner reduces to standard supervised learning problems. Experiments indicate that our algorithm can outperform deep off-policy learning and methods that simply regress on the observed rewards, thereby demonstrating the benefits of both boosting and choosing the right learning objective.
Fair Ranking as Fair Division: Impact-Based Individual Fairness in Ranking
Jun 15, 2022
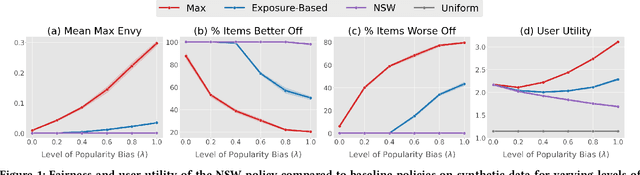
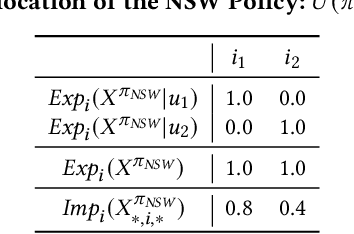
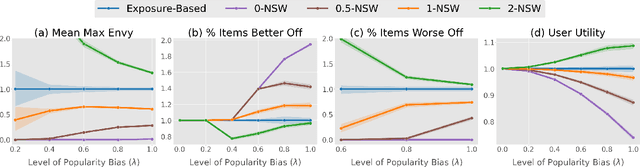
Rankings have become the primary interface in two-sided online markets. Many have noted that the rankings not only affect the satisfaction of the users (e.g., customers, listeners, employers, travelers), but that the position in the ranking allocates exposure -- and thus economic opportunity -- to the ranked items (e.g., articles, products, songs, job seekers, restaurants, hotels). This has raised questions of fairness to the items, and most existing works have addressed fairness by explicitly linking item exposure to item relevance. However, we argue that any particular choice of such a link function may be difficult to defend, and we show that the resulting rankings can still be unfair. To avoid these shortcomings, we develop a new axiomatic approach that is rooted in principles of fair division. This not only avoids the need to choose a link function, but also more meaningfully quantifies the impact on the items beyond exposure. Our axioms of envy-freeness and dominance over uniform ranking postulate that for a fair ranking policy every item should prefer their own rank allocation over that of any other item, and that no item should be actively disadvantaged by the rankings. To compute ranking policies that are fair according to these axioms, we propose a new ranking objective related to the Nash Social Welfare. We show that the solution has guarantees regarding its envy-freeness, its dominance over uniform rankings for every item, and its Pareto optimality. In contrast, we show that conventional exposure-based fairness can produce large amounts of envy and have a highly disparate impact on the items. Beyond these theoretical results, we illustrate empirically how our framework controls the trade-off between impact-based individual item fairness and user utility.
Fairness in the First Stage of Two-Stage Recommender Systems
Jun 02, 2022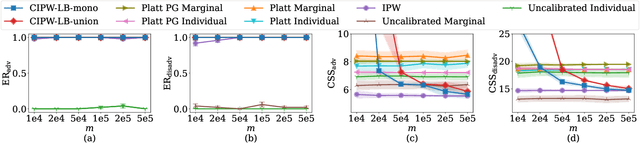
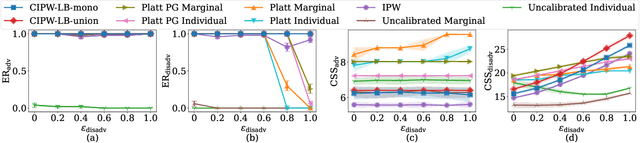


Many large-scale recommender systems consist of two stages, where the first stage focuses on efficiently generating a small subset of promising candidates from a huge pool of items for the second-stage model to curate final recommendations from. In this paper, we investigate how to ensure group fairness to the items in this two-stage paradigm. In particular, we find that existing first-stage recommenders might select an irrecoverably unfair set of candidates such that there is no hope for the second-stage recommender to deliver fair recommendations. To this end, we propose two threshold-policy selection rules that, given any relevance model of queries and items and a point-wise lower confidence bound on the expected number of relevant items for each policy, find near-optimal sets of candidates that contain enough relevant items in expectation from each group of items. To instantiate the rules, we demonstrate how to derive such confidence bounds from potentially partial and biased user feedback data, which are abundant in many large-scale recommender systems. In addition, we provide both finite-sample and asymptotic analysis of how close the two threshold selection rules are to the optimal thresholds. Beyond this theoretical analysis, we show empirically that these two rules can consistently select enough relevant items from each group while minimizing the size of the candidate sets for a wide range of settings.