 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Informed Probabilistic Contact Search for Multi-Finger Manipulation
Oct 01, 2024



Planning contact-rich interactions for multi-finger manipulation is challenging due to the high-dimensionality and hybrid nature of dynamics. Recent advances in data-driven methods have shown promise, but are sensitive to the quality of training data. Combining learning with classical methods like trajectory optimization and search adds additional structure to the problem and domain knowledge in the form of constraints, which can lead to outperforming the data on which models are trained. We present Diffusion-Informed Probabilistic Contact Search (DIPS), which uses an A* search to plan a sequence of contact modes informed by a diffusion model. We train the diffusion model on a dataset of demonstrations consisting of contact modes and trajectories generated by a trajectory optimizer given those modes. In addition, we use a particle filter-inspired method to reason about variability in diffusion sampling arising from model error, estimating likelihoods of trajectories using a learned discriminator. We show that our method outperforms ablations that do not reason about variability and can plan contact sequences that outperform those found in training data across multiple tasks. We evaluate on simulated tabletop card sliding and screwdriver turning tasks, as well as the screwdriver task in hardware to show that our combined learning and planning approach transfers to the real world.
Multi-finger Manipulation via Trajectory Optimization with Differentiable Rolling and Geometric Constraints
Aug 23, 2024Parameterizing finger rolling and finger-object contacts in a differentiable manner is important for formulating dexterous manipulation as a trajectory optimization problem. In contrast to previous methods which often assume simplified geometries of the robot and object or do not explicitly model finger rolling, we propose a method to further extend the capabilities of dexterous manipulation by accounting for non-trivial geometries of both the robot and the object. By integrating the object's Signed Distance Field (SDF) with a sampling method, our method estimates contact and rolling-related variables and includes those in a trajectory optimization framework. This formulation naturally allows for the emergence of finger-rolling behaviors, enabling the robot to locally adjust the contact points. Our method is tested in a peg alignment task and a screwdriver turning task, where it outperforms the baselines in terms of achieving desired object configurations and avoiding dropping the object. We also successfully apply our method to a real-world screwdriver turning task, demonstrating its robustness to the sim2real gap.
Constrained Stein Variational Trajectory Optimization
Aug 23, 2023We present Constrained Stein Variational Trajectory Optimization (CSVTO), an algorithm for performing trajectory optimization with constraints on a set of trajectories in parallel. We frame constrained trajectory optimization as a novel form of constrained functional minimization over trajectory distributions, which avoids treating the constraints as a penalty in the objective and allows us to generate diverse sets of constraint-satisfying trajectories. Our method uses Stein Variational Gradient Descent (SVGD) to find a set of particles that approximates a distribution over low-cost trajectories while obeying constraints. CSVTO is applicable to problems with arbitrary equality and inequality constraints and includes a novel particle resampling step to escape local minima. By explicitly generating diverse sets of trajectories, CSVTO is better able to avoid poor local minima and is more robust to initialization. We demonstrate that CSVTO outperforms baselines in challenging highly-constrained tasks, such as a 7DoF wrench manipulation task, where CSVTO succeeds in 20/20 trials vs 13/20 for the closest baseline. Our results demonstrate that generating diverse constraint-satisfying trajectories improves robustness to disturbances and initialization over baselines.
Variational Inference MPC using Normalizing Flows and Out-of-Distribution Projection
May 10, 2022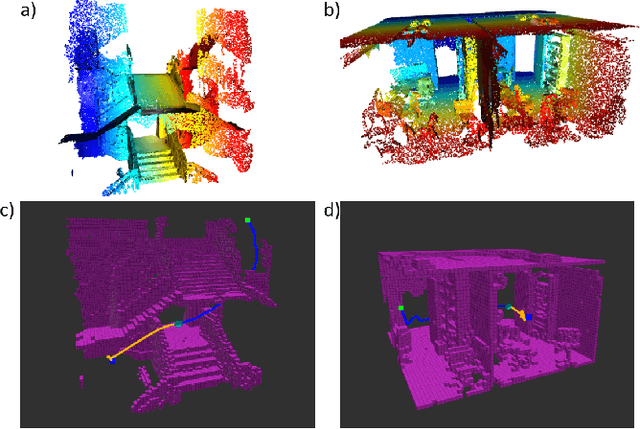
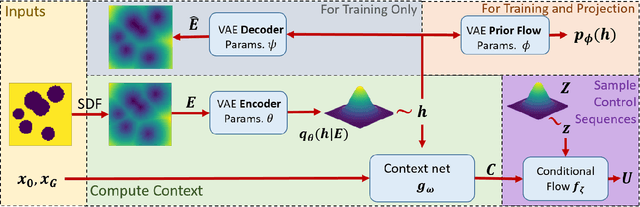
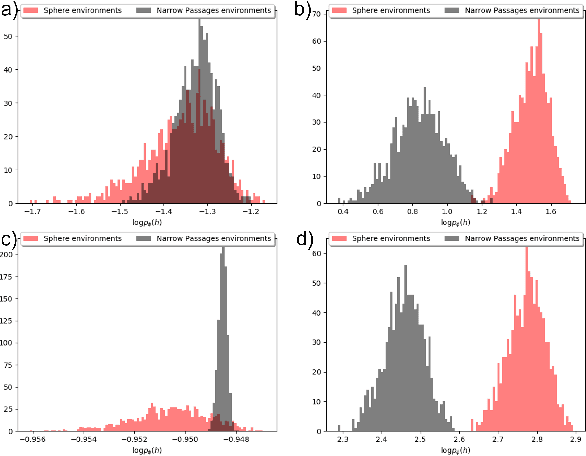
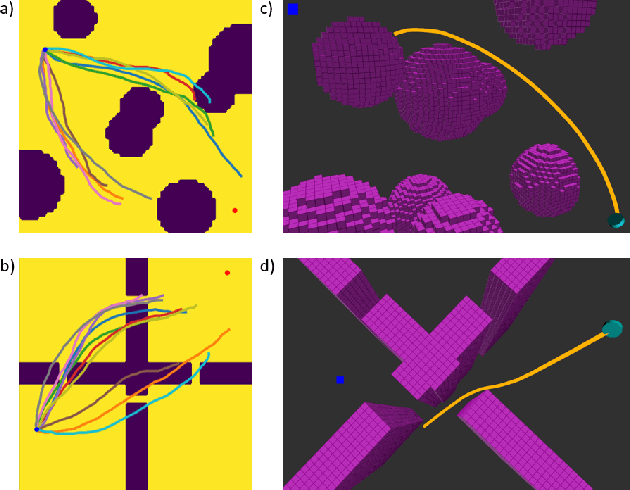
We propose a Model Predictive Control (MPC) method for collision-free navigation that uses amortized variational inference to approximate the distribution of optimal control sequences by training a normalizing flow conditioned on the start, goal and environment. This representation allows us to learn a distribution that accounts for both the dynamics of the robot and complex obstacle geometries. We can then sample from this distribution to produce control sequences which are likely to be both goal-directed and collision-free as part of our proposed FlowMPPI sampling-based MPC method. However, when deploying this method, the robot may encounter an out-of-distribution (OOD) environment, i.e. one which is radically different from those used in training. In such cases, the learned flow cannot be trusted to produce low-cost control sequences. To generalize our method to OOD environments we also present an approach that performs projection on the representation of the environment as part of the MPC process. This projection changes the environment representation to be more in-distribution while also optimizing trajectory quality in the true environment. Our simulation results on a 2D double-integrator and a 3D 12DoF underactuated quadrotor suggest that FlowMPPI with projection outperforms state-of-the-art MPC baselines on both in-distribution and OOD environments, including OOD environments generated from real-world data.
Keep it Simple: Data-efficient Learning for Controlling Complex Systems with Simple Models
Feb 17, 2021
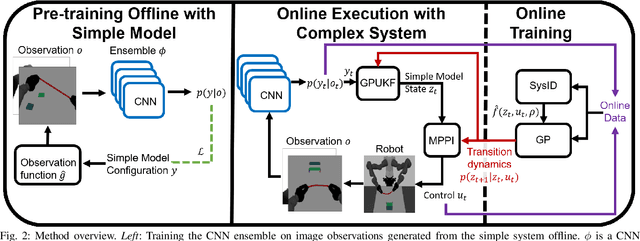


When manipulating a novel object with complex dynamics, a state representation is not always available, for example for deformable objects. Learning both a representation and dynamics from observations requires large amounts of data. We propose Learned Visual Similarity Predictive Control (LVSPC), a novel method for data-efficient learning to control systems with complex dynamics and high-dimensional state spaces from images. LVSPC leverages a given simple model approximation from which image observations can be generated. We use these images to train a perception model that estimates the simple model state from observations of the complex system online. We then use data from the complex system to fit the parameters of the simple model and learn where this model is inaccurate, also online. Finally, we use Model Predictive Control and bias the controller away from regions where the simple model is inaccurate and thus where the controller is less reliable. We evaluate LVSPC on two tasks; manipulating a tethered mass and a rope. We find that our method performs comparably to state-of-the-art reinforcement learning methods with an order of magnitude less data. LVSPC also completes the rope manipulation task on a real robot with 80% success rate after only 10 trials, despite using a perception system trained only on images from simulation.
Learning When to Trust a Dynamics Model for Planning in Reduced State Spaces
Jan 29, 2020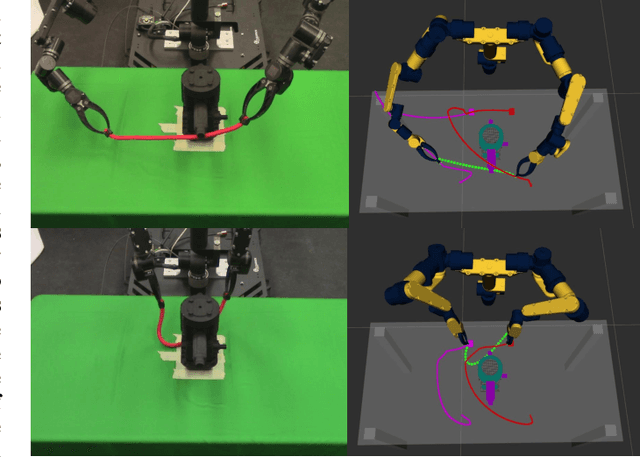
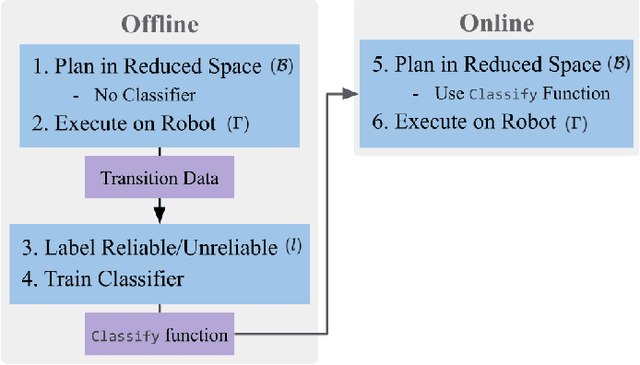
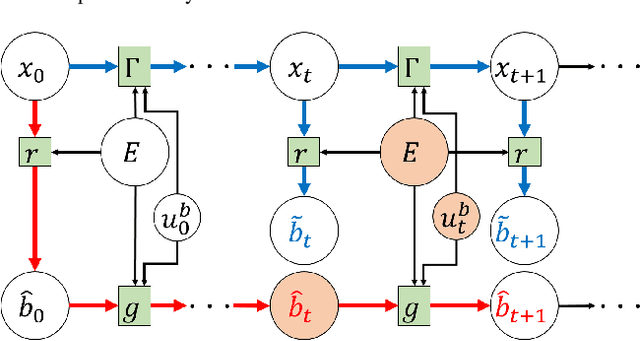
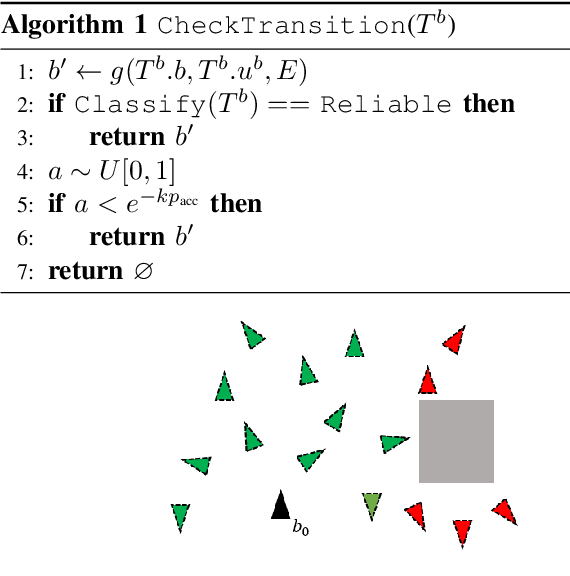
When the dynamics of a system are difficult to model and/or time-consuming to evaluate, such as in deformable object manipulation tasks, motion planning algorithms struggle to find feasible plans efficiently. Such problems are often reduced to state spaces where the dynamics are straightforward to model and evaluate. However, such reductions usually discard information about the system for the benefit of computational efficiency, leading to cases where the true and reduced dynamics disagree on the result of an action. This paper presents a formulation for planning in reduced state spaces that uses a classifier to bias the planner away from state-action pairs that are not reliably feasible under the true dynamics. We present a method to generate and label data to train such a classifier, as well as an application of our framework to rope manipulation, where we use a Virtual Elastic Band (VEB) approximation to the true dynamics. Our experiments with rope manipulation demonstrate that the classifier significantly improves the success rate of our RRT-based planner in several difficult scenarios which are designed to cause the VEB to produce incorrect predictions in key parts of the environment.