 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Argument Left Behind: Overlapping Chunks for Faster Processing of Arbitrarily Long Legal Texts
Oct 24, 2024



In a context where the Brazilian judiciary system, the largest in the world, faces a crisis due to the slow processing of millions of cases, it becomes imperative to develop efficient methods for analyzing legal texts. We introduce uBERT, a hybrid model that combines Transformer and Recurrent Neural Network architectures to effectively handle long legal texts. Our approach processes the full text regardless of its length while maintaining reasonable computational overhead. Our experiments demonstrate that uBERT achieves superior performance compared to BERT+LSTM when overlapping input is used and is significantly faster than ULMFiT for processing long legal documents.
Enriching GNNs with Text Contextual Representations for Detecting Disinformation Campaigns on Social Media
Oct 24, 2024


Disinformation on social media poses both societal and technical challenges. While previous studies have integrated textual information into propagation networks, they have yet to fully leverage the advancements in Transformer-based language models for high-quality contextual text representations. This work investigates the impact of incorporating textual features into Graph Neural Networks (GNNs) for fake news detection. Our experiments demonstrate that contextual representations improve performance by 9.3% in Macro F1 over static ones and 33.8% over GNNs without textual features. However, noisy data augmentation degrades performance and increases instability. We expect our methodology to open avenues for further research, and all code is made publicly available.
LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints
Oct 09, 2024



Instruction following is a key capability for LLMs. However, recent studies have shown that LLMs often struggle with instructions containing multiple constraints (e.g. a request to create a social media post "in a funny tone" with "no hashtag"). Despite this, most evaluations focus solely on synthetic data. To address this, we introduce RealInstruct, the first benchmark designed to evaluate LLMs' ability to follow real-world multi-constrained instructions by leveraging queries real users asked AI assistants. We also investigate model-based evaluation as a cost-effective alternative to human annotation for this task. Our findings reveal that even the proprietary GPT-4 model fails to meet at least one constraint on over 21% of instructions, highlighting the limitations of state-of-the-art models. To address the performance gap between open-source and proprietary models, we propose the Decompose, Critique and Refine (DeCRIM) self-correction pipeline, which enhances LLMs' ability to follow constraints. DeCRIM works by decomposing the original instruction into a list of constraints and using a Critic model to decide when and where the LLM's response needs refinement. Our results show that DeCRIM improves Mistral's performance by 7.3% on RealInstruct and 8.0% on IFEval even with weak feedback. Moreover, we demonstrate that with strong feedback, open-source LLMs with DeCRIM can outperform GPT-4 on both benchmarks.
Efficient Compression of Multitask Multilingual Speech Models
May 02, 2024



Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
From Random to Informed Data Selection: A Diversity-Based Approach to Optimize Human Annotation and Few-Shot Learning
Jan 24, 2024A major challenge in Natural Language Processing is obtaining annotated data for supervised learning. An option is the use of crowdsourcing platforms for data annotation. However, crowdsourcing introduces issues related to the annotator's experience, consistency, and biases. An alternative is to use zero-shot methods, which in turn have limitations compared to their few-shot or fully supervised counterparts. Recent advancements driven by large language models show potential, but struggle to adapt to specialized domains with severely limited data. The most common approaches therefore involve the human itself randomly annotating a set of datapoints to build initial datasets. But randomly sampling data to be annotated is often inefficient as it ignores the characteristics of the data and the specific needs of the model. The situation worsens when working with imbalanced datasets, as random sampling tends to heavily bias towards the majority classes, leading to excessive annotated data. To address these issues, this paper contributes an automatic and informed data selection architecture to build a small dataset for few-shot learning. Our proposal minimizes the quantity and maximizes diversity of data selected for human annotation, while improving model performance.
DistilWhisper: Efficient Distillation of Multi-task Speech Models via Language-Specific Experts
Nov 02, 2023



Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still under-performs on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we propose DistilWhisper, an approach able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
Science and engineering for what? A large-scale analysis of students' projects in science fairs
Aug 05, 2023



Science and Engineering fairs offer K-12 students opportunities to engage with authentic STEM practices. Particularly, students are given the chance to experience authentic and open inquiry processes, by defining which themes, questions and approaches will guide their scientific endeavors. In this study, we analyzed data from over 5,000 projects presented at a nationwide science fair in Brazil over the past 20 years using topic modeling to identify the main topics that have driven students' inquiry and design. Our analysis identified a broad range of topics being explored, with significant variations over time, region, and school setting. We argue those results and proposed methodology can not only support further research in the context of science fairs, but also inform instruction and design of contexts-specific resources to support students in open inquiry experiences in different settings.
ZeroBERTo -- Leveraging Zero-Shot Text Classification by Topic Modeling
Jan 04, 2022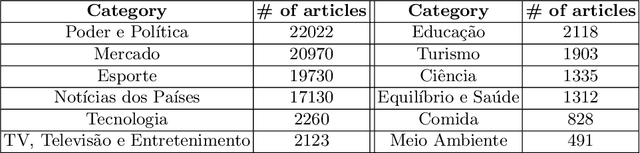

Traditional text classification approaches often require a good amount of labeled data, which is difficult to obtain, especially in restricted domains or less widespread languages. This lack of labeled data has led to the rise of low-resource methods, that assume low data availability in natural language processing. Among them, zero-shot learning stands out, which consists of learning a classifier without any previously labeled data. The best results reported with this approach use language models such as Transformers, but fall into two problems: high execution time and inability to handle long texts as input. This paper proposes a new model, ZeroBERTo, which leverages an unsupervised clustering step to obtain a compressed data representation before the classification task. We show that ZeroBERTo has better performance for long inputs and shorter execution time, outperforming XLM-R by about 12% in the F1 score in the FolhaUOL dataset. Keywords: Low-Resource NLP, Unlabeled data, Zero-Shot Learning, Topic Modeling, Transformers.
DEBACER: a method for slicing moderated debates
Dec 10, 2021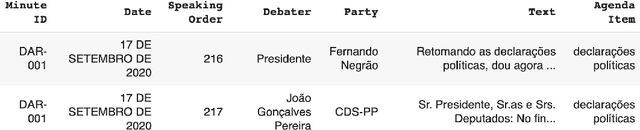
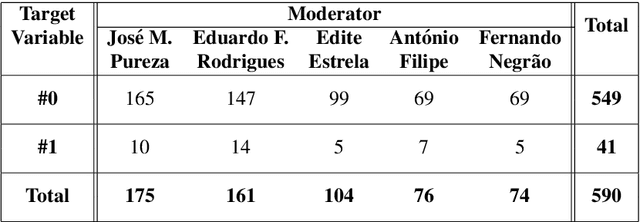
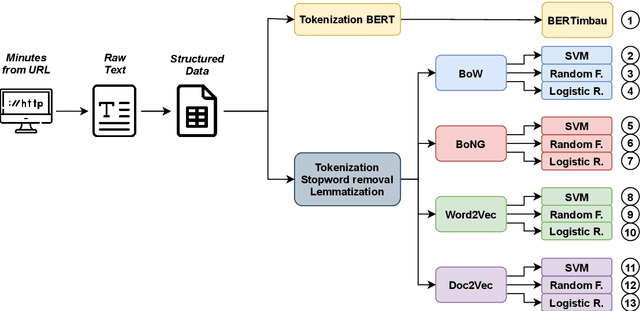
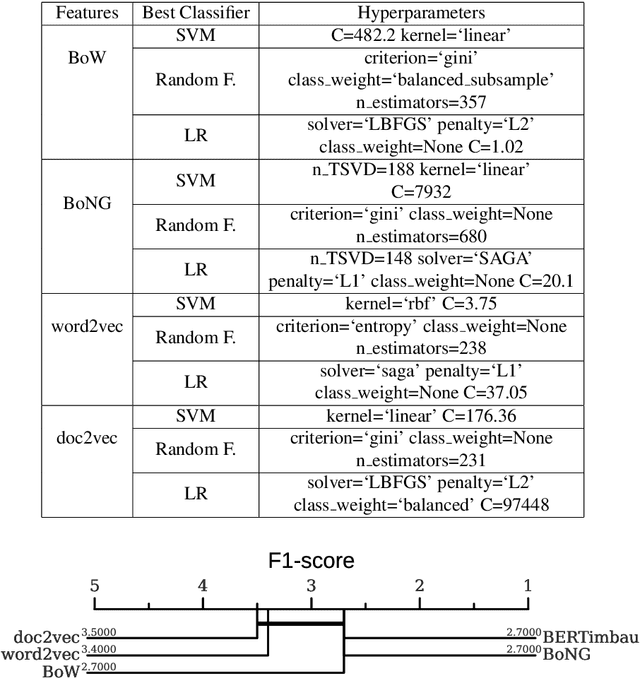
Subjects change frequently in moderated debates with several participants, such as in parliamentary sessions, electoral debates, and trials. Partitioning a debate into blocks with the same subject is essential for understanding. Often a moderator is responsible for defining when a new block begins so that the task of automatically partitioning a moderated debate can focus solely on the moderator's behavior. In this paper, we (i) propose a new algorithm, DEBACER, which partitions moderated debates; (ii) carry out a comparative study between conventional and BERTimbau pipelines; and (iii) validate DEBACER applying it to the minutes of the Assembly of the Republic of Portugal. Our results show the effectiveness of DEBACER. Keywords: Natural Language Processing, Political Documents, Spoken Text Processing, Speech Split, Dialogue Partitioning.
* Accepted on The 18th National Meeting on Artificial and Computational Intelligence (ENIAC 2021)