 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Temporal Graph Neural Networks via Feature-induced Information Flow
Jun 25, 2026Event-based Temporal Graph Neural Networks (ETGNNs) have demonstrated strong performance across a wide range of applications, including social network analysis, epidemic tracing, recommender systems, and political event forecasting. However, their increasing complexity poses significant challenges for explainability. Existing explanation methods focus only on a subset of the information flow within ETGNNs, typically tracing contributions from the event-related embeddings to the output. Consequently, they overlook the important pathways through event-induced variables, which mediate interactions between nodes and thereby play a central role in capturing long-range temporal dependencies. To overcome this limitation, we propose a novel attribution method that analyzes the \emph{entire} information flow through all event-associated variables. Our method is built upon the recent Normalized Relevance Measure (NRM) framework, which enables explicit quantification of information flow originating from event embeddings as well as information flow passing through event-induced variables. It also ensures comparability of latent variables across layers, and supports higher-order analysis of interactions between events. To handle the architectural complexity of ETGNNs, we extend the NRM framework with a modular decomposition procedure that facilitates the systematic construction of relevance structure for complex neural architectures. We evaluate our approach on two synthetic datasets for epidemic tracing and social dynamics, as well as a real-world dataset of political event networks. Our qualitative and quantitative experiments show that our method consistently outperforms existing explanation approaches while producing more human-interpretable explanations.
Symb-xMIL: Symbolic Explanations for Multiple Instance Learning in Digital Pathology
Jun 04, 2026Explanations of multiple instance learning (MIL) models are widely used for validation and discovery in digital histopathology. Existing methods primarily rely on heatmaps that highlight influential regions but do not explain how evidence from different tissue regions is combined to produce a prediction. This limits interpretability, especially when decisions depend on interactions between tissue features. We introduce Symbolic explainable MIL (Symb-xMIL), a post-hoc explanation framework that quantifies how a MIL model's behavior aligns with human-readable decision rules, expressed as logical relationships (e.g., AND, OR, NOT) between input features. These alignment scores reveal semantic patterns underlying the model's predictions. We evaluate Symb-xMIL on synthetic and real-world histopathology datasets. On synthetic MIL data, Symb-xMIL reliably recovers ground-truth logical rules. In a clinical tumor detection task, the best-aligned rules uncover heterogeneous decision patterns and expose hidden model errors. On an HPV-prediction task on TCGA-HNSCC, a cohort of head and neck cancer, our framework refines patient survival stratification beyond HPV status with potential clinical relevance. Overall, Symb-xMIL extends MIL explainability beyond visual attribution toward structured, rule-based reasoning, enabling more transparent and semantically grounded interpretation of model predictions.
Normalized Relevance Measure as a Unifying Framework to Explain Neural Network Latent Structures
May 30, 2026To understand how a neural network (NN) functions and makes predictions, it has become increasingly clear that analyzing only the input domain is insufficient -- one must also examine its internal inference mechanisms to capture the complete picture. To explain the internal inference mechanisms of such models, it is essential to analyze the importance of latent representations for a given task. In this paper, we propose the \emph{normalized relevance measure} (NRM) framework -- a novel general explanation procedure that attributes relevance to \emph{arbitrary sets of neurons across layers of arbitrary architectures}. In the NRM framework, relevance of selected neurons is explicitly defined as a normalized signed measure, constructed using simple operations -- marginalization and conditioning based on additive and multiplicative laws -- in analogy to the probability measures. The normalization property further guarantees comparability across layers. The NRM framework subsumes existing propagation-based explanation algorithms by explicitly identifying the underlying quantity being computed. We demonstrate the utility of the framework in computer vision applications, where joint relevance analysis across multiple layers reveals key information flows in VGG16 networks. Overall, the NRM framework provides a general, mathematically grounded approach to understanding how modern NNs propagate information, offering a versatile and broadly applicable foundation for explainable artificial intelligence.
Relevant Walk Search for Explaining Graph Neural Networks
May 22, 2026Graph Neural Networks (GNNs) have become important machine learning tools for graph analysis, and its explainability is crucial for safety, fairness, and robustness. Layer-wise relevance propagation for GNNs (GNN-LRP) evaluates the relevance of \emph{walks} to reveal important information flows in the network, and provides higher-order explanations, which have been shown to be superior to the lower-order, i.e., node-/edge-level, explanations. However, identifying relevant walks by GNN-LRP requires {\em exponential} computational complexity with respect to the network depth, which we will remedy in this paper. Specifically, we propose {\em polynomial-time} algorithms for finding top-$K$ relevant walks, which drastically reduces the computation and thus increases the applicability of GNN-LRP to large-scale problems. Our proposed algorithms are based on the \emph{max-product} algorithm -- a common tool for finding the maximum likelihood configurations in probabilistic graphical models -- and can find the most relevant walks exactly at the neuron level and approximately at the node level. Our experiments demonstrate the performance of our algorithms at scale and their utility across application domains, i.e., on epidemiology, molecular, and natural language benchmarks. We provide our codes under \href{https://github.com/xiong-ping/rel_walk_gnnlrp}{github.com/xiong-ping/rel\_walk\_gnnlrp}.
* Published in ICML 2023
Efficient Higher-order Subgraph Attribution via Message Passing
May 21, 2026Explaining graph neural networks (GNNs) has become more and more important recently. Higher-order interpretation schemes, such as GNN-LRP (layer-wise relevance propagation for GNN), emerged as powerful tools for unraveling how different features interact thereby contributing to explaining GNNs. GNN-LRP gives a relevance attribution of walks between nodes at each layer, and the subgraph attribution is expressed as a sum over exponentially many such walks. In this work, we demonstrate that such exponential complexity can be avoided. In particular, we propose novel algorithms that enable to attribute subgraphs with GNN-LRP in linear-time (w.r.t. the network depth). Our algorithms are derived via message passing techniques that make use of the distributive property, thereby directly computing quantities for higher-order explanations. We further adapt our efficient algorithms to compute a generalization of subgraph attributions that also takes into account the neighboring graph features. Experimental results show the significant acceleration of the proposed algorithms and demonstrate the high usefulness and scalability of our novel generalized subgraph attribution method.
* Published in ICML 2022
Beyond Attention Heatmaps: How to Get Better Explanations for Multiple Instance Learning Models in Histopathology
Mar 09, 2026Multiple instance learning (MIL) has enabled substantial progress in computational histopathology, where a large amount of patches from gigapixel whole slide images are aggregated into slide-level predictions. Heatmaps are widely used to validate MIL models and to discover tissue biomarkers. Yet, the validity of these heatmaps has barely been investigated. In this work, we introduce a general framework for evaluating the quality of MIL heatmaps without requiring additional labels. We conduct a large-scale benchmark experiment to assess six explanation methods across histopathology task types (classification, regression, survival), MIL model architectures (Attention-, Transformer-, Mamba-based), and patch encoder backbones (UNI2, Virchow2). Our results show that explanation quality mostly depends on MIL model architecture and task type, with perturbation ("Single"), layer-wise relevance propagation (LRP), and integrated gradients (IG) consistently outperforming attention-based and gradient-based saliency heatmaps, which often fail to reflect model decision mechanisms. We further demonstrate the advanced capabilities of the best-performing explanation methods: (i) We provide a proof-of-concept that MIL heatmaps of a bulk gene expression prediction model can be correlated with spatial transcriptomics for biological validation, and (ii) showcase the discovery of distinct model strategies for predicting human papillomavirus (HPV) infection from head and neck cancer slides. Our work highlights the importance of validating MIL heatmaps and establishes that improved explainability can enable more reliable model validation and yield biological insights, making a case for a broader adoption of explainable AI in digital pathology. Our code is provided in a public GitHub repository: https://github.com/bifold-pathomics/xMIL/tree/xmil-journal
Uncovering the Structure of Explanation Quality with Spectral Analysis
Apr 11, 2025As machine learning models are increasingly considered for high-stakes domains, effective explanation methods are crucial to ensure that their prediction strategies are transparent to the user. Over the years, numerous metrics have been proposed to assess quality of explanations. However, their practical applicability remains unclear, in particular due to a limited understanding of which specific aspects each metric rewards. In this paper we propose a new framework based on spectral analysis of explanation outcomes to systematically capture the multifaceted properties of different explanation techniques. Our analysis uncovers two distinct factors of explanation quality-stability and target sensitivity-that can be directly observed through spectral decomposition. Experiments on both MNIST and ImageNet show that popular evaluation techniques (e.g., pixel-flipping, entropy) partially capture the trade-offs between these factors. Overall, our framework provides a foundational basis for understanding explanation quality, guiding the development of more reliable techniques for evaluating explanations.
Towards Symbolic XAI -- Explanation Through Human Understandable Logical Relationships Between Features
Aug 30, 2024Explainable Artificial Intelligence (XAI) plays a crucial role in fostering transparency and trust in AI systems, where traditional XAI approaches typically offer one level of abstraction for explanations, often in the form of heatmaps highlighting single or multiple input features. However, we ask whether abstract reasoning or problem-solving strategies of a model may also be relevant, as these align more closely with how humans approach solutions to problems. We propose a framework, called Symbolic XAI, that attributes relevance to symbolic queries expressing logical relationships between input features, thereby capturing the abstract reasoning behind a model's predictions. The methodology is built upon a simple yet general multi-order decomposition of model predictions. This decomposition can be specified using higher-order propagation-based relevance methods, such as GNN-LRP, or perturbation-based explanation methods commonly used in XAI. The effectiveness of our framework is demonstrated in the domains of natural language processing (NLP), vision, and quantum chemistry (QC), where abstract symbolic domain knowledge is abundant and of significant interest to users. The Symbolic XAI framework provides an understanding of the model's decision-making process that is both flexible for customization by the user and human-readable through logical formulas.
xMIL: Insightful Explanations for Multiple Instance Learning in Histopathology
Jun 06, 2024



Multiple instance learning (MIL) is an effective and widely used approach for weakly supervised machine learning. In histopathology, MIL models have achieved remarkable success in tasks like tumor detection, biomarker prediction, and outcome prognostication. However, MIL explanation methods are still lagging behind, as they are limited to small bag sizes or disregard instance interactions. We revisit MIL through the lens of explainable AI (XAI) and introduce xMIL, a refined framework with more general assumptions. We demonstrate how to obtain improved MIL explanations using layer-wise relevance propagation (LRP) and conduct extensive evaluation experiments on three toy settings and four real-world histopathology datasets. Our approach consistently outperforms previous explanation attempts with particularly improved faithfulness scores on challenging biomarker prediction tasks. Finally, we showcase how xMIL explanations enable pathologists to extract insights from MIL models, representing a significant advance for knowledge discovery and model debugging in digital histopathology.
XAI for Transformers: Better Explanations through Conservative Propagation
Feb 15, 2022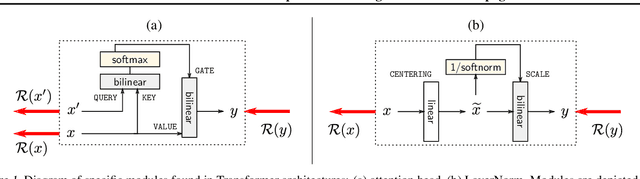
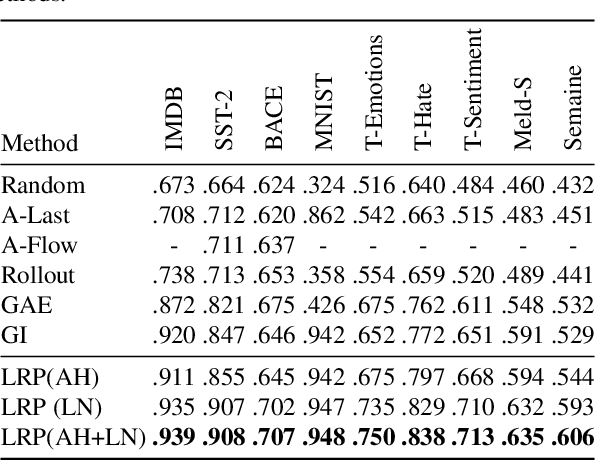
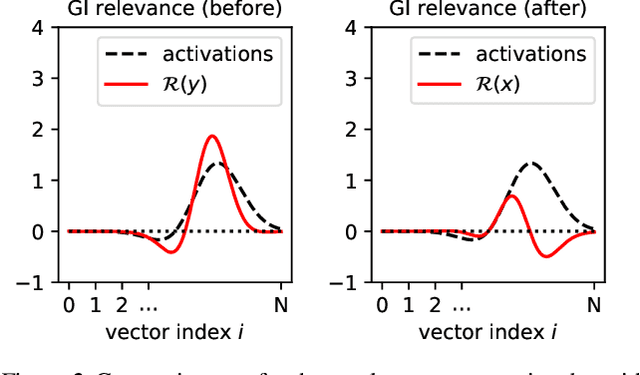
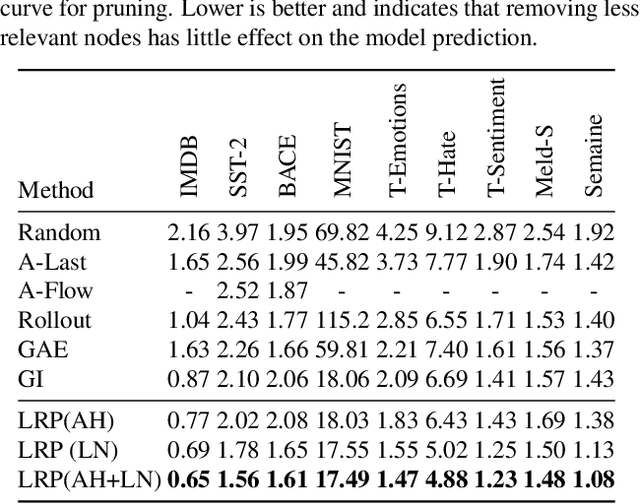
Transformers have become an important workhorse of machine learning, with numerous applications. This necessitates the development of reliable methods for increasing their transparency. Multiple interpretability methods, often based on gradient information, have been proposed. We show that the gradient in a Transformer reflects the function only locally, and thus fails to reliably identify the contribution of input features to the prediction. We identify Attention Heads and LayerNorm as main reasons for such unreliable explanations and propose a more stable way for propagation through these layers. Our proposal, which can be seen as a proper extension of the well-established LRP method to Transformers, is shown both theoretically and empirically to overcome the deficiency of a simple gradient-based approach, and achieves state-of-the-art explanation performance on a broad range of Transformer models and datasets.