 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Optimal Control Approach to Early Stopping Variational Methods for Image Restoration
Jul 19, 2019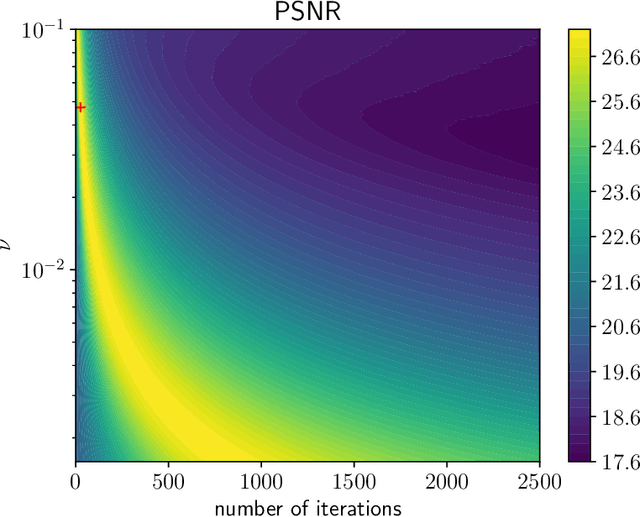
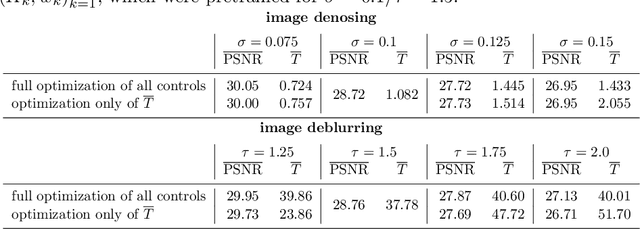
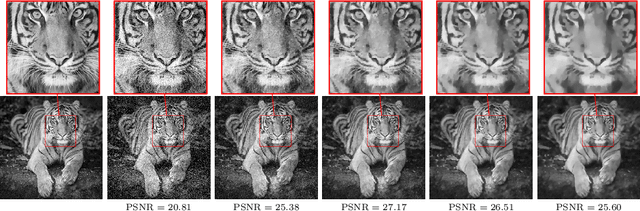
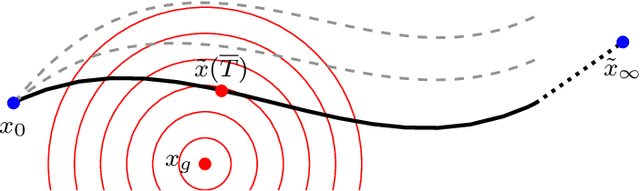
We investigate a well-known phenomenon of variational approaches in image processing, where typically the best image quality is achieved when the gradient flow process is stopped before converging to a stationary point. This paradox originates from a tradeoff between optimization and modelling errors of the underlying variational model and holds true even if deep learning methods are used to learn highly expressive regularizers from data. In this paper, we take advantage of this paradox and introduce an optimal stopping time into the gradient flow process, which in turn is learned from data by means of an optimal control approach. As a result, we obtain highly efficient numerical schemes that achieve competitive results for image denoising and image deblurring. A nonlinear spectral analysis of the gradient of the learned regularizer gives enlightening insights about the different regularization properties.
Fast Decomposable Submodular Function Minimization using Constrained Total Variation
May 27, 2019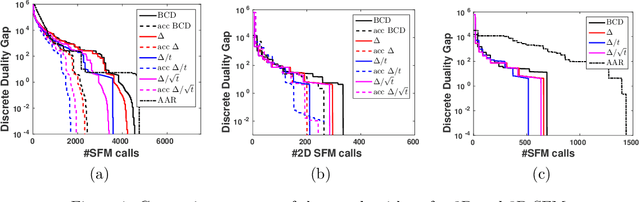
We consider the problem of minimizing the sum of submodular set functions assuming minimization oracles of each summand function. Most existing approaches reformulate the problem as the convex minimization of the sum of the corresponding Lov\'asz extensions and the squared Euclidean norm, leading to algorithms requiring total variation oracles of the summand functions; without further assumptions, these more complex oracles require many calls to the simpler minimization oracles often available in practice. In this paper, we consider a modified convex problem requiring constrained version of the total variation oracles that can be solved with significantly fewer calls to the simple minimization oracles. We support our claims by showing results on graph cuts for 2D and 3D graphs
Convex-Concave Backtracking for Inertial Bregman Proximal Gradient Algorithms in Non-Convex Optimization
Apr 06, 2019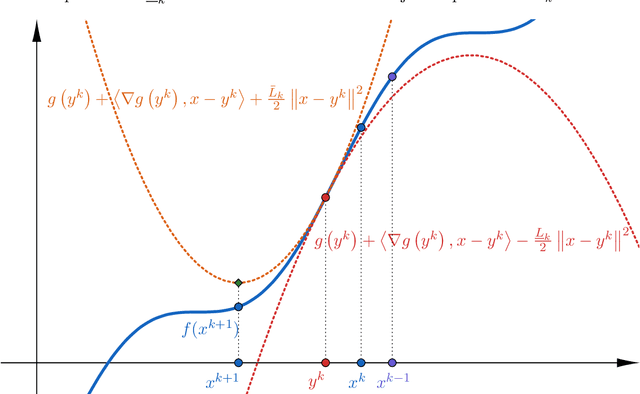
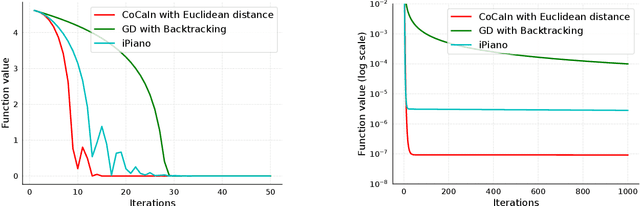
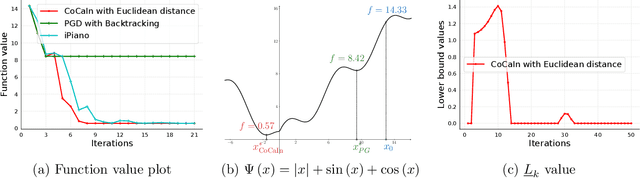
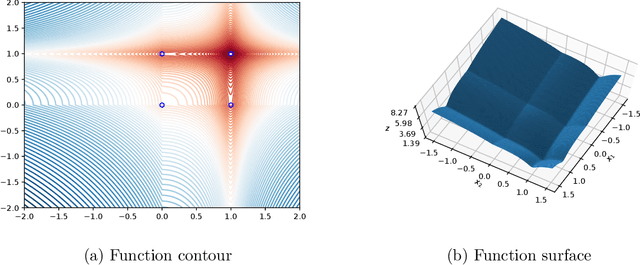
Backtracking line-search is an old yet powerful strategy for finding better step size to be used in proximal gradient algorithms. The main principle is to locally find a simple convex upper bound of the objective function, which in turn controls the step size that is used. In case of inertial proximal gradient algorithms, the situation becomes much more difficult and usually leads to very restrictive rules on the extrapolation parameter. In this paper, we show that the extrapolation parameter can be controlled by locally finding also a simple concave lower bound of the objective function. This gives rise to a double convex-concave backtracking procedure which allows for an adaptive and optimal choice of both the step size and extrapolation parameters. We apply this procedure to the class of inertial Bregman proximal gradient methods, and prove that any sequence generated converges globally to critical points of the function at hand. Numerical experiments on a number of challenging non-convex problems in image processing and machine learning were conducted and show the power of combining inertial step and double backtracking strategy in achieving improved performances.
Deep Learning Methods for Parallel Magnetic Resonance Image Reconstruction
Apr 01, 2019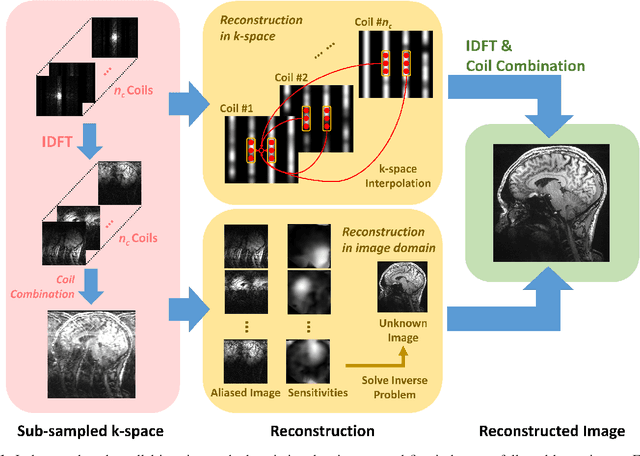
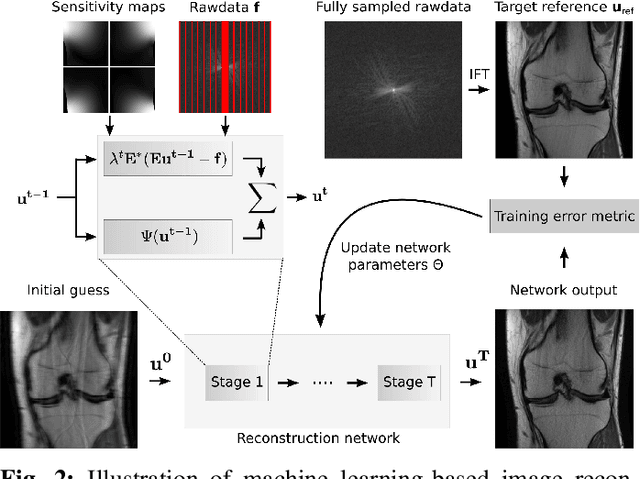
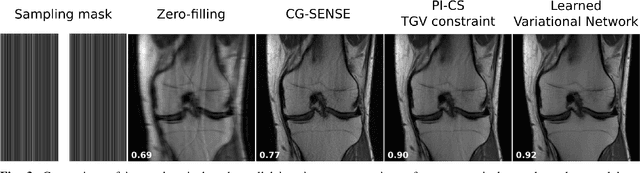
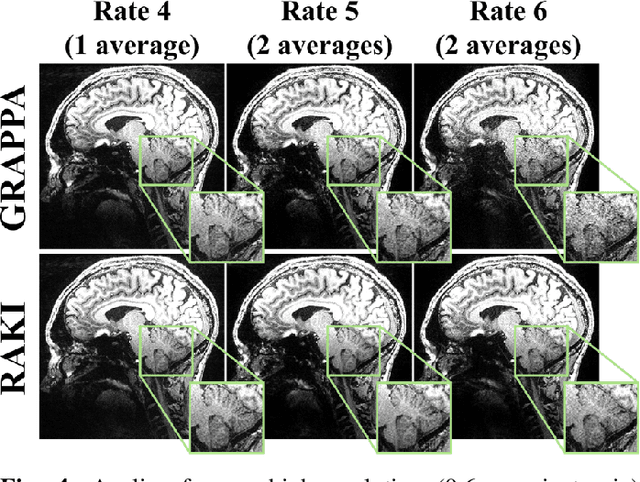
Following the success of deep learning in a wide range of applications, neural network-based machine learning techniques have received interest as a means of accelerating magnetic resonance imaging (MRI). A number of ideas inspired by deep learning techniques from computer vision and image processing have been successfully applied to non-linear image reconstruction in the spirit of compressed sensing for both low dose computed tomography and accelerated MRI. The additional integration of multi-coil information to recover missing k-space lines in the MRI reconstruction process, is still studied less frequently, even though it is the de-facto standard for currently used accelerated MR acquisitions. This manuscript provides an overview of the recent machine learning approaches that have been proposed specifically for improving parallel imaging. A general background introduction to parallel MRI is given that is structured around the classical view of image space and k-space based methods. Both linear and non-linear methods are covered, followed by a discussion of recent efforts to further improve parallel imaging using machine learning, and specifically using artificial neural networks. Image-domain based techniques that introduce improved regularizers are covered as well as k-space based methods, where the focus is on better interpolation strategies using neural networks. Issues and open problems are discussed as well as recent efforts for producing open datasets and benchmarks for the community.
Learning Energy Based Inpainting for Optical Flow
Nov 09, 2018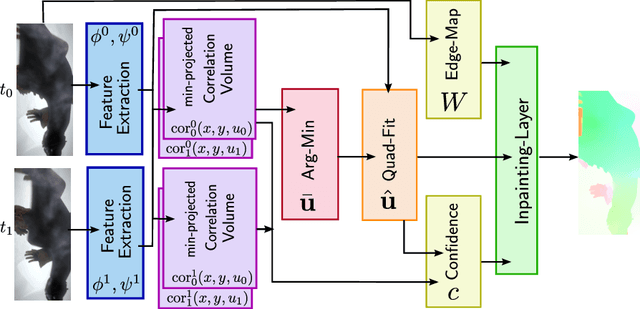
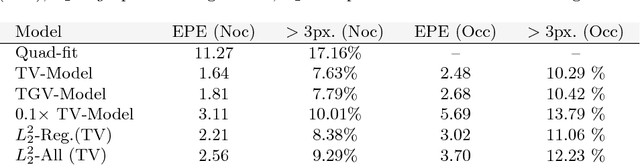


Modern optical flow methods are often composed of a cascade of many independent steps or formulated as a black box neural network that is hard to interpret and analyze. In this work we seek for a plain, interpretable, but learnable solution. We propose a novel inpainting based algorithm that approaches the problem in three steps: feature selection and matching, selection of supporting points and energy based inpainting. To facilitate the inference we propose an optimization layer that allows to backpropagate through 10K iterations of a first-order method without any numerical or memory problems. Compared to recent state-of-the-art networks, our modular CNN is very lightweight and competitive with other, more involved, inpainting based methods.
3D Fluid Flow Estimation with Integrated Particle Reconstruction
Apr 10, 2018
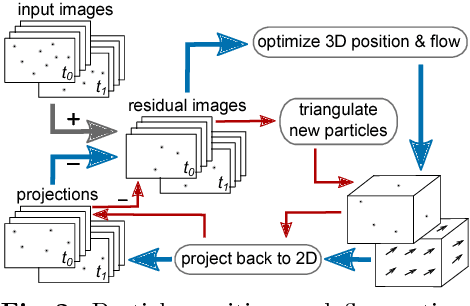

The standard approach to densely reconstruct the motion in a volume of fluid is to inject high-contrast tracer particles and record their motion with multiple high-speed cameras. Almost all existing work processes the acquired multi-view video in two separate steps: first, a per-frame reconstruction of the particles, usually in the form of soft occupancy likelihoods in a voxel representation; followed by 3D motion estimation, with some form of dense matching between the precomputed voxel grids from different time steps. In this sequential procedure, the first step cannot use temporal consistency considerations to support the reconstruction, while the second step has no access to the original, high-resolution image data. We show, for the first time, how to jointly reconstruct both the individual tracer particles and a dense 3D fluid motion field from the image data, using an integrated energy minimization. Our hybrid Lagrangian/Eulerian model explicitly reconstructs individual particles, and at the same time recovers a dense 3D motion field in the entire domain. Making particles explicit greatly reduces the memory consumption and allows one to use the high-resolution input images for matching. Whereas the dense motion field makes it possible to include physical a-priori constraints and account for the incompressibility and viscosity of the fluid. The method exhibits greatly (~70%) improved results over a recent baseline with two separate steps for 3D reconstruction and motion estimation. Our results with only two time steps are comparable to those of state-of-the-art tracking-based methods that require much longer sequences.
Variational 3D-PIV with Sparse Descriptors
Apr 09, 2018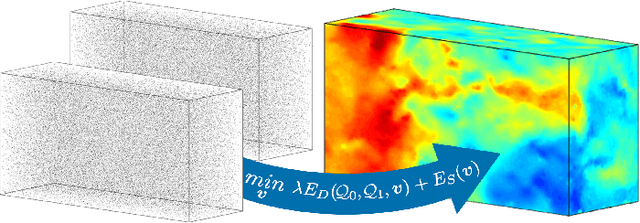
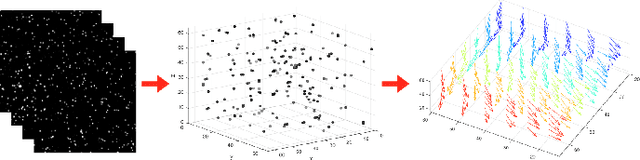
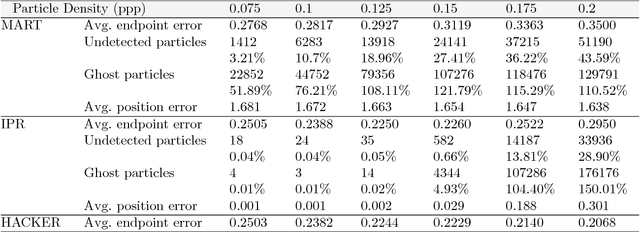
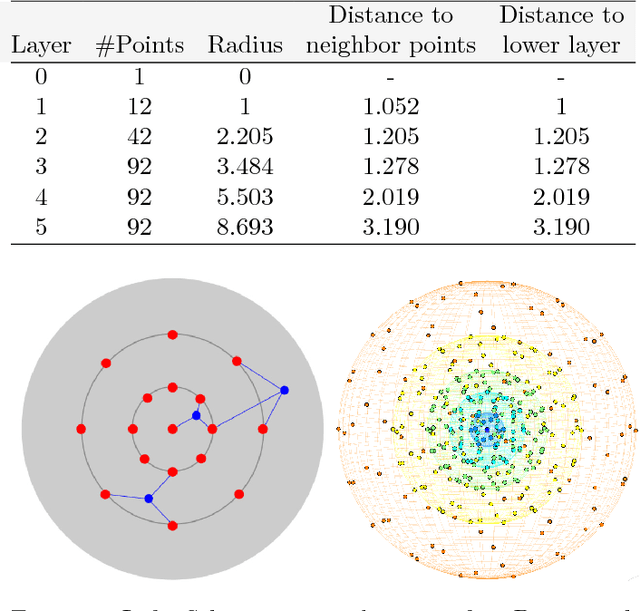
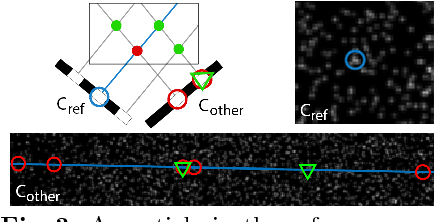
3D Particle Imaging Velocimetry (3D-PIV) aim to recover the flow field in a volume of fluid, which has been seeded with tracer particles and observed from multiple camera viewpoints. The first step of 3D-PIV is to reconstruct the 3D locations of the tracer particles from synchronous views of the volume. We propose a new method for iterative particle reconstruction (IPR), in which the locations and intensities of all particles are inferred in one joint energy minimization. The energy function is designed to penalize deviations between the reconstructed 3D particles and the image evidence, while at the same time aiming for a sparse set of particles. We find that the new method, without any post-processing, achieves significantly cleaner particle volumes than a conventional, tomographic MART reconstruction, and can handle a wide range of particle densities. The second step of 3D-PIV is to then recover the dense motion field from two consecutive particle reconstructions. We propose a variational model, which makes it possible to directly include physical properties, such as incompressibility and viscosity, in the estimation of the motion field. To further exploit the sparse nature of the input data, we propose a novel, compact descriptor of the local particle layout. Hence, we avoid the memory-intensive storage of high-resolution intensity volumes. Our framework is generic and allows for a variety of different data costs (correlation measures) and regularizers. We quantitatively evaluate it with both the sum of squared differences (SSD) and the normalized cross-correlation (NCC), respectively with both a hard and a soft version of the incompressibility constraint.
Robust Deformation Estimation in Wood-Composite Materials using Variational Optical Flow
Feb 13, 2018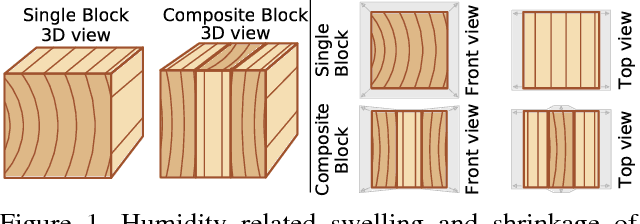
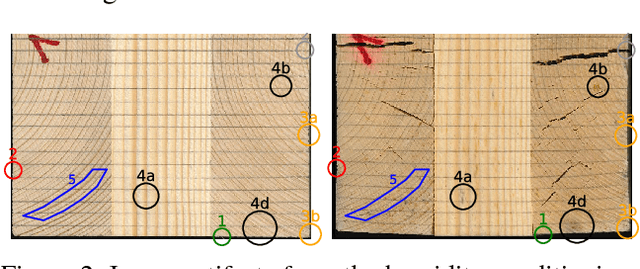
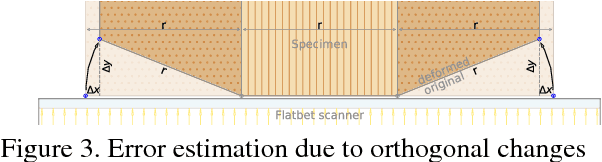
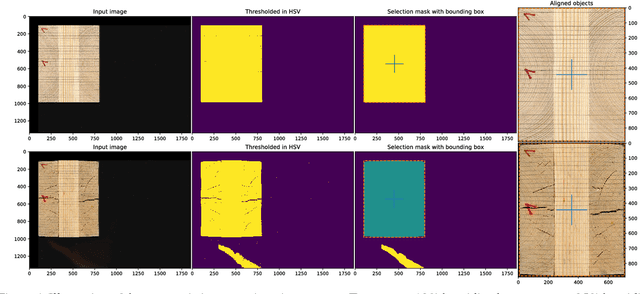
Wood-composite materials are widely used today as they homogenize humidity related directional deformations. Quantification of these deformations as coefficients is important for construction and engineering and topic of current research but still a manual process. This work introduces a novel computer vision approach that automatically extracts these properties directly from scans of the wooden specimens, taken at different humidity levels during the long lasting humidity conditioning process. These scans are used to compute a humidity dependent deformation field for each pixel, from which the desired coefficients can easily be calculated. The overall method includes automated registration of the wooden blocks, numerical optimization to compute a variational optical flow field which is further used to calculate dense strain fields and finally the engineering coefficients and their variance throughout the wooden blocks. The methods regularization is fully parameterizable which allows to model and suppress artifacts due to surface appearance changes of the specimens from mold, cracks, etc. that typically arise in the conditioning process.
* 8 pages, 8 figures, originally published in 23 rd Computer Vision Winter Workshop proceedings 2018 http://cmp.felk.cvut.cz/cvww2018/papers/28.pdf
Semantic 3D Reconstruction with Finite Element Bases
Oct 04, 2017

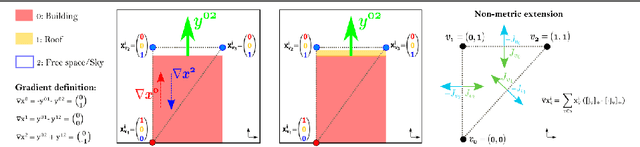

We propose a novel framework for the discretisation of multi-label problems on arbitrary, continuous domains. Our work bridges the gap between general FEM discretisations, and labeling problems that arise in a variety of computer vision tasks, including for instance those derived from the generalised Potts model. Starting from the popular formulation of labeling as a convex relaxation by functional lifting, we show that FEM discretisation is valid for the most general case, where the regulariser is anisotropic and non-metric. While our findings are generic and applicable to different vision problems, we demonstrate their practical implementation in the context of semantic 3D reconstruction, where such regularisers have proved particularly beneficial. The proposed FEM approach leads to a smaller memory footprint as well as faster computation, and it constitutes a very simple way to enable variable, adaptive resolution within the same model.
Scalable Full Flow with Learned Binary Descriptors
Jul 20, 2017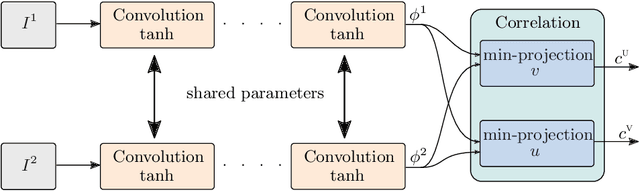
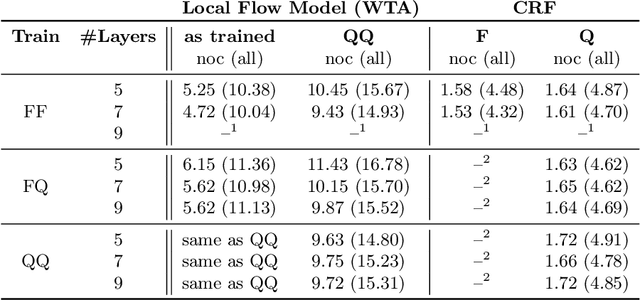
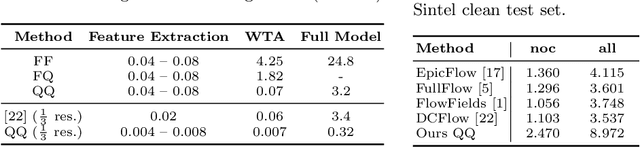
We propose a method for large displacement optical flow in which local matching costs are learned by a convolutional neural network (CNN) and a smoothness prior is imposed by a conditional random field (CRF). We tackle the computation- and memory-intensive operations on the 4D cost volume by a min-projection which reduces memory complexity from quadratic to linear and binary descriptors for efficient matching. This enables evaluation of the cost on the fly and allows to perform learning and CRF inference on high resolution images without ever storing the 4D cost volume. To address the problem of learning binary descriptors we propose a new hybrid learning scheme. In contrast to current state of the art approaches for learning binary CNNs we can compute the exact non-zero gradient within our model. We compare several methods for training binary descriptors and show results on public available benchmarks.