 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship Between RNN Hidden State Vectors and Semantic Ground Truth
Jun 29, 2023



We examine the assumption that the hidden-state vectors of recurrent neural networks (RNNs) tend to form clusters of semantically similar vectors, which we dub the clustering hypothesis. While this hypothesis has been assumed in the analysis of RNNs in recent years, its validity has not been studied thoroughly on modern neural network architectures. We examine the clustering hypothesis in the context of RNNs that were trained to recognize regular languages. This enables us to draw on perfect ground-truth automata in our evaluation, against which we can compare the RNN's accuracy and the distribution of the hidden-state vectors. We start with examining the (piecewise linear) separability of an RNN's hidden-state vectors into semantically different classes. We continue the analysis by computing clusters over the hidden-state vector space with multiple state-of-the-art unsupervised clustering approaches. We formally analyze the accuracy of computed clustering functions and the validity of the clustering hypothesis by determining whether clusters group semantically similar vectors to the same state in the ground-truth model. Our evaluation supports the validity of the clustering hypothesis in the majority of examined cases. We observed that the hidden-state vectors of well-trained RNNs are separable, and that the unsupervised clustering techniques succeed in finding clusters of similar state vectors.
Non-Log-Concave and Nonsmooth Sampling via Langevin Monte Carlo Algorithms
May 25, 2023



We study the problem of approximate sampling from non-log-concave distributions, e.g., Gaussian mixtures, which is often challenging even in low dimensions due to their multimodality. We focus on performing this task via Markov chain Monte Carlo (MCMC) methods derived from discretizations of the overdamped Langevin diffusions, which are commonly known as Langevin Monte Carlo algorithms. Furthermore, we are also interested in two nonsmooth cases for which a large class of proximal MCMC methods have been developed: (i) a nonsmooth prior is considered with a Gaussian mixture likelihood; (ii) a Laplacian mixture distribution. Such nonsmooth and non-log-concave sampling tasks arise from a wide range of applications to Bayesian inference and imaging inverse problems such as image deconvolution. We perform numerical simulations to compare the performance of most commonly used Langevin Monte Carlo algorithms.
Score-Based Generative Models for Medical Image Segmentation using Signed Distance Functions
Mar 10, 2023



Medical image segmentation is a crucial task that relies on the ability to accurately identify and isolate regions of interest in images. Thereby, generative approaches allow to capture the statistical properties of segmentation masks that are dependent on the respective medical images. In this work we propose a conditional score-based generative modeling framework that leverages the signed distance function to represent an implicit and smoother distribution of segmentation masks. The score function of the conditional distribution of segmentation masks is learned in a conditional denoising process, which can be effectively used to generate accurate segmentation masks. Moreover, uncertainty maps can be generated, which can aid in further analysis and thus enhance the predictive robustness. We qualitatively and quantitatively illustrate competitive performance of the proposed method on a public nuclei and gland segmentation data set, highlighting its potential utility in medical image segmentation applications.
Learning Gradually Non-convex Image Priors Using Score Matching
Feb 21, 2023



In this paper, we propose a unified framework of denoising score-based models in the context of graduated non-convex energy minimization. We show that for sufficiently large noise variance, the associated negative log density -- the energy -- becomes convex. Consequently, denoising score-based models essentially follow a graduated non-convexity heuristic. We apply this framework to learning generalized Fields of Experts image priors that approximate the joint density of noisy images and their associated variances. These priors can be easily incorporated into existing optimization algorithms for solving inverse problems and naturally implement a fast and robust graduated non-convexity mechanism.
Explicit Diffusion of Gaussian Mixture Model Based Image Priors
Feb 16, 2023In this work we tackle the problem of estimating the density $f_X$ of a random variable $X$ by successive smoothing, such that the smoothed random variable $Y$ fulfills $(\partial_t - \Delta_1)f_Y(\,\cdot\,, t) = 0$, $f_Y(\,\cdot\,, 0) = f_X$. With a focus on image processing, we propose a product/fields of experts model with Gaussian mixture experts that admits an analytic expression for $f_Y (\,\cdot\,, t)$ under an orthogonality constraint on the filters. This construction naturally allows the model to be trained simultaneously over the entire diffusion horizon using empirical Bayes. We show preliminary results on image denoising where our model leads to competitive results while being tractable, interpretable, and having only a small number of learnable parameters. As a byproduct, our model can be used for reliable noise estimation, allowing blind denoising of images corrupted by heteroscedastic noise.
Posterior-Variance-Based Error Quantification for Inverse Problems in Imaging
Dec 23, 2022In this work, a method for obtaining pixel-wise error bounds in Bayesian regularization of inverse imaging problems is introduced. The proposed method employs estimates of the posterior variance together with techniques from conformal prediction in order to obtain coverage guarantees for the error bounds, without making any assumption on the underlying data distribution. It is generally applicable to Bayesian regularization approaches, independent, e.g., of the concrete choice of the prior. Furthermore, the coverage guarantees can also be obtained in case only approximate sampling from the posterior is possible. With this in particular, the proposed framework is able to incorporate any learned prior in a black-box manner. Guaranteed coverage without assumptions on the underlying distributions is only achievable since the magnitude of the error bounds is, in general, unknown in advance. Nevertheless, experiments with multiple regularization approaches presented in the paper confirm that in practice, the obtained error bounds are rather tight. For realizing the numerical experiments, also a novel primal-dual Langevin algorithm for sampling from non-smooth distributions is introduced in this work.
Stable deep MRI reconstruction using Generative Priors
Oct 25, 2022



Data-driven approaches recently achieved remarkable success in medical image reconstruction, but integration into clinical routine remains challenging due to a lack of generalizability and interpretability. Existing approaches usually require high-quality data-image pairs for training, but such data is not easily available for any imaging protocol and the reconstruction quality can quickly degrade even if only minor changes are made to the protocol. In addition, data-driven methods may create artificial features that can influence the clinicians decision-making. This is unacceptable if the clinician is unaware of the uncertainty associated with the reconstruction. In this paper, we address these challenges in a unified framework based on generative image priors. We propose a novel deep neural network based regularizer which is trained in an unsupervised setting on reference images without requiring any data-image pairs. After training, the regularizer can be used as part of a classical variational approach in combination with any acquisition protocols and shows stable behavior even if the test data deviates significantly from the training data. Furthermore, our probabilistic interpretation provides a distribution of reconstructions and hence allows uncertainty quantification. We demonstrate our approach on parallel magnetic resonance imaging, where results show competitive performance with SotA end-to-end deep learning methods, while preserving the flexibility of the acquisition protocol and allowing for uncertainty quantification.
Is Appearance Free Action Recognition Possible?
Jul 13, 2022
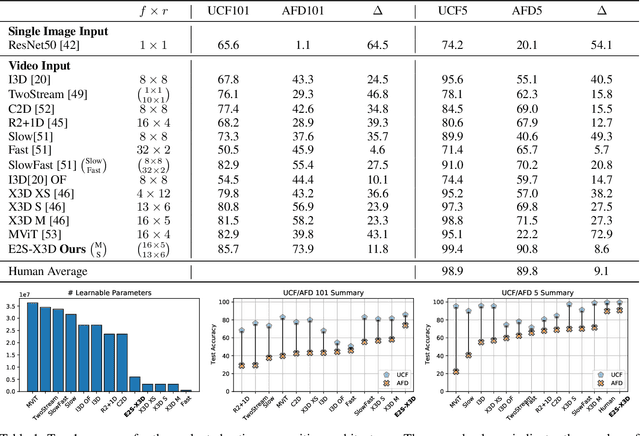

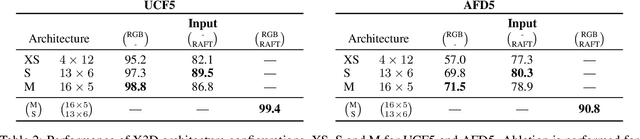
Intuition might suggest that motion and dynamic information are key to video-based action recognition. In contrast, there is evidence that state-of-the-art deep-learning video understanding architectures are biased toward static information available in single frames. Presently, a methodology and corresponding dataset to isolate the effects of dynamic information in video are missing. Their absence makes it difficult to understand how well contemporary architectures capitalize on dynamic vs. static information. We respond with a novel Appearance Free Dataset (AFD) for action recognition. AFD is devoid of static information relevant to action recognition in a single frame. Modeling of the dynamics is necessary for solving the task, as the action is only apparent through consideration of the temporal dimension. We evaluated 11 contemporary action recognition architectures on AFD as well as its related RGB video. Our results show a notable decrease in performance for all architectures on AFD compared to RGB. We also conducted a complimentary study with humans that shows their recognition accuracy on AFD and RGB is very similar and much better than the evaluated architectures on AFD. Our results motivate a novel architecture that revives explicit recovery of optical flow, within a contemporary design for best performance on AFD and RGB.
Computed Tomography Reconstruction using Generative Energy-Based Priors
Mar 23, 2022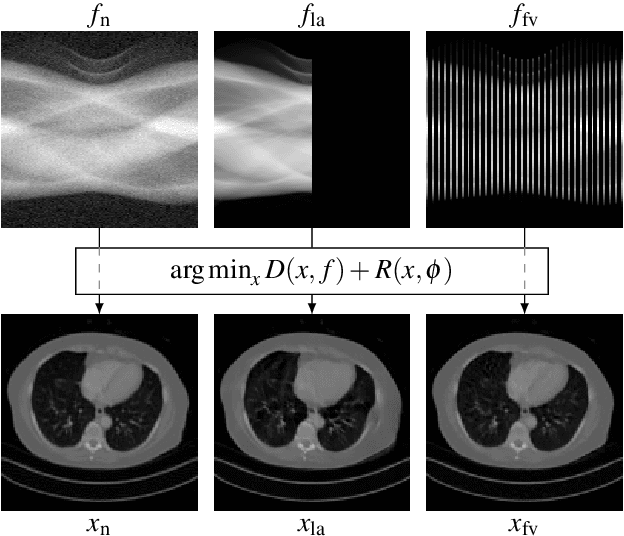
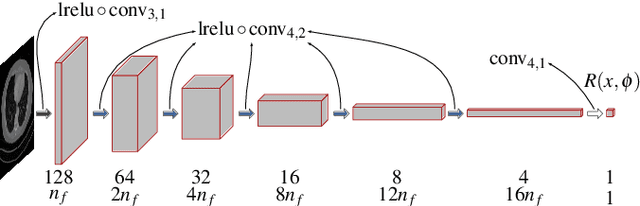
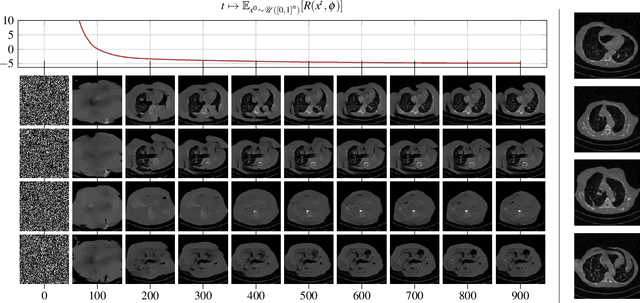
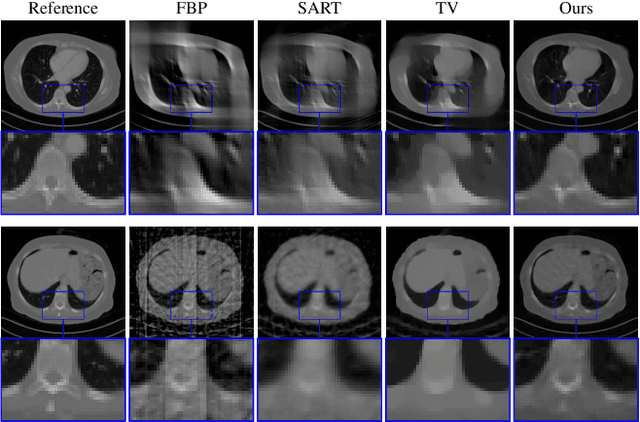
In the past decades, Computed Tomography (CT) has established itself as one of the most important imaging techniques in medicine. Today, the applicability of CT is only limited by the deposited radiation dose, reduction of which manifests in noisy or incomplete measurements. Thus, the need for robust reconstruction algorithms arises. In this work, we learn a parametric regularizer with a global receptive field by maximizing it's likelihood on reference CT data. Due to this unsupervised learning strategy, our trained regularizer truly represents higher-level domain statistics, which we empirically demonstrate by synthesizing CT images. Moreover, this regularizer can easily be applied to different CT reconstruction problems by embedding it in a variational framework, which increases flexibility and interpretability compared to feed-forward learning-based approaches. In addition, the accompanying probabilistic perspective enables experts to explore the full posterior distribution and may quantify uncertainty of the reconstruction approach. We apply the regularizer to limited-angle and few-view CT reconstruction problems, where it outperforms traditional reconstruction algorithms by a large margin.
Learning atrial fiber orientations and conductivity tensors from intracardiac maps using physics-informed neural networks
Feb 22, 2021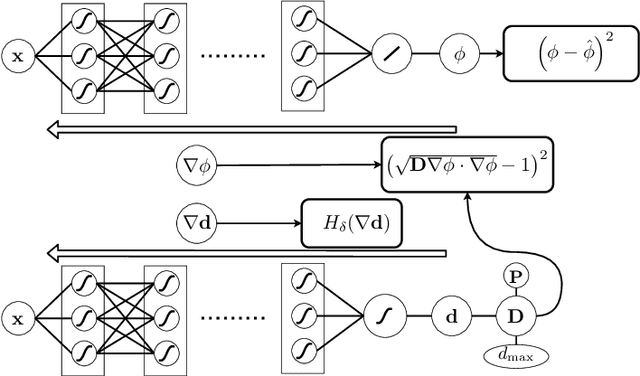
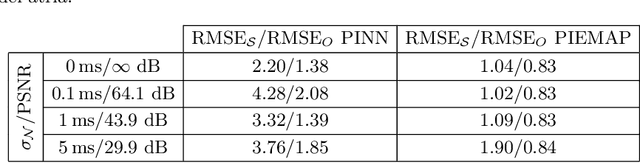
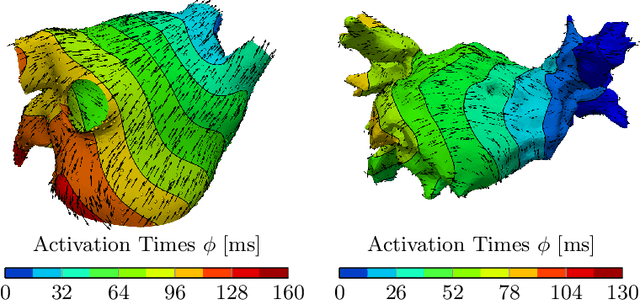
Electroanatomical maps are a key tool in the diagnosis and treatment of atrial fibrillation. Current approaches focus on the activation times recorded. However, more information can be extracted from the available data. The fibers in cardiac tissue conduct the electrical wave faster, and their direction could be inferred from activation times. In this work, we employ a recently developed approach, called physics informed neural networks, to learn the fiber orientations from electroanatomical maps, taking into account the physics of the electrical wave propagation. In particular, we train the neural network to weakly satisfy the anisotropic eikonal equation and to predict the measured activation times. We use a local basis for the anisotropic conductivity tensor, which encodes the fiber orientation. The methodology is tested both in a synthetic example and for patient data. Our approach shows good agreement in both cases and it outperforms a state of the art method in the patient data. The results show a first step towards learning the fiber orientations from electroanatomical maps with physics-informed neural networks.