 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Tune XGBoost with XGBoost
Sep 19, 2019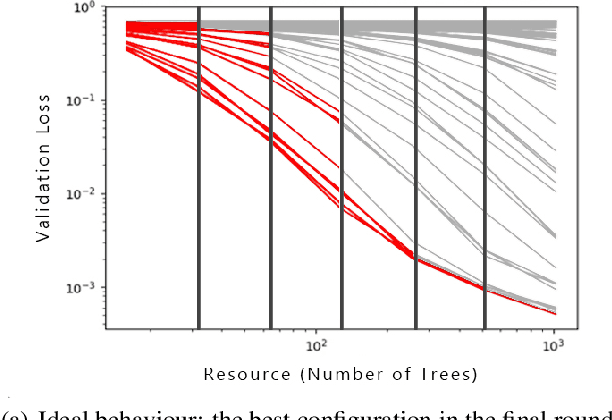
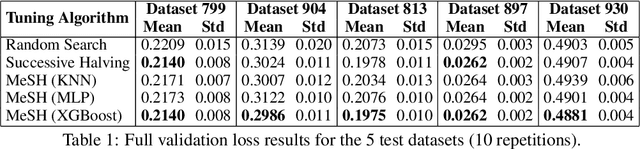
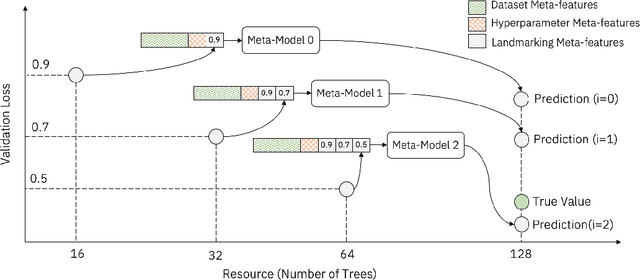
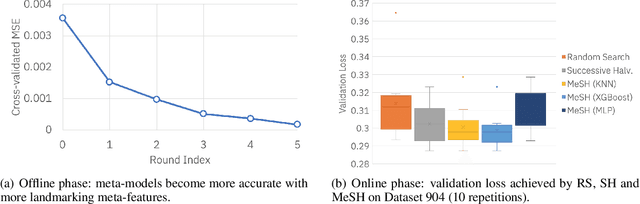
In this short paper we investigate whether meta-learning techniques can be used to more effectively tune the hyperparameters of machine learning models using successive halving (SH). We propose a novel variant of the SH algorithm (MeSH), that uses meta-regressors to determine which candidate configurations should be eliminated at each round. We apply MeSH to the problem of tuning the hyperparameters of a gradient-boosted decision tree model. By training and tuning our meta-regressors using existing tuning jobs from 95 datasets, we demonstrate that MeSH can often find a superior solution to both SH and random search.
Weighted Sampling for Combined Model Selection and Hyperparameter Tuning
Sep 17, 2019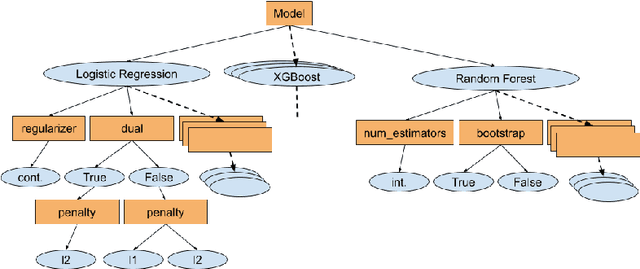
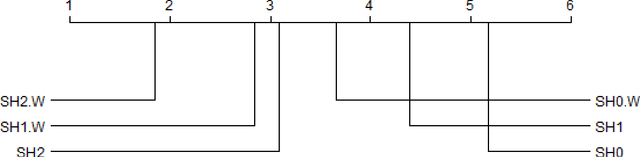
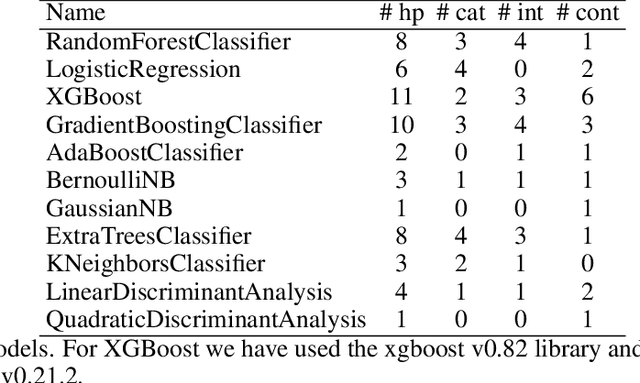
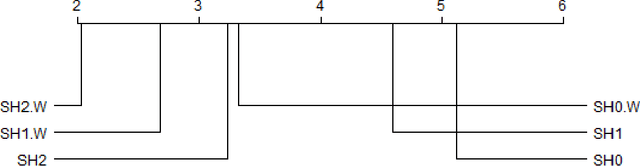
The combined algorithm selection and hyperparameter tuning (CASH) problem is characterized by large hierarchical hyperparameter spaces. Model-free hyperparameter tuning methods can explore such large spaces efficiently since they are highly parallelizable across multiple machines. When no prior knowledge or meta-data exists to boost their performance, these methods commonly sample random configurations following a uniform distribution. In this work, we propose a novel sampling distribution as an alternative to uniform sampling and prove theoretically that it has a better chance of finding the best configuration in a worst-case setting. In order to compare competing methods rigorously in an experimental setting, one must perform statistical hypothesis testing. We show that there is little-to-no agreement in the automated machine learning literature regarding which methods should be used. We contrast this disparity with the methods recommended by the broader statistics literature, and identify the most suitable approach. We then select three popular model-free solutions to CASH and evaluate their performance, with uniform sampling as well as the proposed sampling scheme, across 67 datasets from the OpenML platform. We investigate the trade-off between exploration and exploitation across the three algorithms, and verify empirically that the proposed sampling distribution improves performance in all cases.
Addressing Algorithmic Bottlenecks in Elastic Machine Learning with Chicle
Sep 11, 2019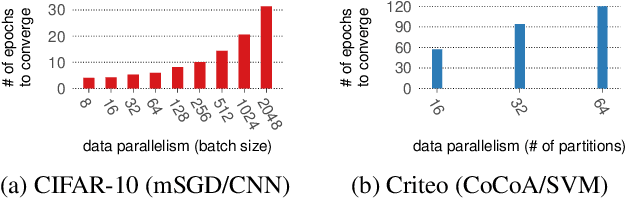
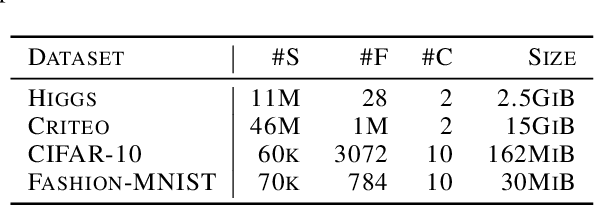
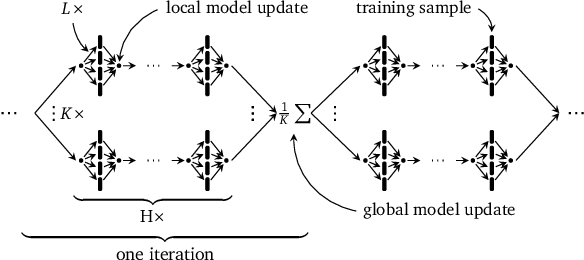
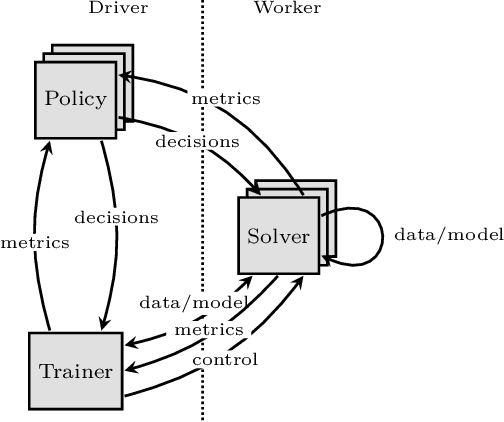
Distributed machine learning training is one of the most common and important workloads running on data centers today, but it is rarely executed alone. Instead, to reduce costs, computing resources are consolidated and shared by different applications. In this scenario, elasticity and proper load balancing are vital to maximize efficiency, fairness, and utilization. Currently, most distributed training frameworks do not support the aforementioned properties. A few exceptions that do support elasticity, imitate generic distributed frameworks and use micro-tasks. In this paper we illustrate that micro-tasks are problematic for machine learning applications, because they require a high degree of parallelism which hinders the convergence of distributed training at a pure algorithmic level (i.e., ignoring overheads and scalability limitations). To address this, we propose Chicle, a new elastic distributed training framework which exploits the nature of machine learning algorithms to implement elasticity and load balancing without micro-tasks. We use Chicle to train deep neural network as well as generalized linear models, and show that Chicle achieves performance competitive with state of the art rigid frameworks, while efficiently enabling elastic execution and dynamic load balancing.
5 Parallel Prism: A topology for pipelined implementations of convolutional neural networks using computational memory
Jun 08, 2019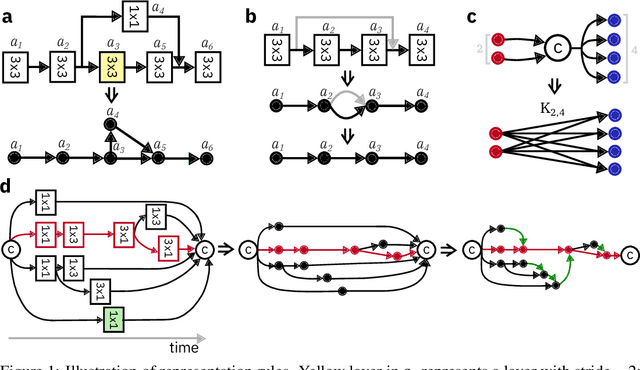
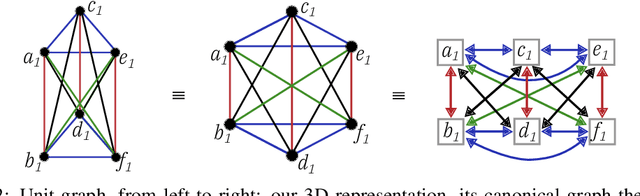
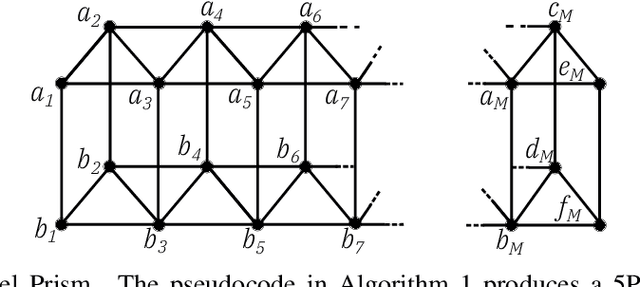
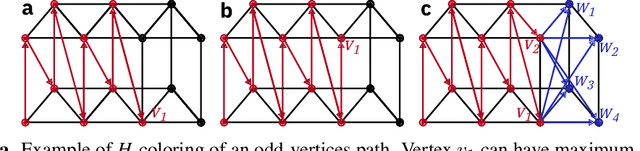
In-memory computing is an emerging computing paradigm that could enable deeplearning inference at significantly higher energy efficiency and reduced latency. The essential idea is to map the synaptic weights corresponding to each layer to one or more computational memory (CM) cores. During inference, these cores perform the associated matrix-vector multiply operations in place with O(1) time complexity, thus obviating the need to move the synaptic weights to an additional processing unit. Moreover, this architecture could enable the execution of these networks in a highly pipelined fashion. However, a key challenge is to design an efficient communication fabric for the CM cores. Here, we present one such communication fabric based on a graph topology that is well suited for the widely successful convolutional neural networks (CNNs). We show that this communication fabric facilitates the pipelined execution of all state of-the-art CNNs by proving the existence of a homomorphism between one graph representation of these networks and the proposed graph topology. We then present a quantitative comparison with established communication topologies and show that our proposed topology achieves the lowest bandwidth requirements per communication channel. Finally, we present a concrete example of mapping ResNet-32 onto an array of CM cores.
Sampling Acquisition Functions for Batch Bayesian Optimization
Mar 22, 2019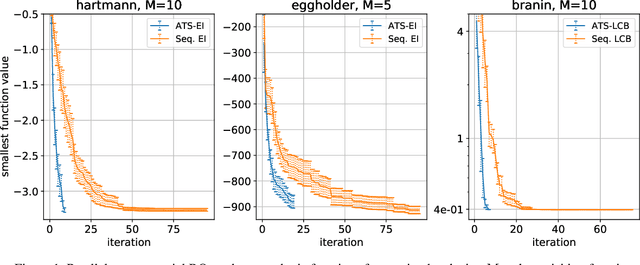
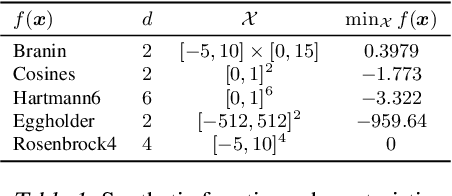
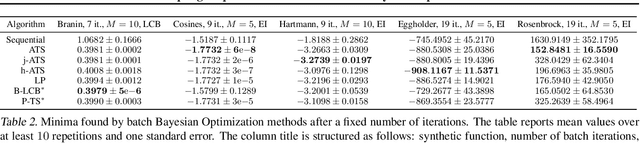
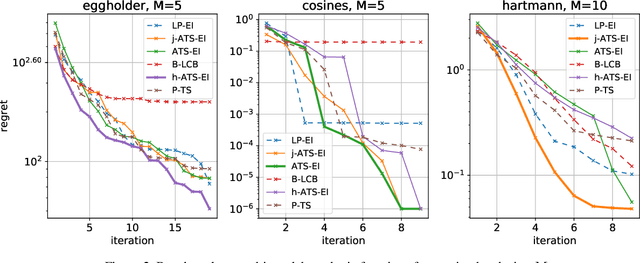
This paper presents Acquisition Thompson Sampling (ATS), a novel algorithm for batch Bayesian Optimization (BO) based on the idea of sampling multiple acquisition functions from a stochastic process. We define this process through the dependency of the acquisition functions on a set of model parameters. ATS is conceptually simple, straightforward to implement and, unlike other batch BO methods, it can be employed to parallelize any sequential acquisition function. In order to improve performance for multi-modal tasks, we show that ATS can be combined with existing techniques in order to realize different explore-exploit trade-offs and take into account pending function evaluations. We present experiments on a variety of benchmark functions and on the hyper-parameter optimization of a popular gradient boosting tree algorithm. These demonstrate the competitiveness of our algorithm with two state-of-the-art batch BO methods, and its advantages to classical parallel Thompson Sampling for BO.
Elastic CoCoA: Scaling In to Improve Convergence
Nov 06, 2018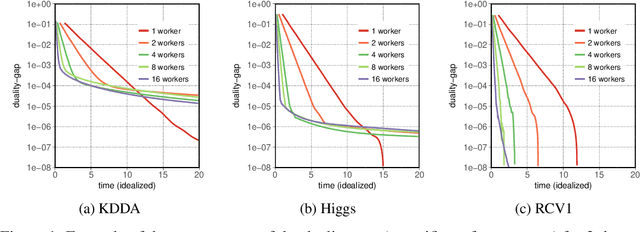
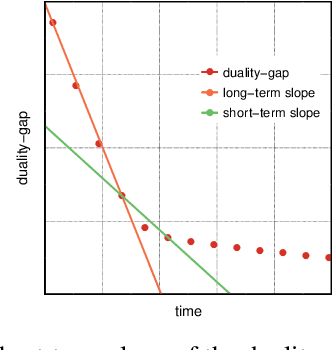

In this paper we experimentally analyze the convergence behavior of CoCoA and show, that the number of workers required to achieve the highest convergence rate at any point in time, changes over the course of the training. Based on this observation, we build Chicle, an elastic framework that dynamically adjusts the number of workers based on feedback from the training algorithm, in order to select the number of workers that results in the highest convergence rate. In our evaluation of 6 datasets, we show that Chicle is able to accelerate the time-to-accuracy by a factor of up to 5.96x compared to the best static setting, while being robust enough to find an optimal or near-optimal setting automatically in most cases.
Parallel training of linear models without compromising convergence
Nov 05, 2018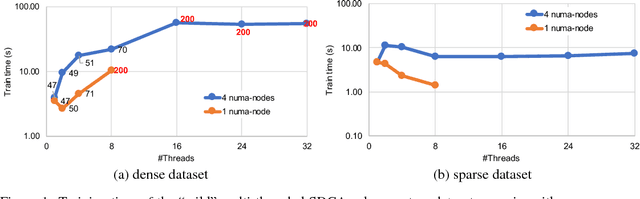
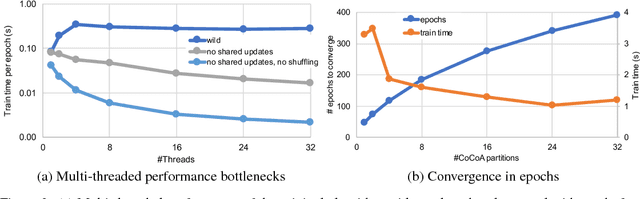
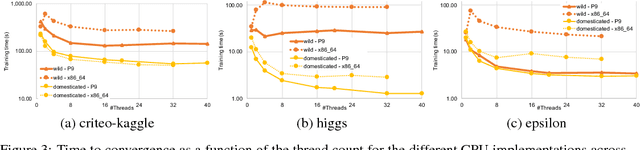
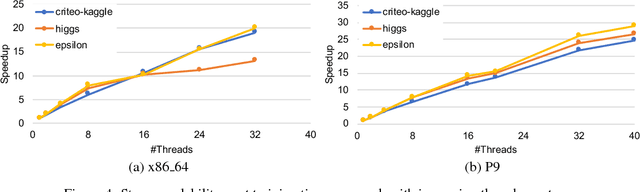
In this paper we analyze, evaluate, and improve the performance of training generalized linear models on modern CPUs. We start with a state-of-the-art asynchronous parallel training algorithm, identify system-level performance bottlenecks, and apply optimizations that improve data parallelism, cache line locality, and cache line prefetching of the algorithm. These modifications reduce the per-epoch run-time significantly, but take a toll on algorithm convergence in terms of the required number of epochs. To alleviate these shortcomings of our systems-optimized version, we propose a novel, dynamic data partitioning scheme across threads which allows us to approach the convergence of the sequential version. The combined set of optimizations result in a consistent bottom line speedup in convergence of up to $\times12$ compared to the initial asynchronous parallel training algorithm and up to $\times42$, compared to state of the art implementations (scikit-learn and h2o) on a range of multi-core CPU architectures.
Benchmarking and Optimization of Gradient Boosting Decision Tree Algorithms
Oct 25, 2018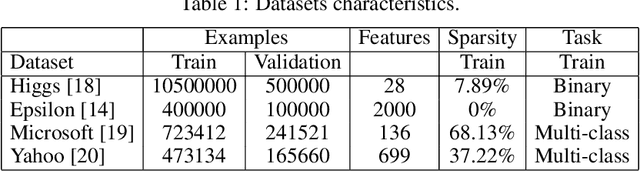
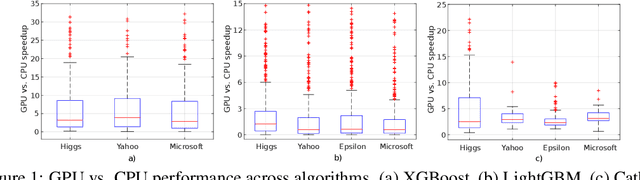
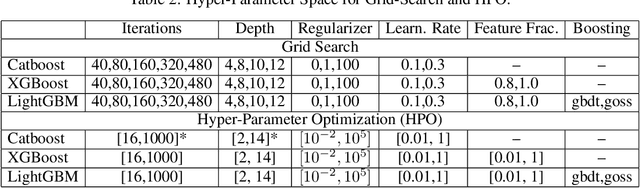
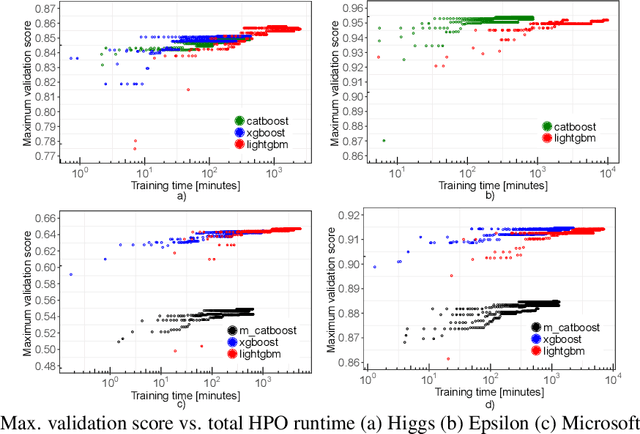
Gradient boosting decision trees (GBDTs) have seen widespread adoption in academia, industry and competitive data science due to their state-of-the-art performance in many machine learning tasks. One relative downside to these models is the large number of hyper-parameters that they expose to the end-user. To maximize the predictive power of GBDT models, one must either manually tune the hyper-parameters, or utilize automated techniques such as those based on Bayesian optimization. Both of these approaches are time-consuming since they involve repeatably training the model for different sets of hyper-parameters. A number of software GBDT packages have started to offer GPU acceleration which can help to alleviate this problem. In this paper, we consider three such packages: XGBoost, LightGBM and Catboost. Firstly, we evaluate the performance of the GPU acceleration provided by these packages using large-scale datasets with varying shapes, sparsities and learning tasks. Then, we compare the packages in the context of hyper-parameter optimization, both in terms of how quickly each package converges to a good validation score, and in terms of generalization performance.
Snap ML: A Hierarchical Framework for Machine Learning
Jun 18, 2018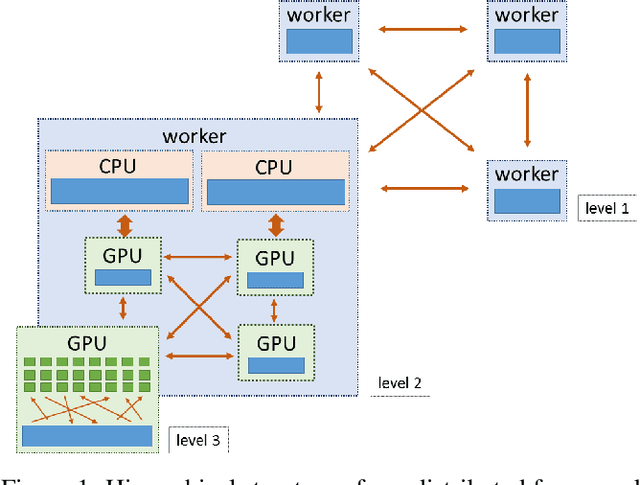

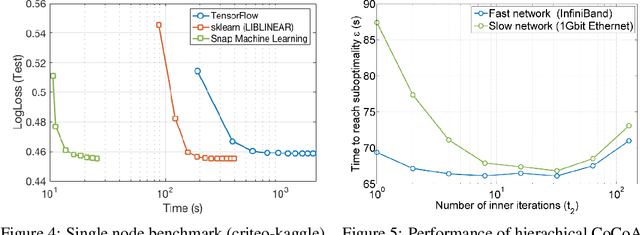
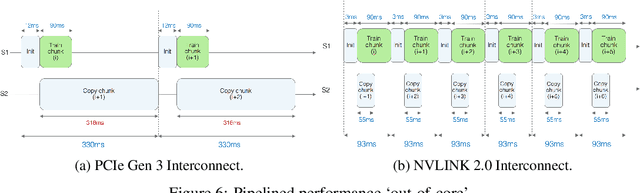
We describe a new software framework for fast training of generalized linear models. The framework, named Snap Machine Learning (Snap ML), combines recent advances in machine learning systems and algorithms in a nested manner to reflect the hierarchical architecture of modern computing systems. We prove theoretically that such a hierarchical system can accelerate training in distributed environments where intra-node communication is cheaper than inter-node communication. Additionally, we provide a review of the implementation of Snap ML in terms of GPU acceleration, pipelining, communication patterns and software architecture, highlighting aspects that were critical for achieving high performance. We evaluate the performance of Snap ML in both single-node and multi-node environments, quantifying the benefit of the hierarchical scheme and the data streaming functionality, and comparing with other widely-used machine learning software frameworks. Finally, we present a logistic regression benchmark on the Criteo Terabyte Click Logs dataset and show that Snap ML achieves the same test loss an order of magnitude faster than any of the previously reported results.
Understanding and Optimizing the Performance of Distributed Machine Learning Applications on Apache Spark
Dec 13, 2017
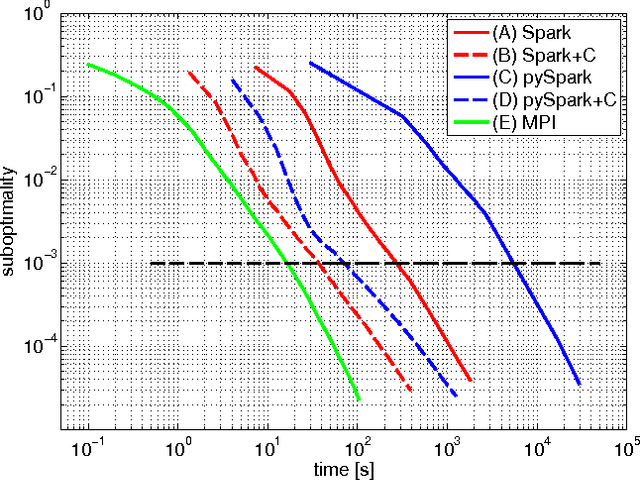
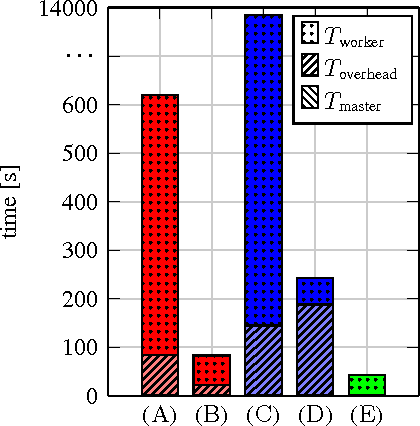
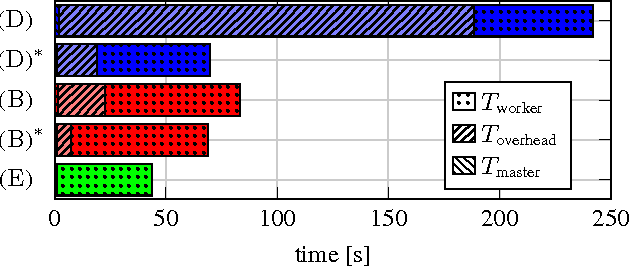
In this paper we explore the performance limits of Apache Spark for machine learning applications. We begin by analyzing the characteristics of a state-of-the-art distributed machine learning algorithm implemented in Spark and compare it to an equivalent reference implementation using the high performance computing framework MPI. We identify critical bottlenecks of the Spark framework and carefully study their implications on the performance of the algorithm. In order to improve Spark performance we then propose a number of practical techniques to alleviate some of its overheads. However, optimizing computational efficiency and framework related overheads is not the only key to performance -- we demonstrate that in order to get the best performance out of any implementation it is necessary to carefully tune the algorithm to the respective trade-off between computation time and communication latency. The optimal trade-off depends on both the properties of the distributed algorithm as well as infrastructure and framework-related characteristics. Finally, we apply these technical and algorithmic optimizations to three different distributed linear machine learning algorithms that have been implemented in Spark. We present results using five large datasets and demonstrate that by using the proposed optimizations, we can achieve a reduction in the performance difference between Spark and MPI from 20x to 2x.