 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Contextual Optimization Methods for Decision Making under Uncertainty
Jun 17, 2023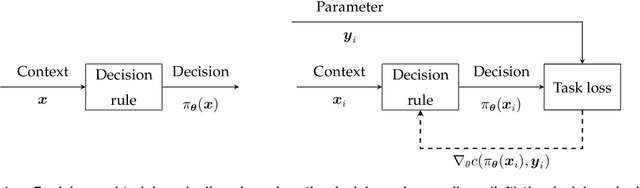



Recently there has been a surge of interest in operations research (OR) and the machine learning (ML) community in combining prediction algorithms and optimization techniques to solve decision-making problems in the face of uncertainty. This gave rise to the field of contextual optimization, under which data-driven procedures are developed to prescribe actions to the decision-maker that make the best use of the most recently updated information. A large variety of models and methods have been presented in both OR and ML literature under a variety of names, including data-driven optimization, prescriptive optimization, predictive stochastic programming, policy optimization, (smart) predict/estimate-then-optimize, decision-focused learning, (task-based) end-to-end learning/forecasting/optimization, etc. Focusing on single and two-stage stochastic programming problems, this review article identifies three main frameworks for learning policies from data and discusses their strengths and limitations. We present the existing models and methods under a uniform notation and terminology and classify them according to the three main frameworks identified. Our objective with this survey is to both strengthen the general understanding of this active field of research and stimulate further theoretical and algorithmic advancements in integrating ML and stochastic programming.
Learning-based Online Optimization for Autonomous Mobility-on-Demand Fleet Control
Feb 08, 2023Autonomous mobility-on-demand systems are a viable alternative to mitigate many transportation-related externalities in cities, such as rising vehicle volumes in urban areas and transportation-related pollution. However, the success of these systems heavily depends on efficient and effective fleet control strategies. In this context, we study online control algorithms for autonomous mobility-on-demand systems and develop a novel hybrid combinatorial optimization enriched machine learning pipeline which learns online dispatching and rebalancing policies from optimal full-information solutions. We test our hybrid pipeline on large-scale real-world scenarios with different vehicle fleet sizes and various request densities. We show that our approach outperforms state-of-the-art greedy, and model-predictive control approaches with respect to various KPIs, e.g., by up to 17.1% and on average by 6.3% in terms of realized profit.
Regularization and Global Optimization in Model-Based Clustering
Feb 05, 2023



Due to their conceptual simplicity, k-means algorithm variants have been extensively used for unsupervised cluster analysis. However, one main shortcoming of these algorithms is that they essentially fit a mixture of identical spherical Gaussians to data that vastly deviates from such a distribution. In comparison, general Gaussian Mixture Models (GMMs) can fit richer structures but require estimating a quadratic number of parameters per cluster to represent the covariance matrices. This poses two main issues: (i) the underlying optimization problems are challenging due to their larger number of local minima, and (ii) their solutions can overfit the data. In this work, we design search strategies that circumvent both issues. We develop efficient global optimization algorithms for general GMMs, and we combine these algorithms with regularization strategies that avoid overfitting. Through extensive computational analyses, we observe that global optimization or regularization in isolation does not substantially improve cluster recovery. However, combining these techniques permits a completely new level of performance previously unachieved by k-means algorithm variants, unraveling vastly different cluster structures. These results shed new light on the current status quo between GMM and k-means methods and suggest the more frequent use of general GMMs for data exploration. To facilitate such applications, we provide open-source code as well as Julia packages ("UnsupervisedClustering.jl" and "RegularizedCovarianceMatrices.jl") implementing the proposed techniques.
Explainable Data-Driven Optimization: From Context to Decision and Back Again
Jan 24, 2023



Data-driven optimization uses contextual information and machine learning algorithms to find solutions to decision problems with uncertain parameters. While a vast body of work is dedicated to interpreting machine learning models in the classification setting, explaining decision pipelines involving learning algorithms remains unaddressed. This lack of interpretability can block the adoption of data-driven solutions as practitioners may not understand or trust the recommended decisions. We bridge this gap by introducing a counterfactual explanation methodology tailored to explain solutions to data-driven problems. We introduce two classes of explanations and develop methods to find nearest explanations of random forest and nearest-neighbor predictors. We demonstrate our approach by explaining key problems in operations management such as inventory management and routing.
Bilevel Optimization for Feature Selection in the Data-Driven Newsvendor Problem
Sep 12, 2022
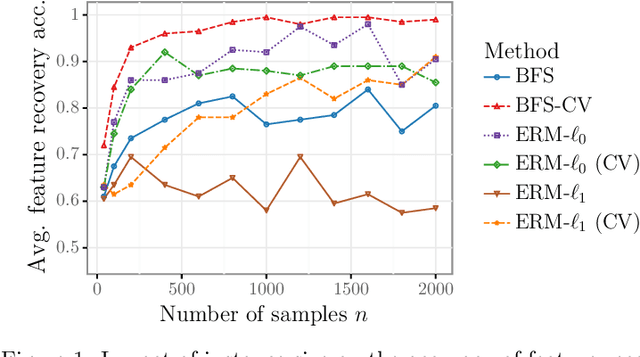
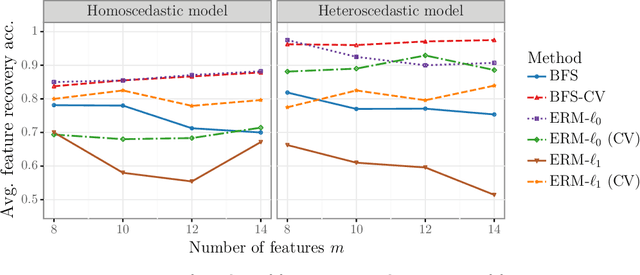
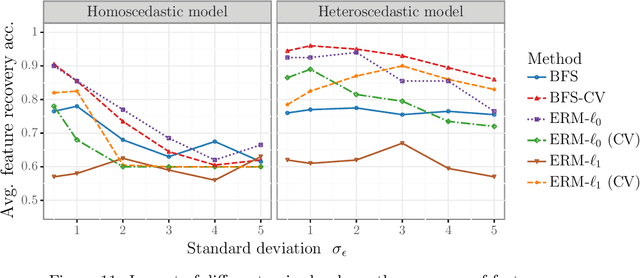
We study the feature-based newsvendor problem, in which a decision-maker has access to historical data consisting of demand observations and exogenous features. In this setting, we investigate feature selection, aiming to derive sparse, explainable models with improved out-of-sample performance. Up to now, state-of-the-art methods utilize regularization, which penalizes the number of selected features or the norm of the solution vector. As an alternative, we introduce a novel bilevel programming formulation. The upper-level problem selects a subset of features that minimizes an estimate of the out-of-sample cost of ordering decisions based on a held-out validation set. The lower-level problem learns the optimal coefficients of the decision function on a training set, using only the features selected by the upper-level. We present a mixed integer linear program reformulation for the bilevel program, which can be solved to optimality with standard optimization solvers. Our computational experiments show that the method accurately recovers ground-truth features already for instances with a sample size of a few hundred observations. In contrast, regularization-based techniques often fail at feature recovery or require thousands of observations to obtain similar accuracy. Regarding out-of-sample generalization, we achieve improved or comparable cost performance.
Support Vector Machines with the Hard-Margin Loss: Optimal Training via Combinatorial Benders' Cuts
Jul 15, 2022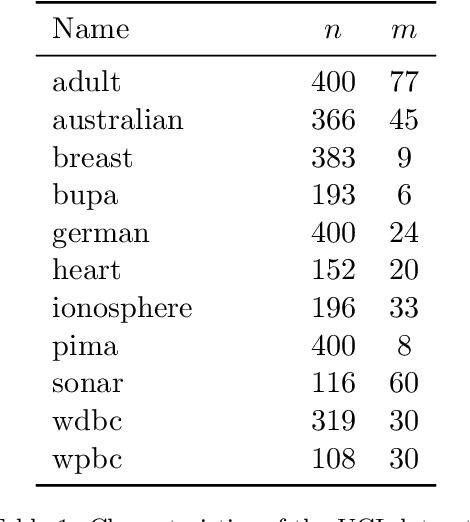

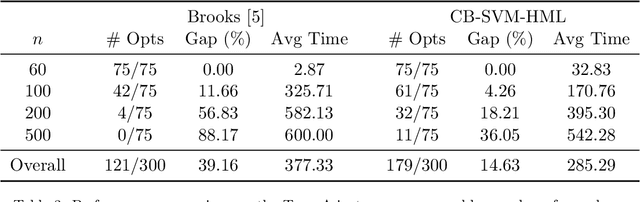
The classical hinge-loss support vector machines (SVMs) model is sensitive to outlier observations due to the unboundedness of its loss function. To circumvent this issue, recent studies have focused on non-convex loss functions, such as the hard-margin loss, which associates a constant penalty to any misclassified or within-margin sample. Applying this loss function yields much-needed robustness for critical applications but it also leads to an NP-hard model that makes training difficult, since current exact optimization algorithms show limited scalability, whereas heuristics are not able to find high-quality solutions consistently. Against this background, we propose new integer programming strategies that significantly improve our ability to train the hard-margin SVM model to global optimality. We introduce an iterative sampling and decomposition approach, in which smaller subproblems are used to separate combinatorial Benders' cuts. Those cuts, used within a branch-and-cut algorithm, permit to converge much more quickly towards a global optimum. Through extensive numerical analyses on classical benchmark data sets, our solution algorithm solves, for the first time, 117 new data sets to optimality and achieves a reduction of 50% in the average optimality gap for the hardest datasets of the benchmark.
Optimal Decision Diagrams for Classification
May 28, 2022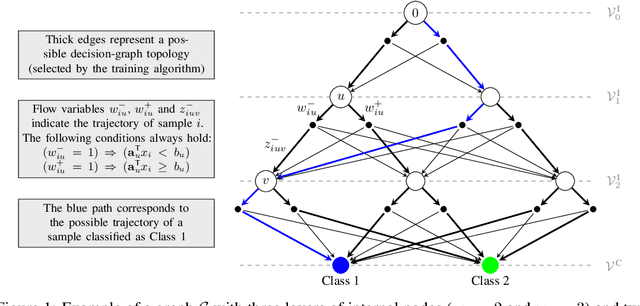
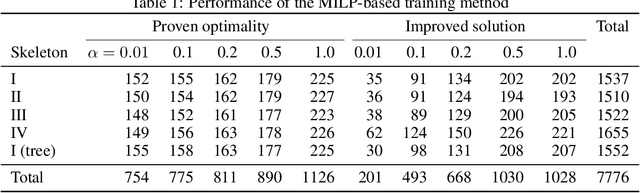
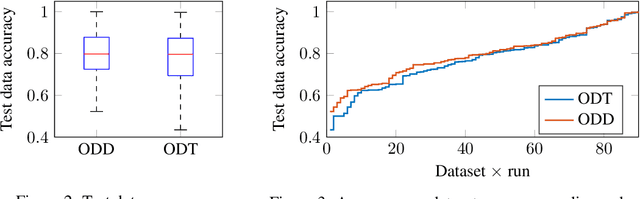
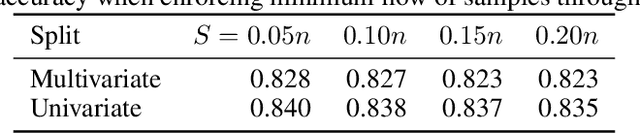
Decision diagrams for classification have some notable advantages over decision trees, as their internal connections can be determined at training time and their width is not bound to grow exponentially with their depth. Accordingly, decision diagrams are usually less prone to data fragmentation in internal nodes. However, the inherent complexity of training these classifiers acted as a long-standing barrier to their widespread adoption. In this context, we study the training of optimal decision diagrams (ODDs) from a mathematical programming perspective. We introduce a novel mixed-integer linear programming model for training and demonstrate its applicability for many datasets of practical importance. Further, we show how this model can be easily extended for fairness, parsimony, and stability notions. We present numerical analyses showing that our model allows training ODDs in short computational times, and that ODDs achieve better accuracy than optimal decision trees, while allowing for improved stability without significant accuracy losses.
Robust Counterfactual Explanations for Random Forests
May 27, 2022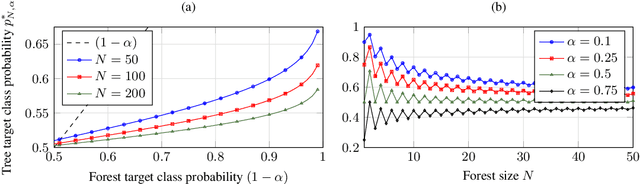
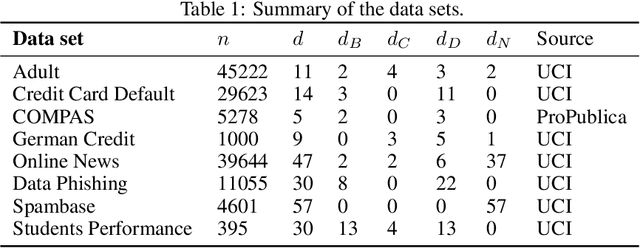
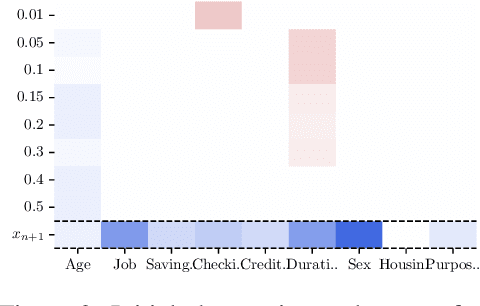
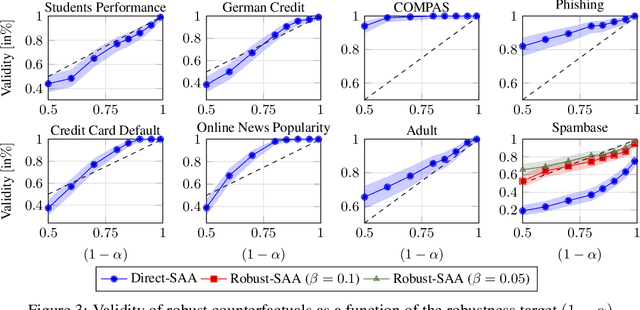
Counterfactual explanations describe how to modify a feature vector in order to flip the outcome of a trained classifier. Several heuristic and optimal methods have been proposed to generate these explanations. However, the robustness of counterfactual explanations when the classifier is re-trained has yet to be studied. Our goal is to obtain counterfactual explanations for random forests that are robust to algorithmic uncertainty. We study the link between the robustness of ensemble models and the robustness of base learners and frame the generation of robust counterfactual explanations as a chance-constrained optimization problem. We develop a practical method with good empirical performance and provide finite-sample and asymptotic guarantees for simple random forests of stumps. We show that existing methods give surprisingly low robustness: the validity of naive counterfactuals is below $50\%$ on most data sets and can fall to $20\%$ on large problem instances with many features. Even with high plausibility, counterfactual explanations often exhibit low robustness to algorithmic uncertainty. In contrast, our method achieves high robustness with only a small increase in the distance from counterfactual explanations to their initial observations. Furthermore, we highlight the connection between the robustness of counterfactual explanations and the predictive importance of features.
Optimal Counterfactual Explanations in Tree Ensembles
Jun 25, 2021
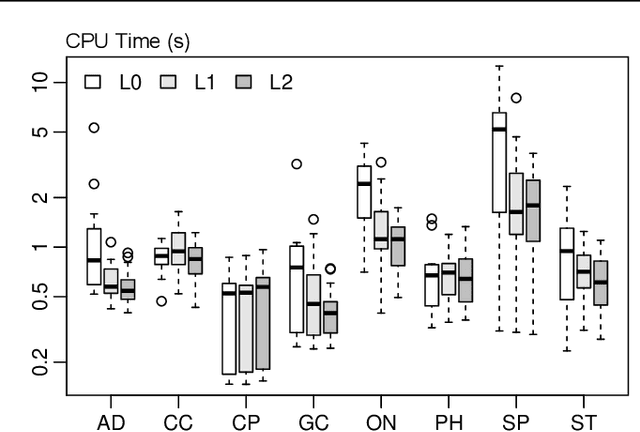
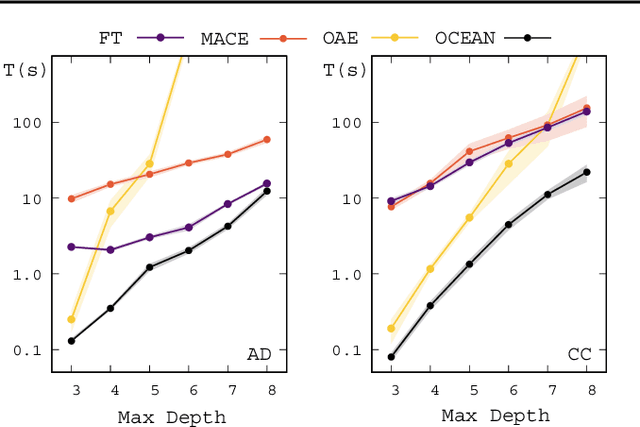
Counterfactual explanations are usually generated through heuristics that are sensitive to the search's initial conditions. The absence of guarantees of performance and robustness hinders trustworthiness. In this paper, we take a disciplined approach towards counterfactual explanations for tree ensembles. We advocate for a model-based search aiming at "optimal" explanations and propose efficient mixed-integer programming approaches. We show that isolation forests can be modeled within our framework to focus the search on plausible explanations with a low outlier score. We provide comprehensive coverage of additional constraints that model important objectives, heterogeneous data types, structural constraints on the feature space, along with resource and actionability restrictions. Our experimental analyses demonstrate that the proposed search approach requires a computational effort that is orders of magnitude smaller than previous mathematical programming algorithms. It scales up to large data sets and tree ensembles, where it provides, within seconds, systematic explanations grounded on well-defined models solved to optimality.
Semi-Supervised Clustering with Inaccurate Pairwise Annotations
Apr 05, 2021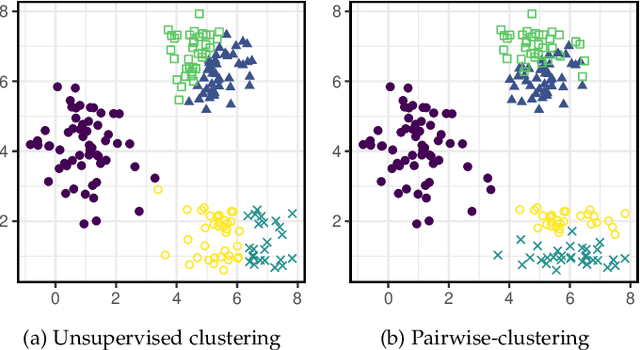
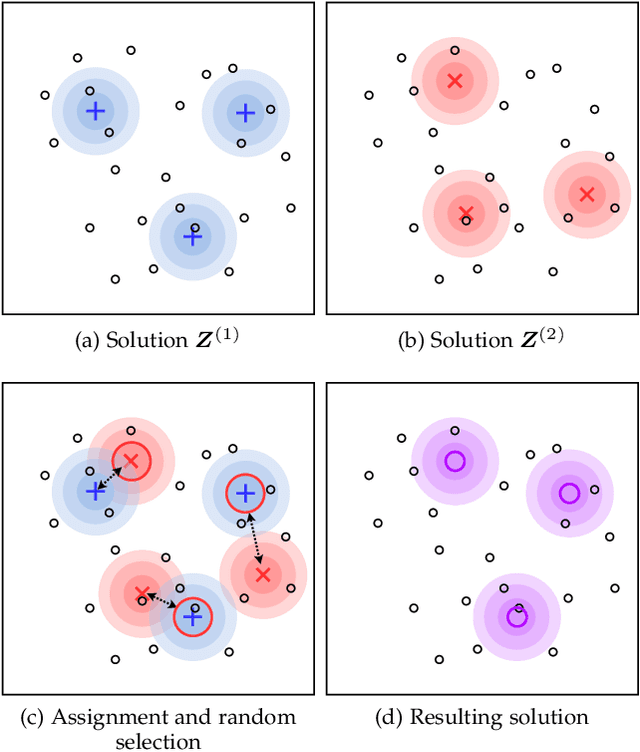
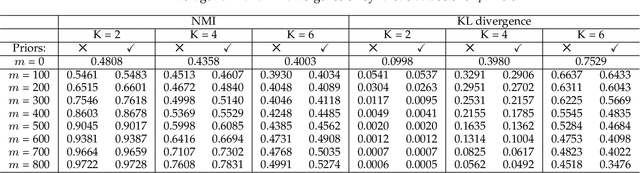
Pairwise relational information is a useful way of providing partial supervision in domains where class labels are difficult to acquire. This work presents a clustering model that incorporates pairwise annotations in the form of must-link and cannot-link relations and considers possible annotation inaccuracies (i.e., a common setting when experts provide pairwise supervision). We propose a generative model that assumes Gaussian-distributed data samples along with must-link and cannot-link relations generated by stochastic block models. We adopt a maximum-likelihood approach and demonstrate that, even when supervision is weak and inaccurate, accounting for relational information significantly improves clustering performance. Relational information also helps to detect meaningful groups in real-world datasets that do not fit the original data-distribution assumptions. Additionally, we extend the model to integrate prior knowledge of experts' accuracy and discuss circumstances in which the use of this knowledge is beneficial.