 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Oct 13, 2023Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors. Our code is available at https://github.com/insitro/ChannelViT.
Contextual Vision Transformers for Robust Representation Learning
May 30, 2023



We present Contextual Vision Transformers (ContextViT), a method for producing robust feature representations for images exhibiting grouped structure such as covariates. ContextViT introduces an extra context token to encode group-specific information, allowing the model to explain away group-specific covariate structures while keeping core visual features shared across groups. Specifically, given an input image, Context-ViT maps images that share the same covariate into this context token appended to the input image tokens to capture the effects of conditioning the model on group membership. We furthermore introduce a context inference network to predict such tokens on the fly given a few samples from a group distribution, enabling ContextViT to generalize to new testing distributions at inference time. We illustrate the performance of ContextViT through a diverse range of applications. In supervised fine-tuning, we demonstrate that augmenting pre-trained ViTs with additional context conditioning leads to significant improvements in out-of-distribution generalization on iWildCam and FMoW. We also explored self-supervised representation learning with ContextViT. Our experiments on the Camelyon17 pathology imaging benchmark and the cpg-0000 microscopy imaging benchmark demonstrate that ContextViT excels in learning stable image featurizations amidst covariate shift, consistently outperforming its ViT counterpart.
DEL-Dock: Molecular Docking-Enabled Modeling of DNA-Encoded Libraries
Dec 14, 2022DNA-Encoded Library (DEL) technology has enabled significant advances in hit identification by enabling efficient testing of combinatorially-generated molecular libraries. DEL screens measure protein binding affinity though sequencing reads of molecules tagged with unique DNA-barcodes that survive a series of selection experiments. Computational models have been deployed to learn the latent binding affinities that are correlated to the sequenced count data; however, this correlation is often obfuscated by various sources of noise introduced in its complicated data-generation process. In order to denoise DEL count data and screen for molecules with good binding affinity, computational models require the correct assumptions in their modeling structure to capture the correct signals underlying the data. Recent advances in DEL models have focused on probabilistic formulations of count data, but existing approaches have thus far been limited to only utilizing 2-D molecule-level representations. We introduce a new paradigm, DEL-Dock, that combines ligand-based descriptors with 3-D spatial information from docked protein-ligand complexes. 3-D spatial information allows our model to learn over the actual binding modality rather than using only structured-based information of the ligand. We show that our model is capable of effectively denoising DEL count data to predict molecule enrichment scores that are better correlated with experimental binding affinity measurements compared to prior works. Moreover, by learning over a collection of docked poses we demonstrate that our model, trained only on DEL data, implicitly learns to perform good docking pose selection without requiring external supervision from expensive-to-source protein crystal structures.
Black-box Coreset Variational Inference
Nov 04, 2022



Recent advances in coreset methods have shown that a selection of representative datapoints can replace massive volumes of data for Bayesian inference, preserving the relevant statistical information and significantly accelerating subsequent downstream tasks. Existing variational coreset constructions rely on either selecting subsets of the observed datapoints, or jointly performing approximate inference and optimizing pseudodata in the observed space akin to inducing points methods in Gaussian Processes. So far, both approaches are limited by complexities in evaluating their objectives for general purpose models, and require generating samples from a typically intractable posterior over the coreset throughout inference and testing. In this work, we present a black-box variational inference framework for coresets that overcomes these constraints and enables principled application of variational coresets to intractable models, such as Bayesian neural networks. We apply our techniques to supervised learning problems, and compare them with existing approaches in the literature for data summarization and inference.
TyXe: Pyro-based Bayesian neural nets for Pytorch
Oct 01, 2021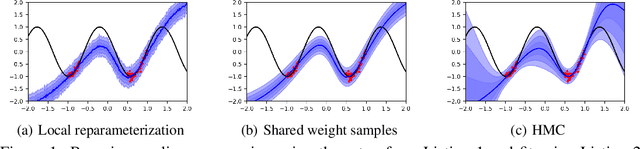
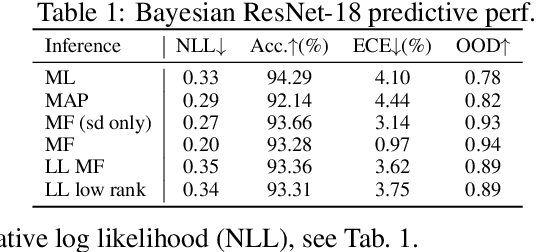
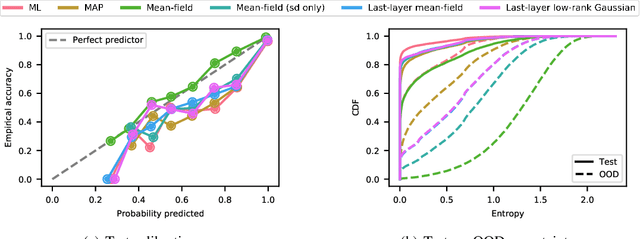

We introduce TyXe, a Bayesian neural network library built on top of Pytorch and Pyro. Our leading design principle is to cleanly separate architecture, prior, inference and likelihood specification, allowing for a flexible workflow where users can quickly iterate over combinations of these components. In contrast to existing packages TyXe does not implement any layer classes, and instead relies on architectures defined in generic Pytorch code. TyXe then provides modular choices for canonical priors, variational guides, inference techniques, and layer selections for a Bayesian treatment of the specified architecture. Sampling tricks for variance reduction, such as local reparameterization or flipout, are implemented as effect handlers, which can be applied independently of other specifications. We showcase the ease of use of TyXe to explore Bayesian versions of popular models from various libraries: toy regression with a pure Pytorch neural network; large-scale image classification with torchvision ResNets; graph neural networks based on DGL; and Neural Radiance Fields built on top of Pytorch3D. Finally, we provide convenient abstractions for variational continual learning. In all cases the change from a deterministic to a Bayesian neural network comes with minimal modifications to existing code, offering a broad range of researchers and practitioners alike practical access to uncertainty estimation techniques. The library is available at https://github.com/TyXe-BDL/TyXe.
Localized Uncertainty Attacks
Jun 17, 2021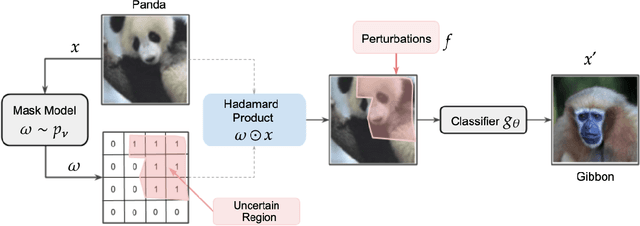
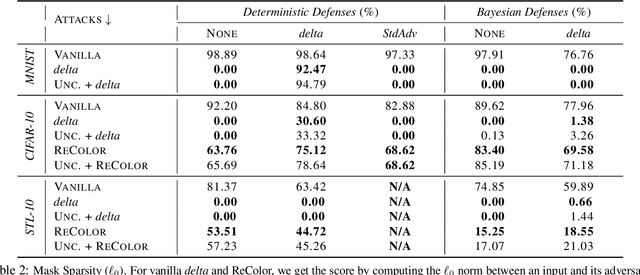
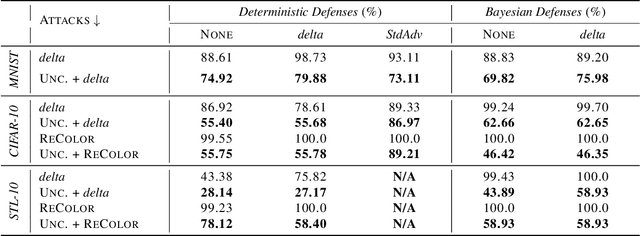

The susceptibility of deep learning models to adversarial perturbations has stirred renewed attention in adversarial examples resulting in a number of attacks. However, most of these attacks fail to encompass a large spectrum of adversarial perturbations that are imperceptible to humans. In this paper, we present localized uncertainty attacks, a novel class of threat models against deterministic and stochastic classifiers. Under this threat model, we create adversarial examples by perturbing only regions in the inputs where a classifier is uncertain. To find such regions, we utilize the predictive uncertainty of the classifier when the classifier is stochastic or, we learn a surrogate model to amortize the uncertainty when it is deterministic. Unlike $\ell_p$ ball or functional attacks which perturb inputs indiscriminately, our targeted changes can be less perceptible. When considered under our threat model, these attacks still produce strong adversarial examples; with the examples retaining a greater degree of similarity with the inputs.
Stochastic Aggregation in Graph Neural Networks
Feb 26, 2021
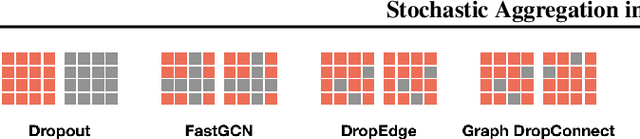
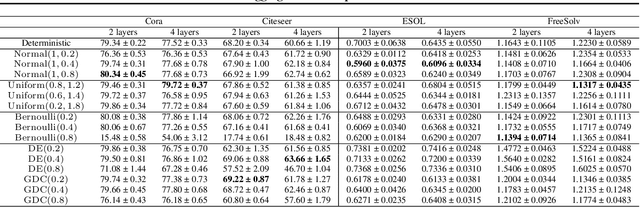
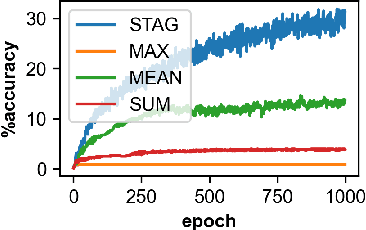
Graph neural networks (GNNs) manifest pathologies including over-smoothing and limited discriminating power as a result of suboptimally expressive aggregating mechanisms. We herein present a unifying framework for stochastic aggregation (STAG) in GNNs, where noise is (adaptively) injected into the aggregation process from the neighborhood to form node embeddings. We provide theoretical arguments that STAG models, with little overhead, remedy both of the aforementioned problems. In addition to fixed-noise models, we also propose probabilistic versions of STAG models and a variational inference framework to learn the noise posterior. We conduct illustrative experiments clearly targeting oversmoothing and multiset aggregation limitations. Furthermore, STAG enhances general performance of GNNs demonstrated by competitive performance in common citation and molecule graph benchmark datasets.
Variational Auto-Regressive Gaussian Processes for Continual Learning
Jun 09, 2020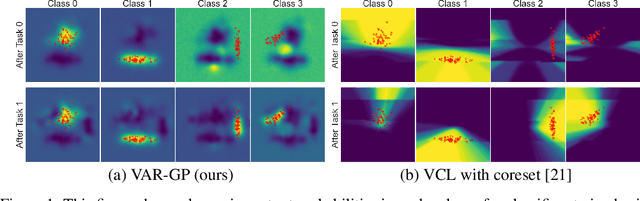
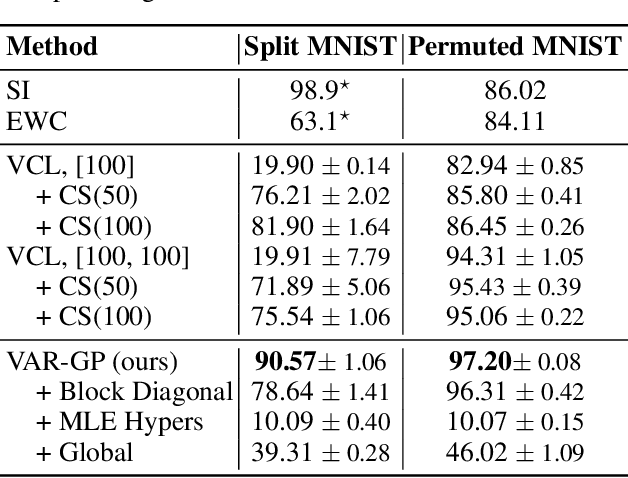

This paper proposes Variational Auto-Regressive Gaussian Process (VAR-GP), a principled Bayesian updating mechanism to incorporate new data for sequential tasks in the context of continual learning. It relies on a novel auto-regressive characterization of the variational distribution and inference is made scalable using sparse inducing point approximations. Experiments on standard continual learning benchmarks demonstrate the ability of VAR-GPs to perform well at new tasks without compromising performance on old ones, yielding competitive results to state-of-the-art methods. In addition, we qualitatively show how VAR-GP improves the predictive entropy estimates as we train on new tasks. Further, we conduct a thorough ablation study to verify the effectiveness of inferential choices.
Hierarchical Gaussian Process Priors for Bayesian Neural Network Weights
Feb 10, 2020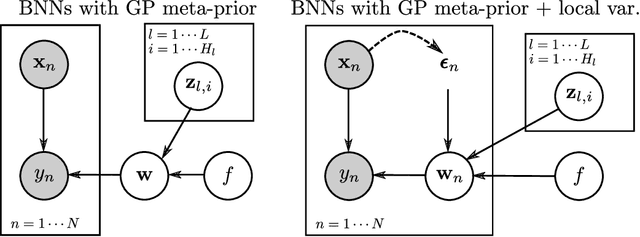
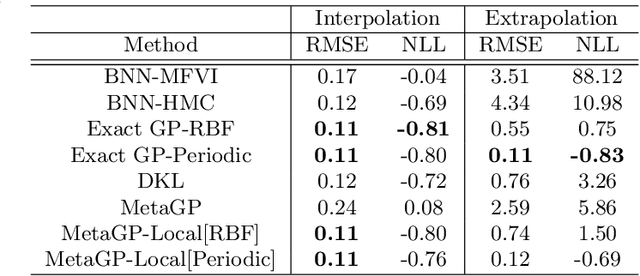
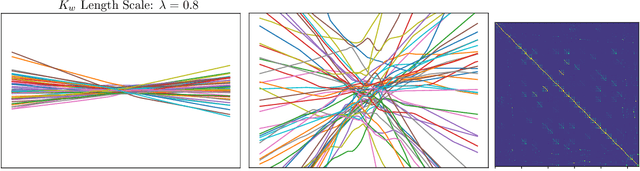
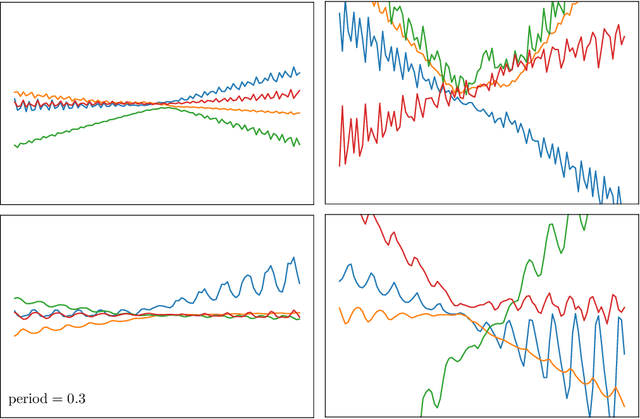
Probabilistic neural networks are typically modeled with independent weight priors, which do not capture weight correlations in the prior and do not provide a parsimonious interface to express properties in function space. A desirable class of priors would represent weights compactly, capture correlations between weights, facilitate calibrated reasoning about uncertainty, and allow inclusion of prior knowledge about the function space such as periodicity or dependence on contexts such as inputs. To this end, this paper introduces two innovations: (i) a Gaussian process-based hierarchical model for network weights based on unit embeddings that can flexibly encode correlated weight structures, and (ii) input-dependent versions of these weight priors that can provide convenient ways to regularize the function space through the use of kernels defined on contextual inputs. We show these models provide desirable test-time uncertainty estimates on out-of-distribution data, demonstrate cases of modeling inductive biases for neural networks with kernels which help both interpolation and extrapolation from training data, and demonstrate competitive predictive performance on an active learning benchmark.
Generalized Hidden Parameter MDPs Transferable Model-based RL in a Handful of Trials
Feb 08, 2020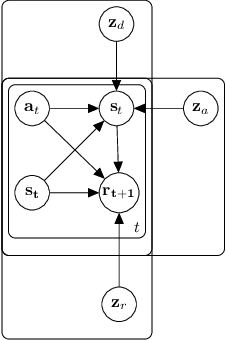
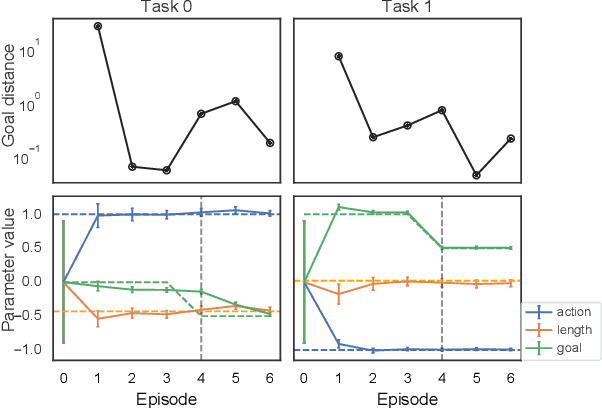
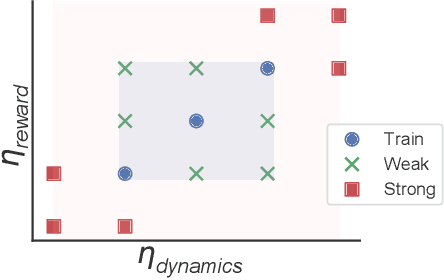
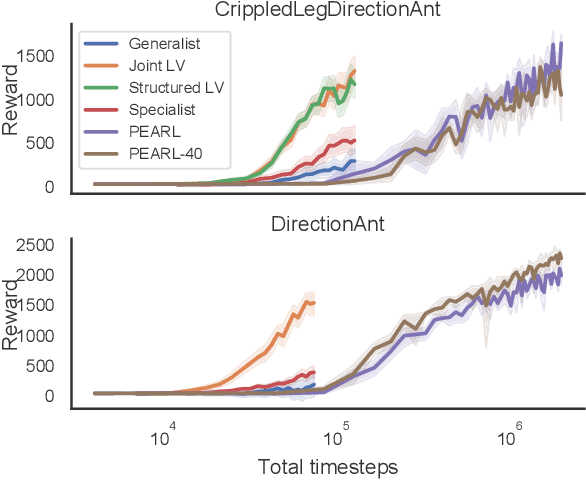
There is broad interest in creating RL agents that can solve many (related) tasks and adapt to new tasks and environments after initial training. Model-based RL leverages learned surrogate models that describe dynamics and rewards of individual tasks, such that planning in a good surrogate can lead to good control of the true system. Rather than solving each task individually from scratch, hierarchical models can exploit the fact that tasks are often related by (unobserved) causal factors of variation in order to achieve efficient generalization, as in learning how the mass of an item affects the force required to lift it can generalize to previously unobserved masses. We propose Generalized Hidden Parameter MDPs (GHP-MDPs) that describe a family of MDPs where both dynamics and reward can change as a function of hidden parameters that vary across tasks. The GHP-MDP augments model-based RL with latent variables that capture these hidden parameters, facilitating transfer across tasks. We also explore a variant of the model that incorporates explicit latent structure mirroring the causal factors of variation across tasks (for instance: agent properties, environmental factors, and goals). We experimentally demonstrate state-of-the-art performance and sample-efficiency on a new challenging MuJoCo task using reward and dynamics latent spaces, while beating a previous state-of-the-art baseline with $>10\times$ less data. Using test-time inference of the latent variables, our approach generalizes in a single episode to novel combinations of dynamics and reward, and to novel rewards.