 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomata-based constraints for language model decoding
Jul 11, 2024



LMs are often expected to generate strings in some formal language; for example, structured data, API calls, or code snippets. Although LMs can be tuned to improve their adherence to formal syntax, this does not guarantee conformance, especially with smaller LMs suitable for large-scale deployment. In addition, tuning requires significant resources, making it impractical for uncommon or task-specific formats. To prevent downstream parsing errors we would ideally constrain the LM to only produce valid output, but this is severely complicated by tokenization, which is typically both ambiguous and misaligned with the formal grammar. We solve these issues through the application of automata theory, deriving an efficient closed-form solution for the regular languages, a broad class of formal languages with many practical applications, including API calls or schema-guided JSON and YAML. We also discuss pragmatic extensions for coping with the issue of high branching factor. Finally, we extend our techniques to deterministic context-free languages, which similarly admit an efficient closed-form solution. In spite of its flexibility and representative power, our approach only requires access to per-token decoding logits and lowers into simple calculations that are independent of LM size, making it both efficient and easy to apply to almost any LM architecture.
SyntaxNet Models for the CoNLL 2017 Shared Task
Mar 15, 2017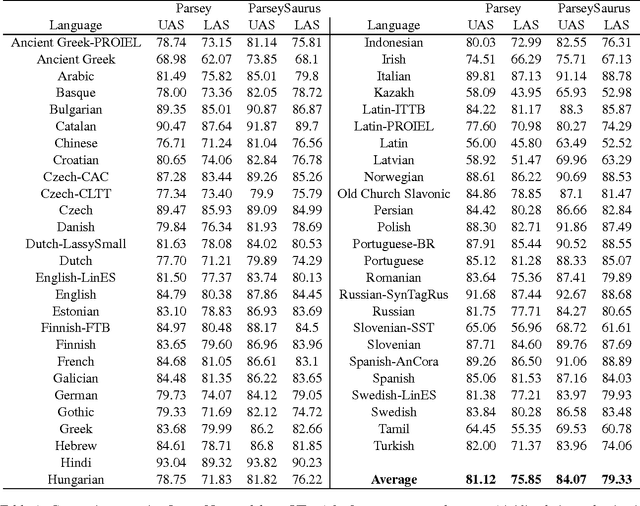
We describe a baseline dependency parsing system for the CoNLL2017 Shared Task. This system, which we call "ParseySaurus," uses the DRAGNN framework [Kong et al, 2017] to combine transition-based recurrent parsing and tagging with character-based word representations. On the v1.3 Universal Dependencies Treebanks, the new system outpeforms the publicly available, state-of-the-art "Parsey's Cousins" models by 3.47% absolute Labeled Accuracy Score (LAS) across 52 treebanks.
Grammar as a Foreign Language
Jun 09, 2015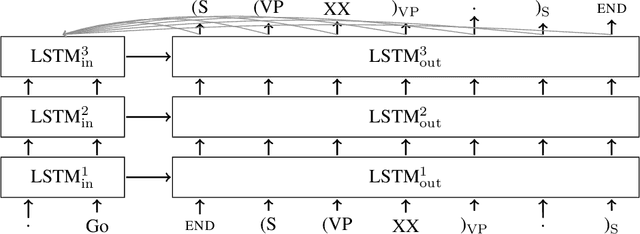
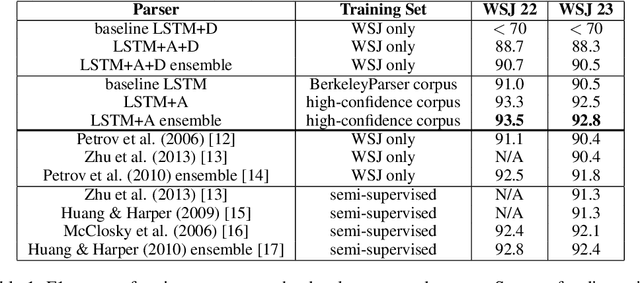
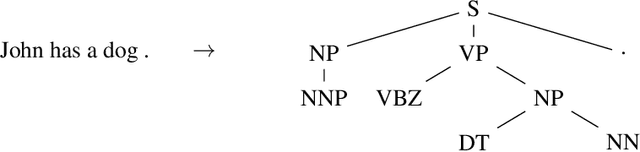
Syntactic constituency parsing is a fundamental problem in natural language processing and has been the subject of intensive research and engineering for decades. As a result, the most accurate parsers are domain specific, complex, and inefficient. In this paper we show that the domain agnostic attention-enhanced sequence-to-sequence model achieves state-of-the-art results on the most widely used syntactic constituency parsing dataset, when trained on a large synthetic corpus that was annotated using existing parsers. It also matches the performance of standard parsers when trained only on a small human-annotated dataset, which shows that this model is highly data-efficient, in contrast to sequence-to-sequence models without the attention mechanism. Our parser is also fast, processing over a hundred sentences per second with an unoptimized CPU implementation.