 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Molecule Pre-training with Flexible 2D and 3D Modalities: Single and Paired Modality Integration
Oct 08, 2025Molecular representation learning plays a crucial role in advancing applications such as drug discovery and material design. Existing work leverages 2D and 3D modalities of molecular information for pre-training, aiming to capture comprehensive structural and geometric insights. However, these methods require paired 2D and 3D molecular data to train the model effectively and prevent it from collapsing into a single modality, posing limitations in scenarios where a certain modality is unavailable or computationally expensive to generate. To overcome this limitation, we propose FlexMol, a flexible molecule pre-training framework that learns unified molecular representations while supporting single-modality input. Specifically, inspired by the unified structure in vision-language models, our approach employs separate models for 2D and 3D molecular data, leverages parameter sharing to improve computational efficiency, and utilizes a decoder to generate features for the missing modality. This enables a multistage continuous learning process where both modalities contribute collaboratively during training, while ensuring robustness when only one modality is available during inference. Extensive experiments demonstrate that FlexMol achieves superior performance across a wide range of molecular property prediction tasks, and we also empirically demonstrate its effectiveness with incomplete data. Our code and data are available at https://github.com/tewiSong/FlexMol.
Modulate Your Spectrum in Self-Supervised Learning
May 26, 2023



Whitening loss provides theoretical guarantee in avoiding feature collapse for self-supervised learning (SSL) using joint embedding architectures. One typical implementation of whitening loss is hard whitening that designs whitening transformation over embedding and imposes the loss on the whitened output. In this paper, we propose spectral transformation (ST) framework to map the spectrum of embedding to a desired distribution during forward pass, and to modulate the spectrum of embedding by implicit gradient update during backward pass. We show that whitening transformation is a special instance of ST by definition, and there exist other instances that can avoid collapse by our empirical investigation. Furthermore, we propose a new instance of ST, called IterNorm with trace loss (INTL). We theoretically prove that INTL can avoid collapse and modulate the spectrum of embedding towards an equal-eigenvalue distribution during the course of optimization. Moreover, INTL achieves 76.6% top-1 accuracy in linear evaluation on ImageNet using ResNet-50, which exceeds the performance of the supervised baseline, and this result is obtained by using a batch size of only 256. Comprehensive experiments show that INTL is a promising SSL method in practice. The code is available at https://github.com/winci-ai/intl.
Rot-Pro: Modeling Transitivity by Projection in Knowledge Graph Embedding
Oct 27, 2021
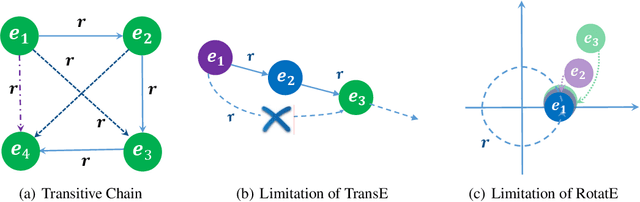
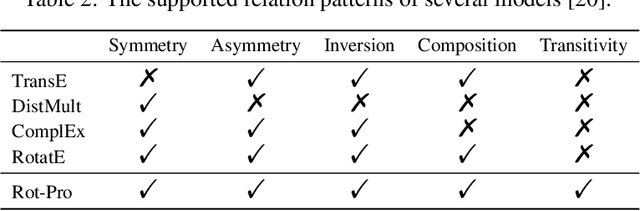
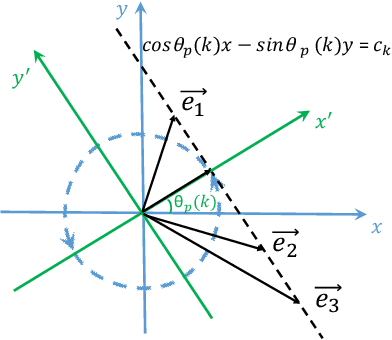
Knowledge graph embedding models learn the representations of entities and relations in the knowledge graphs for predicting missing links (relations) between entities. Their effectiveness are deeply affected by the ability of modeling and inferring different relation patterns such as symmetry, asymmetry, inversion, composition and transitivity. Although existing models are already able to model many of these relations patterns, transitivity, a very common relation pattern, is still not been fully supported. In this paper, we first theoretically show that the transitive relations can be modeled with projections. We then propose the Rot-Pro model which combines the projection and relational rotation together. We prove that Rot-Pro can infer all the above relation patterns. Experimental results show that the proposed Rot-Pro model effectively learns the transitivity pattern and achieves the state-of-the-art results on the link prediction task in the datasets containing transitive relations.