 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary Semantic Segmentation Network Integrating Object-Level Label and Scene-Level Semantic Features for Multimodal Remote Sensing Images
Apr 27, 2026Semantic segmentation of multi-modal remote sensing imagery plays a pivotal role in land use/land cover (LULC) mapping, environmental monitoring, and precision earth observation. Current multi-modal approaches mainly focus on integrating complementary visual modalities, yet neglect the incorporating of non-visual textual data - a rich source of knowledge that can bridge semantic gaps between visual patterns and real-world concepts. To address this limitation, we propose TSMNet, a text supervised multi-modal open vocabulary semantic segmentation network that synergistically integrates textual supervision with visual representation for open-vocabulary semantic segmentation. Unlike conventional multi-modal segmentation frameworks, TSMNet introduces a dual-branch text encoder to extract both scene-level semantic and object-level label information from various textual data, enabling dynamic cross-modal fusion. These text-derived features dynamically interact with visual embeddings through the proposed text-guided visual semantic fusion module, enabling domain-aware feature refinement and human-interpretable decision-making. To verify our method, we innovatively construct two new multi-modal datasets, and carry out extensive experiments to make a comprehensive comparison between the proposed method and other state-of-the-art (SOTA) semantic segmentation models. Results demonstrate that TSMNet achieves superior segmentation accuracy while exhibiting robust generalization capabilities across diverse geographical and sensor-specific scenarios. This work establishes a new paradigm for explainable remote sensing analysis, demonstrating that textual knowledge integration significantly enhances model generalizability. The source code will be available at https://github.com/yeyuanxin110/TSMNet
A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-order Gradients
Feb 27, 2022

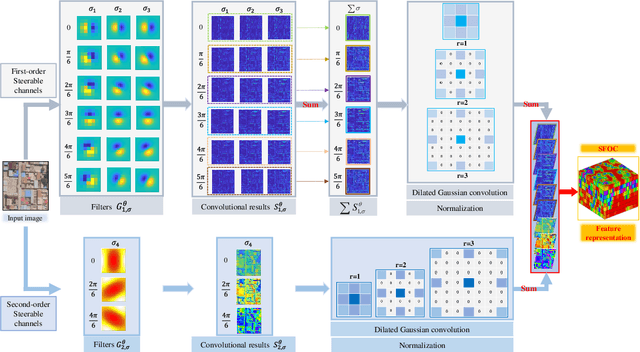

Co-registration of multimodal remote sensing images is still an ongoing challenge because of nonlinear radiometric differences (NRD) and significant geometric distortions (e.g., scale and rotation changes) between these images. In this paper, a robust matching method based on the Steerable filters is proposed consisting of two critical steps. First, to address severe NRD, a novel structural descriptor named the Steerable Filters of first- and second-Order Channels (SFOC) is constructed, which combines the first- and second-order gradient information by using the steerable filters with a multi-scale strategy to depict more discriminative structure features of images. Then, a fast similarity measure is established called Fast Normalized Cross-Correlation (Fast-NCCSFOC), which employs the Fast Fourier Transform technique and the integral image to improve the matching efficiency. Furthermore, to achieve reliable registration performance, a coarse-to-fine multimodal registration system is designed consisting of two pivotal modules. The local coarse registration is first conducted by involving both detection of interest points (IPs) and local geometric correction, which effectively utilizes the prior georeferencing information of RS images to address global geometric distortions. In the fine registration stage, the proposed SFOC is used to resist significant NRD, and to detect control points between multimodal images by a template matching scheme. The performance of the proposed matching method has been evaluated with many different kinds of multimodal RS images. The results show its superior matching performance compared with the state-of-the-art methods. Moreover, the designed registration system also outperforms the popular commercial software in both registration accuracy and computational efficiency. Our system is available at https://github.com/yeyuanxin110.