 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Verified Semantic Caching for Tiered LLM Architectures
Feb 13, 2026Large language models (LLMs) now sit in the critical path of search, assistance, and agentic workflows, making semantic caching essential for reducing inference cost and latency. Production deployments typically use a tiered static-dynamic design: a static cache of curated, offline vetted responses mined from logs, backed by a dynamic cache populated online. In practice, both tiers are commonly governed by a single embedding similarity threshold, which induces a hard tradeoff: conservative thresholds miss safe reuse opportunities, while aggressive thresholds risk serving semantically incorrect responses. We introduce \textbf{Krites}, an asynchronous, LLM-judged caching policy that expands static coverage without changing serving decisions. On the critical path, Krites behaves exactly like a standard static threshold policy. When the nearest static neighbor of the prompt falls just below the static threshold, Krites asynchronously invokes an LLM judge to verify whether the static response is acceptable for the new prompt. Approved matches are promoted into the dynamic cache, allowing future repeats and paraphrases to reuse curated static answers and expanding static reach over time. In trace-driven simulations on conversational and search workloads, Krites increases the fraction of requests served with curated static answers (direct static hits plus verified promotions) by up to $\textbf{3.9}$ times for conversational traffic and search-style queries relative to tuned baselines, with unchanged critical path latency.
Masked COVID-19 Trends from Social Media
Oct 30, 2020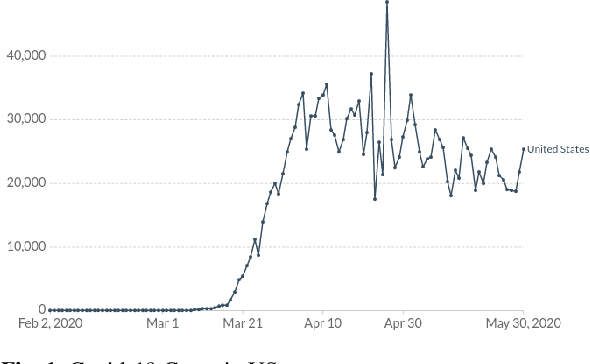
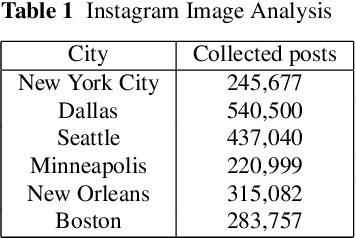

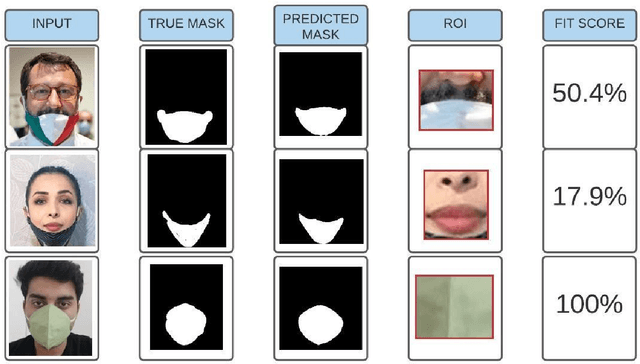
COVID-19 has affected the entire world. One useful protection method for people against COVID-19 is to wear masks in public areas. Across the globe, many public service providers have mandated correctly wearing masks to use their services. This paper proposes two new datasets VAriety MAsks - Classification VAMA-C) and VAriety MAsks - Segmentation (VAMA-S), for mask detection and mask fit analysis tasks, respectively. We propose a framework for classifying masked and unmasked faces and a segmentation based model to calculate the mask-fit score. Both the models trained in this study achieved an accuracy of 98%. Using the two trained deep learning models, 2.04 million social media images for six major US cities were analyzed. By comparing the regulations, an increase in masks worn in images as the COVID-19 cases rose in these cities was observed, particularly when their respective states imposed strict regulations. Furthermore, mask compliance in the Black Lives Matter protest was analyzed, eliciting that 40% of the people in group photos wore masks, and 45% of them wore the masks with a fit score of greater than 80%.