 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering News Recommendation with Pre-trained Language Models
Apr 15, 2021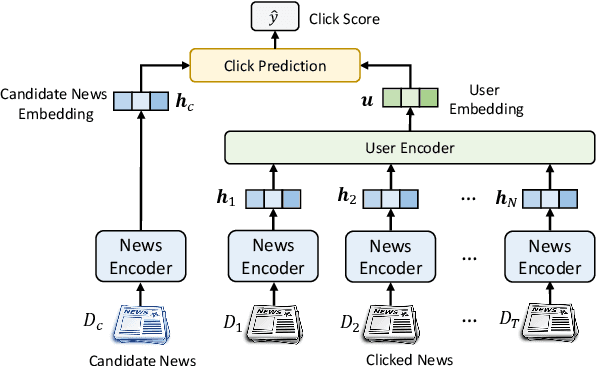
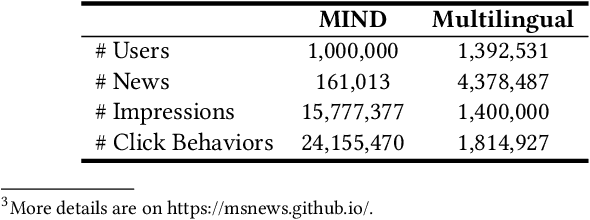
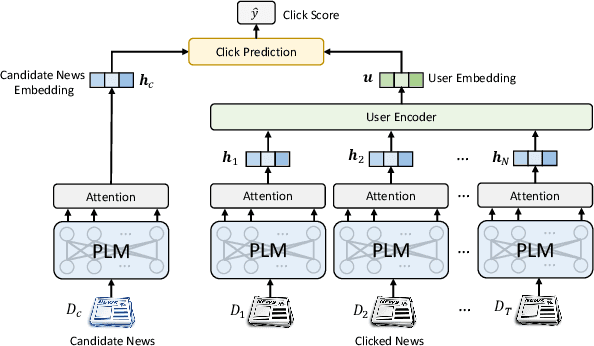
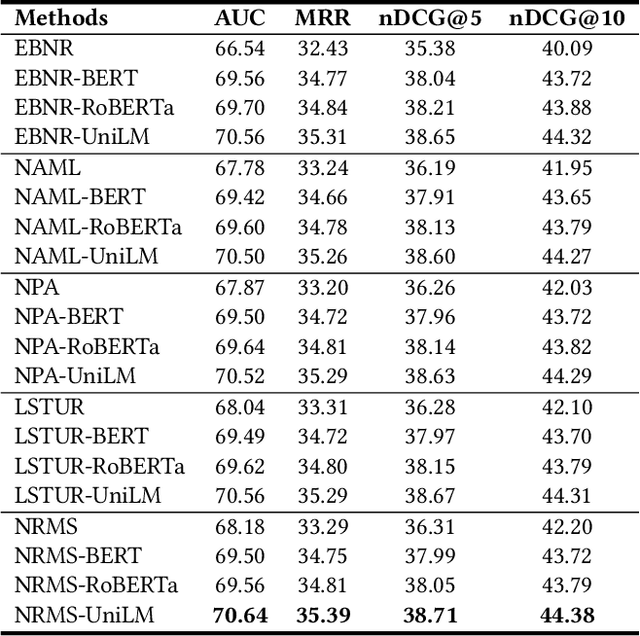
Personalized news recommendation is an essential technique for online news services. News articles usually contain rich textual content, and accurate news modeling is important for personalized news recommendation. Existing news recommendation methods mainly model news texts based on traditional text modeling methods, which is not optimal for mining the deep semantic information in news texts. Pre-trained language models (PLMs) are powerful for natural language understanding, which has the potential for better news modeling. However, there is no public report that show PLMs have been applied to news recommendation. In this paper, we report our work on exploiting pre-trained language models to empower news recommendation. Offline experimental results on both monolingual and multilingual news recommendation datasets show that leveraging PLMs for news modeling can effectively improve the performance of news recommendation. Our PLM-empowered news recommendation models have been deployed to the Microsoft News platform, and achieved significant gains in terms of both click and pageview in both English-speaking and global markets.
MM-Rec: Multimodal News Recommendation
Apr 15, 2021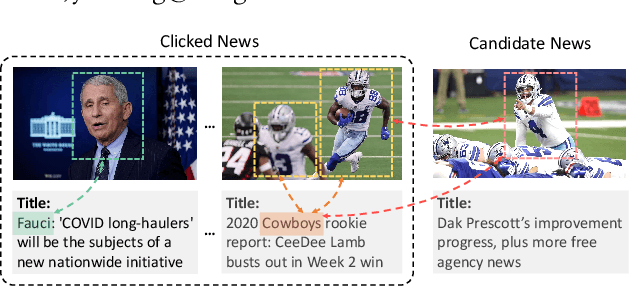

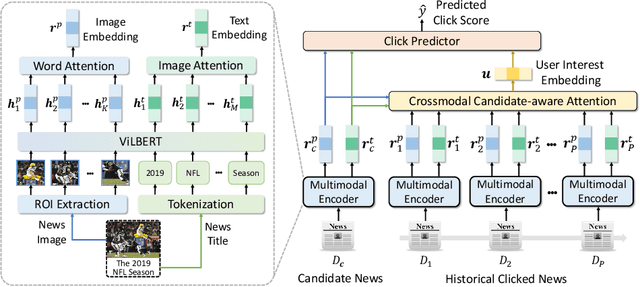
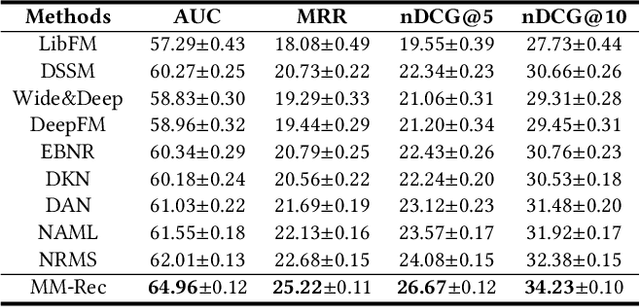
Accurate news representation is critical for news recommendation. Most of existing news representation methods learn news representations only from news texts while ignore the visual information in news like images. In fact, users may click news not only because of the interest in news titles but also due to the attraction of news images. Thus, images are useful for representing news and predicting user behaviors. In this paper, we propose a multimodal news recommendation method, which can incorporate both textual and visual information of news to learn multimodal news representations. We first extract region-of-interests (ROIs) from news images via objective detection. Then we use a pre-trained visiolinguistic model to encode both news texts and news image ROIs and model their inherent relatedness using co-attentional Transformers. In addition, we propose a crossmodal candidate-aware attention network to select relevant historical clicked news for accurate user modeling by measuring the crossmodal relatedness between clicked news and candidate news. Experiments validate that incorporating multimodal news information can effectively improve news recommendation.
Two Birds with One Stone: Unified Model Learning for Both Recall and Ranking in News Recommendation
Apr 15, 2021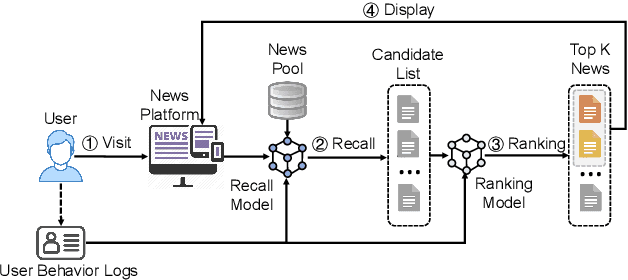

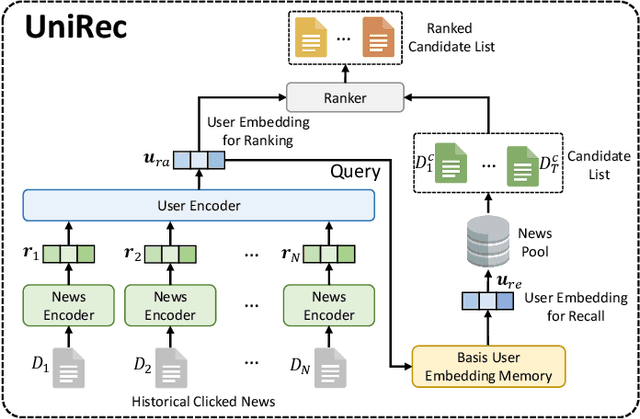
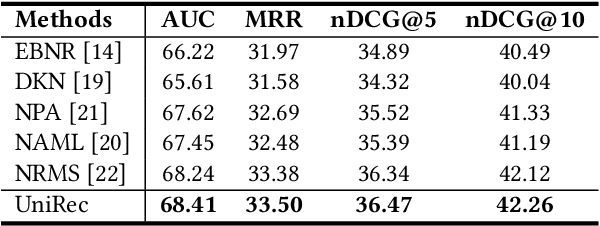
Recall and ranking are two critical steps in personalized news recommendation. Most existing news recommender systems conduct personalized news recall and ranking separately with different models. However, maintaining multiple models leads to high computational cost and poses great challenge to meeting the online latency requirement of news recommender systems. In order to handle this problem, in this paper we propose UniRec, a unified method for recall and ranking in news recommendation. In our method, we first infer user embedding for ranking from the historical news click behaviors of a user using a user encoder model. Then we derive the user embedding for recall from the obtained user embedding for ranking by using it as the attention query to select a set of basis user embeddings which encode different general user interests and synthesize them into a user embedding for recall. The extensive experiments on benchmark dataset demonstrate that our method can improve both efficiency and effectiveness for recall and ranking in news recommendation.
FeedRec: News Feed Recommendation with Various User Feedbacks
Feb 09, 2021
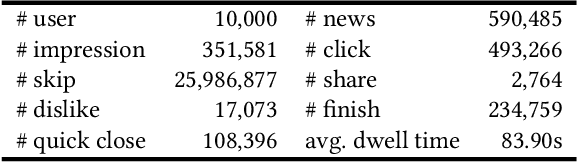
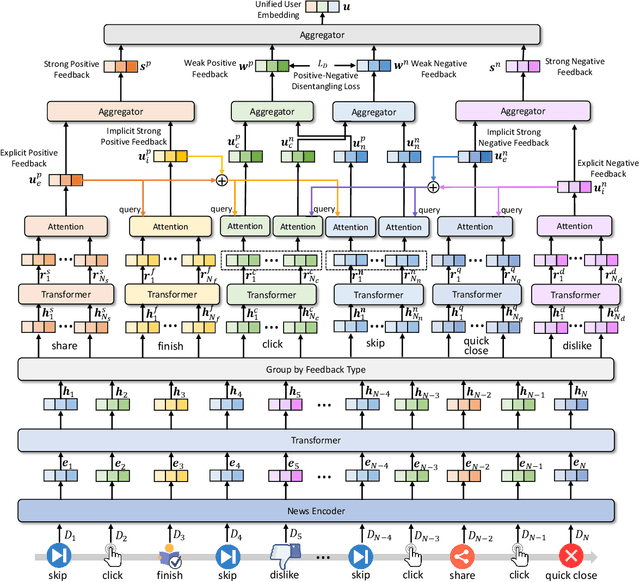
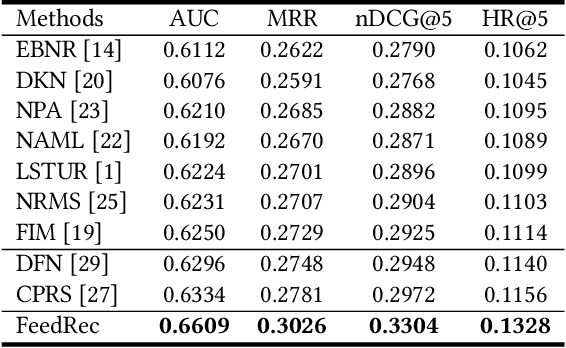
Personalized news recommendation techniques are widely adopted by many online news feed platforms to target user interests. Learning accurate user interest models is important for news recommendation. Most existing methods for news recommendation rely on implicit feedbacks like click behaviors for inferring user interests and model training. However, click behaviors are implicit feedbacks and usually contain heavy noise. In addition, they cannot help infer complicated user interest such as dislike. Besides, the feed recommendation models trained solely on click behaviors cannot optimize other objectives such as user engagement. In this paper, we present a news feed recommendation method that can exploit various kinds of user feedbacks to enhance both user interest modeling and recommendation model training. In our method we propose a unified user modeling framework to incorporate various explicit and implicit user feedbacks to infer both positive and negative user interests. In addition, we propose a strong-to-weak attention network that uses the representations of stronger feedbacks to distill positive and negative user interests from implicit weak feedbacks for accurate user interest modeling. Besides, we propose a multi-feedback model training framework by jointly training the model in the click, finish and dwell time prediction tasks to learn an engagement-aware feed recommendation model. Extensive experiments on real-world dataset show that our approach can effectively improve the model performance in terms of both news clicks and user engagement.
NewsBERT: Distilling Pre-trained Language Model for Intelligent News Application
Feb 09, 2021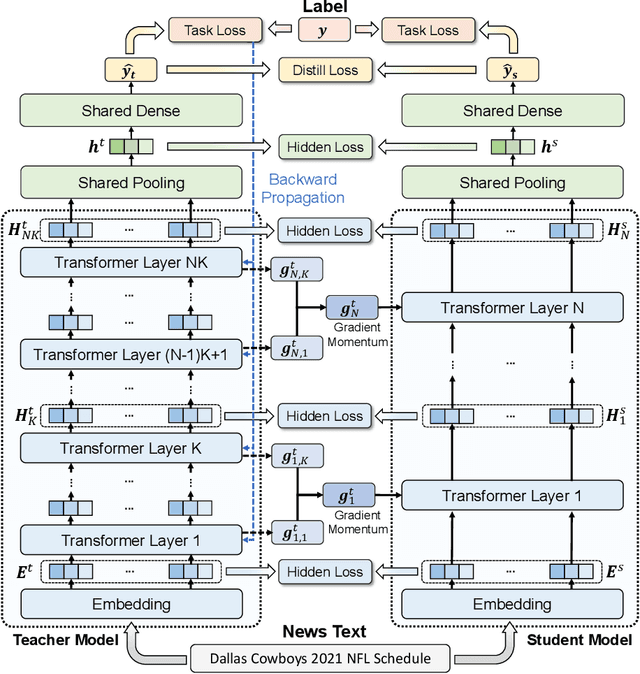
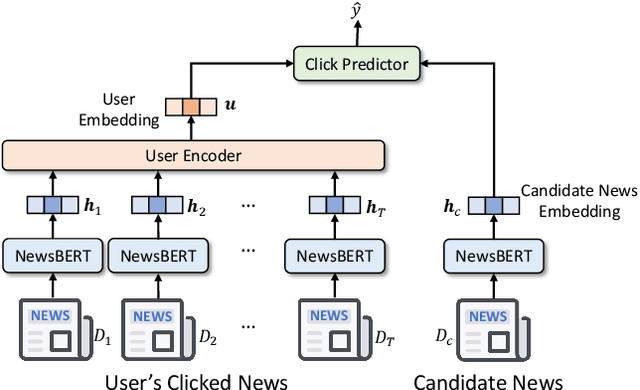
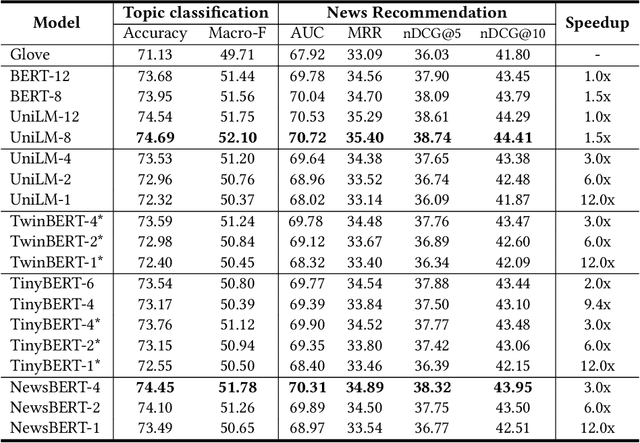
Pre-trained language models (PLMs) like BERT have made great progress in NLP. News articles usually contain rich textual information, and PLMs have the potentials to enhance news text modeling for various intelligent news applications like news recommendation and retrieval. However, most existing PLMs are in huge size with hundreds of millions of parameters. Many online news applications need to serve millions of users with low latency tolerance, which poses huge challenges to incorporating PLMs in these scenarios. Knowledge distillation techniques can compress a large PLM into a much smaller one and meanwhile keeps good performance. However, existing language models are pre-trained and distilled on general corpus like Wikipedia, which has some gaps with the news domain and may be suboptimal for news intelligence. In this paper, we propose NewsBERT, which can distill PLMs for efficient and effective news intelligence. In our approach, we design a teacher-student joint learning and distillation framework to collaboratively learn both teacher and student models, where the student model can learn from the learning experience of the teacher model. In addition, we propose a momentum distillation method by incorporating the gradients of teacher model into the update of student model to better transfer useful knowledge learned by the teacher model. Extensive experiments on two real-world datasets with three tasks show that NewsBERT can effectively improve the model performance in various intelligent news applications with much smaller models.
Improving Attention Mechanism with Query-Value Interaction
Oct 08, 2020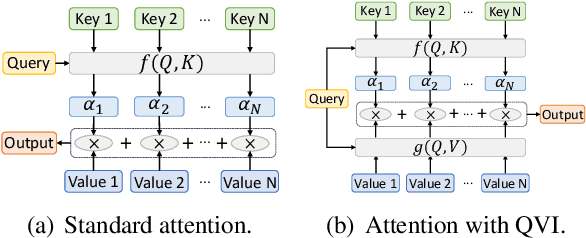
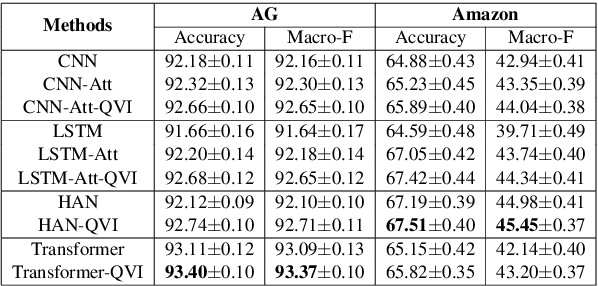
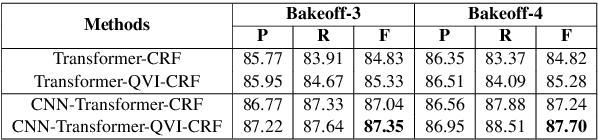
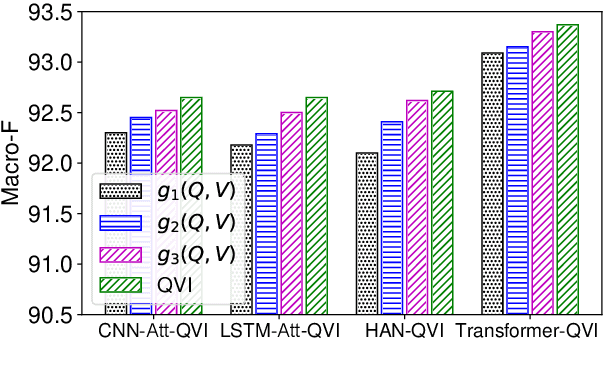
Attention mechanism has played critical roles in various state-of-the-art NLP models such as Transformer and BERT. It can be formulated as a ternary function that maps the input queries, keys and values into an output by using a summation of values weighted by the attention weights derived from the interactions between queries and keys. Similar with query-key interactions, there is also inherent relatedness between queries and values, and incorporating query-value interactions has the potential to enhance the output by learning customized values according to the characteristics of queries. However, the query-value interactions are ignored by existing attention methods, which may be not optimal. In this paper, we propose to improve the existing attention mechanism by incorporating query-value interactions. We propose a query-value interaction function which can learn query-aware attention values, and combine them with the original values and attention weights to form the final output. Extensive experiments on four datasets for different tasks show that our approach can consistently improve the performance of many attention-based models by incorporating query-value interactions.
Graph Enhanced Representation Learning for News Recommendation
Mar 31, 2020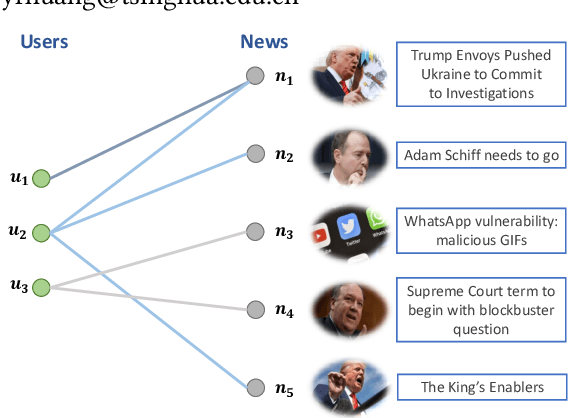
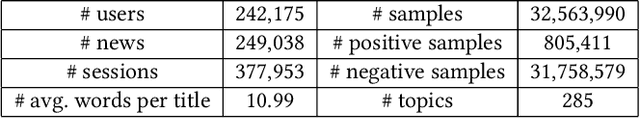
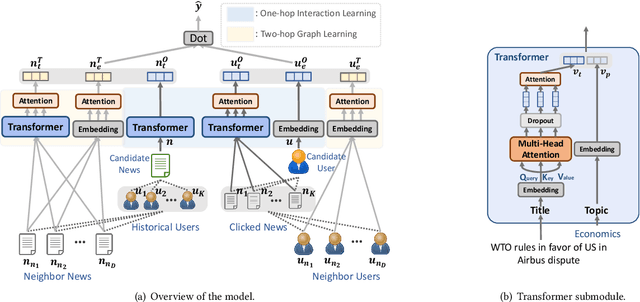
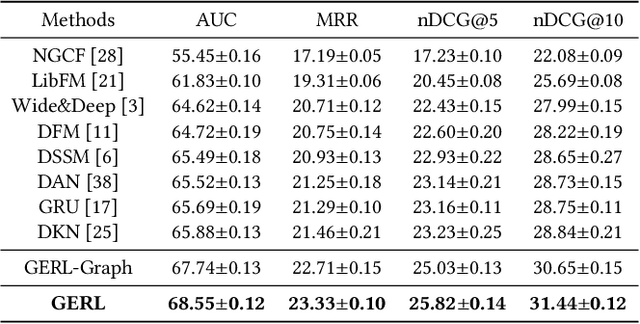
With the explosion of online news, personalized news recommendation becomes increasingly important for online news platforms to help their users find interesting information. Existing news recommendation methods achieve personalization by building accurate news representations from news content and user representations from their direct interactions with news (e.g., click), while ignoring the high-order relatedness between users and news. Here we propose a news recommendation method which can enhance the representation learning of users and news by modeling their relatedness in a graph setting. In our method, users and news are both viewed as nodes in a bipartite graph constructed from historical user click behaviors. For news representations, a transformer architecture is first exploited to build news semantic representations. Then we combine it with the information from neighbor news in the graph via a graph attention network. For user representations, we not only represent users from their historically clicked news, but also attentively incorporate the representations of their neighbor users in the graph. Improved performances on a large-scale real-world dataset validate the effectiveness of our proposed method.
FedNER: Privacy-preserving Medical Named Entity Recognition with Federated Learning
Mar 25, 2020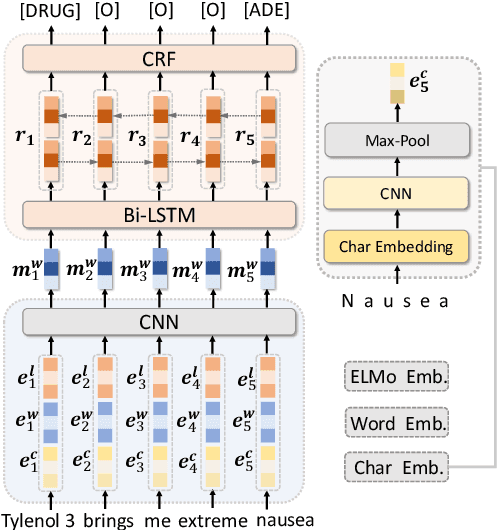
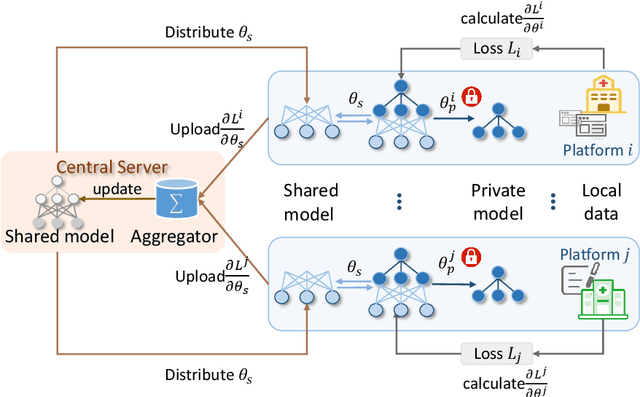
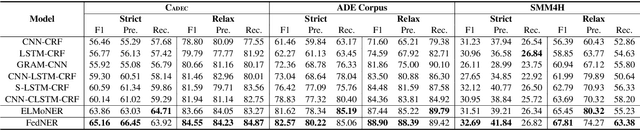
Medical named entity recognition (NER) has wide applications in intelligent healthcare. Sufficient labeled data is critical for training accurate medical NER model. However, the labeled data in a single medical platform is usually limited. Although labeled datasets may exist in many different medical platforms, they cannot be directly shared since medical data is highly privacy-sensitive. In this paper, we propose a privacy-preserving medical NER method based on federated learning, which can leverage the labeled data in different platforms to boost the training of medical NER model and remove the need of exchanging raw data among different platforms. Since the labeled data in different platforms usually has some differences in entity type and annotation criteria, instead of constraining different platforms to share the same model, we decompose the medical NER model in each platform into a shared module and a private module. The private module is used to capture the characteristics of the local data in each platform, and is updated using local labeled data. The shared module is learned across different medical platform to capture the shared NER knowledge. Its local gradients from different platforms are aggregated to update the global shared module, which is further delivered to each platform to update their local shared modules. Experiments on three publicly available datasets validate the effectiveness of our method.