 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fast PC algorithm for high dimensional causal discovery with multi-core PCs
Nov 10, 2016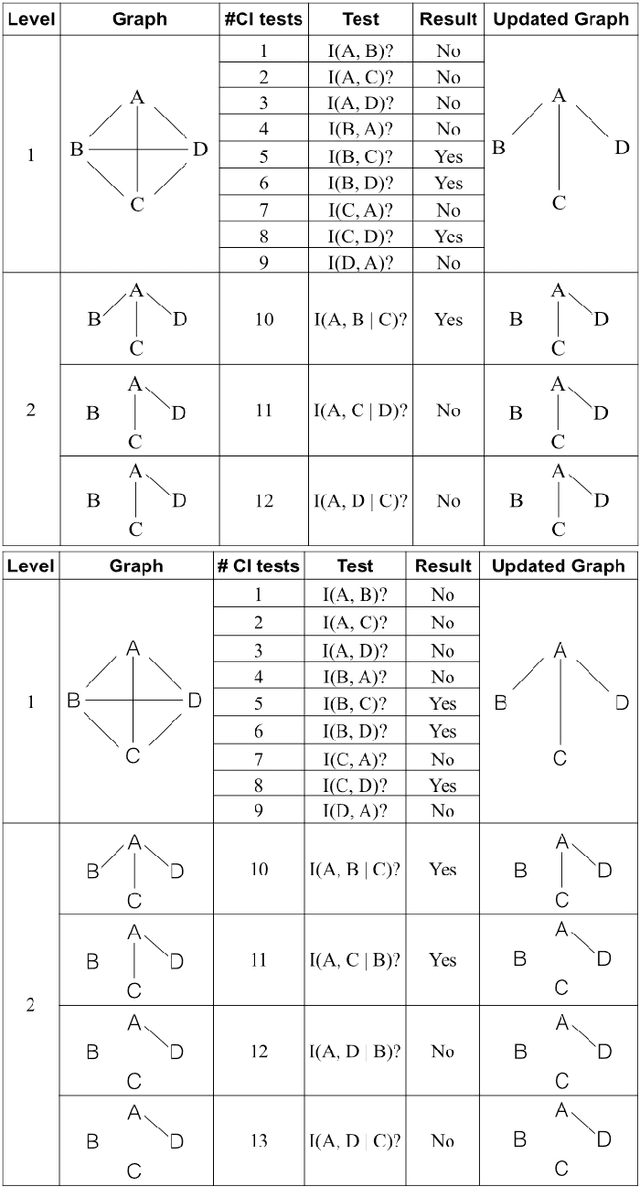
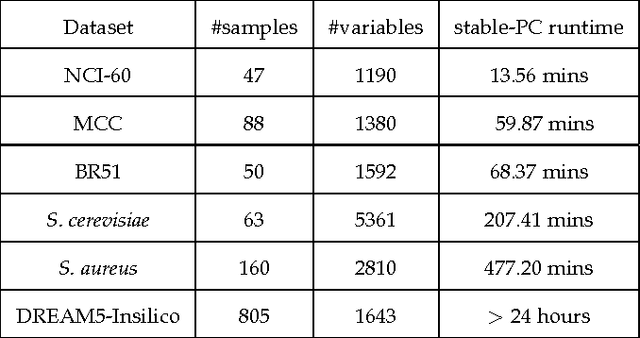
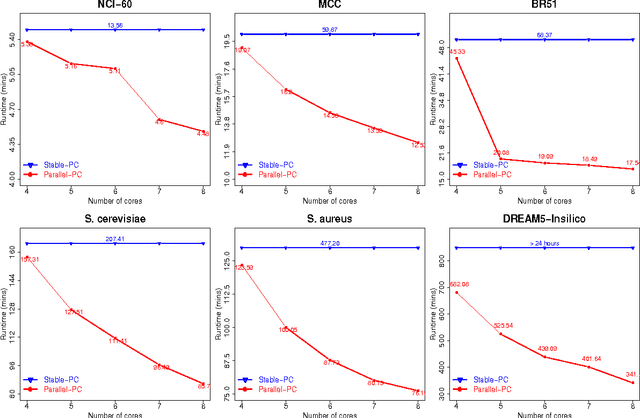
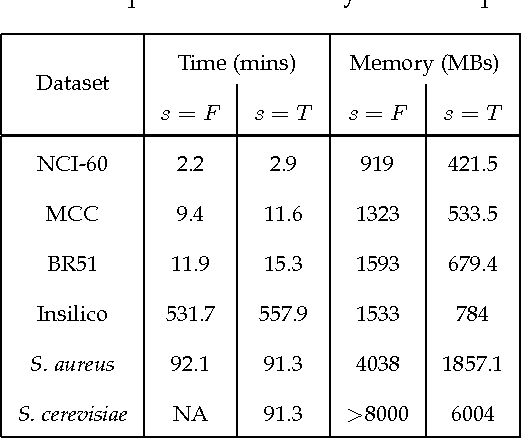
Discovering causal relationships from observational data is a crucial problem and it has applications in many research areas. The PC algorithm is the state-of-the-art constraint based method for causal discovery. However, runtime of the PC algorithm, in the worst-case, is exponential to the number of nodes (variables), and thus it is inefficient when being applied to high dimensional data, e.g. gene expression datasets. On another note, the advancement of computer hardware in the last decade has resulted in the widespread availability of multi-core personal computers. There is a significant motivation for designing a parallelised PC algorithm that is suitable for personal computers and does not require end users' parallel computing knowledge beyond their competency in using the PC algorithm. In this paper, we develop parallel-PC, a fast and memory efficient PC algorithm using the parallel computing technique. We apply our method to a range of synthetic and real-world high dimensional datasets. Experimental results on a dataset from the DREAM 5 challenge show that the original PC algorithm could not produce any results after running more than 24 hours; meanwhile, our parallel-PC algorithm managed to finish within around 12 hours with a 4-core CPU computer, and less than 6 hours with a 8-core CPU computer. Furthermore, we integrate parallel-PC into a causal inference method for inferring miRNA-mRNA regulatory relationships. The experimental results show that parallel-PC helps improve both the efficiency and accuracy of the causal inference algorithm.
ParallelPC: an R package for efficient constraint based causal exploration
Oct 11, 2015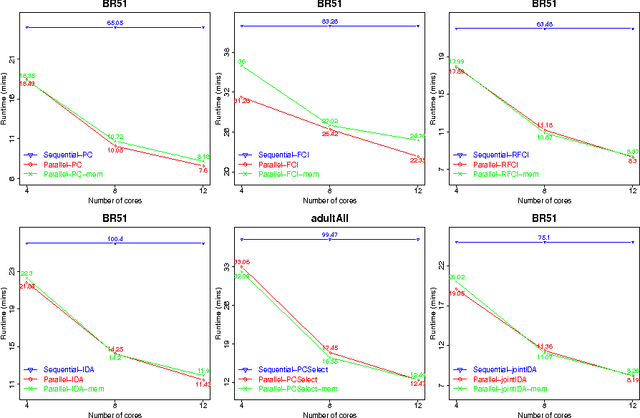
Discovering causal relationships from data is the ultimate goal of many research areas. Constraint based causal exploration algorithms, such as PC, FCI, RFCI, PC-simple, IDA and Joint-IDA have achieved significant progress and have many applications. A common problem with these methods is the high computational complexity, which hinders their applications in real world high dimensional datasets, e.g gene expression datasets. In this paper, we present an R package, ParallelPC, that includes the parallelised versions of these causal exploration algorithms. The parallelised algorithms help speed up the procedure of experimenting big datasets and reduce the memory used when running the algorithms. The package is not only suitable for super-computers or clusters, but also convenient for researchers using personal computers with multi core CPUs. Our experiment results on real world datasets show that using the parallelised algorithms it is now practical to explore causal relationships in high dimensional datasets with thousands of variables in a single multicore computer. ParallelPC is available in CRAN repository at https://cran.rproject.org/web/packages/ParallelPC/index.html.