 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Early Indicators of Cognitive Decline from Verbal Utterances
Nov 19, 2020



Dementia is a group of irreversible, chronic, and progressive neurodegenerative disorders resulting in impaired memory, communication, and thought processes. In recent years, clinical research advances in brain aging have focused on the earliest clinically detectable stage of incipient dementia, commonly known as mild cognitive impairment (MCI). Currently, these disorders are diagnosed using a manual analysis of neuropsychological examinations. We measure the feasibility of using the linguistic characteristics of verbal utterances elicited during neuropsychological exams of elderly subjects to distinguish between elderly control groups, people with MCI, people diagnosed with possible Alzheimer's disease (AD), and probable AD. We investigated the performance of both theory-driven psycholinguistic features and data-driven contextual language embeddings in identifying different clinically diagnosed groups. Our experiments show that a combination of contextual and psycholinguistic features extracted by a Support Vector Machine improved distinguishing the verbal utterances of elderly controls, people with MCI, possible AD, and probable AD. This is the first work to identify four clinical diagnosis groups of dementia in a highly imbalanced dataset. Our work shows that machine learning algorithms built on contextual and psycholinguistic features can learn the linguistic biomarkers from verbal utterances and assist clinical diagnosis of different stages and types of dementia, even with limited data.
Topic-Centric Unsupervised Multi-Document Summarization of Scientific and News Articles
Nov 03, 2020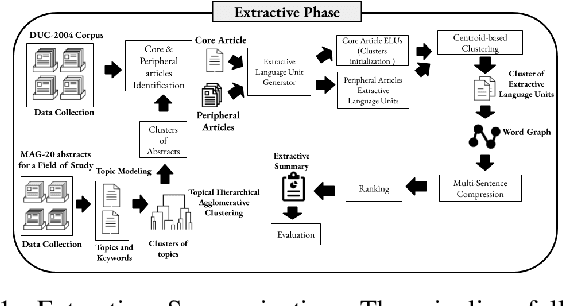

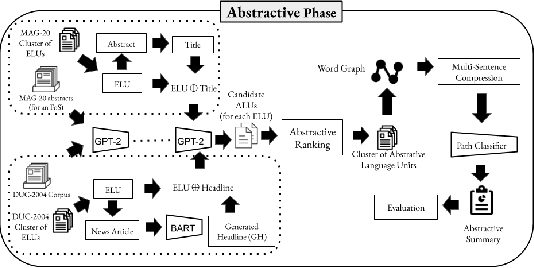
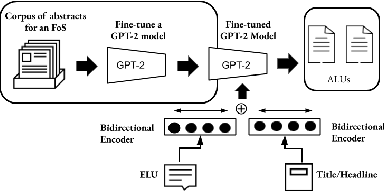
Recent advances in natural language processing have enabled automation of a wide range of tasks, including machine translation, named entity recognition, and sentiment analysis. Automated summarization of documents, or groups of documents, however, has remained elusive, with many efforts limited to extraction of keywords, key phrases, or key sentences. Accurate abstractive summarization has yet to be achieved due to the inherent difficulty of the problem, and limited availability of training data. In this paper, we propose a topic-centric unsupervised multi-document summarization framework to generate extractive and abstractive summaries for groups of scientific articles across 20 Fields of Study (FoS) in Microsoft Academic Graph (MAG) and news articles from DUC-2004 Task 2. The proposed algorithm generates an abstractive summary by developing salient language unit selection and text generation techniques. Our approach matches the state-of-the-art when evaluated on automated extractive evaluation metrics and performs better for abstractive summarization on five human evaluation metrics (entailment, coherence, conciseness, readability, and grammar). We achieve a kappa score of 0.68 between two co-author linguists who evaluated our results. We plan to publicly share MAG-20, a human-validated gold standard dataset of topic-clustered research articles and their summaries to promote research in abstractive summarization.
Leveraging Natural Language Processing to Mine Issues on Twitter During the COVID-19 Pandemic
Nov 03, 2020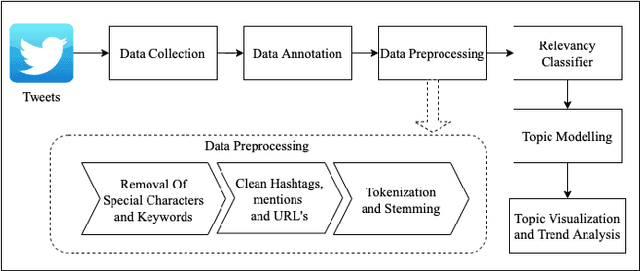
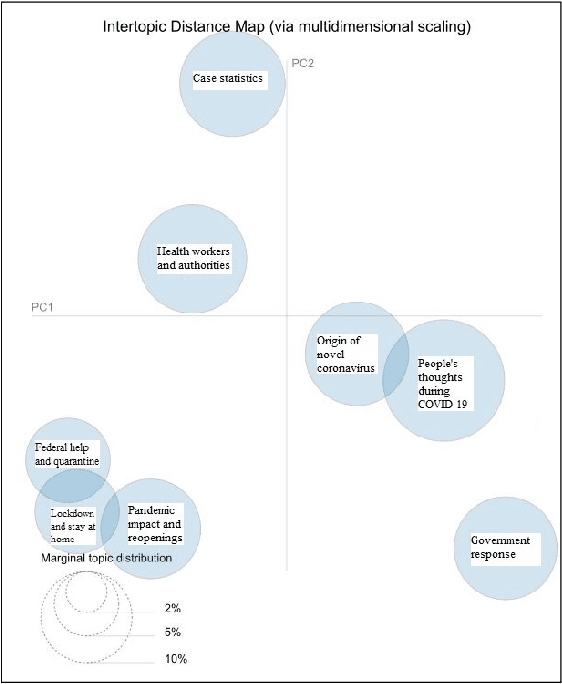
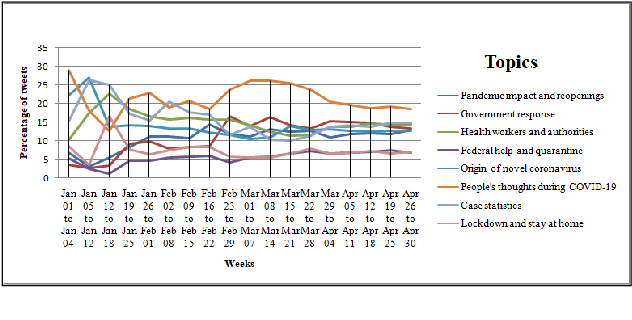
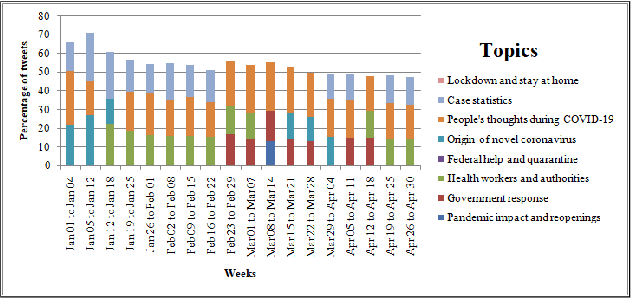
The recent global outbreak of the coronavirus disease (COVID-19) has spread to all corners of the globe. The international travel ban, panic buying, and the need for self-quarantine are among the many other social challenges brought about in this new era. Twitter platforms have been used in various public health studies to identify public opinion about an event at the local and global scale. To understand the public concerns and responses to the pandemic, a system that can leverage machine learning techniques to filter out irrelevant tweets and identify the important topics of discussion on social media platforms like Twitter is needed. In this study, we constructed a system to identify the relevant tweets related to the COVID-19 pandemic throughout January 1st, 2020 to April 30th, 2020, and explored topic modeling to identify the most discussed topics and themes during this period in our data set. Additionally, we analyzed the temporal changes in the topics with respect to the events that occurred during this pandemic. We found out that eight topics were sufficient to identify the themes in our corpus. These topics depicted a temporal trend. The dominant topics vary over time and align with the events related to the COVID-19 pandemic.
Measuring Pain in Sickle Cell Disease using Clinical Text
Aug 05, 2020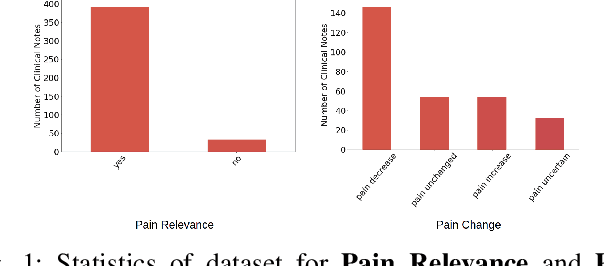
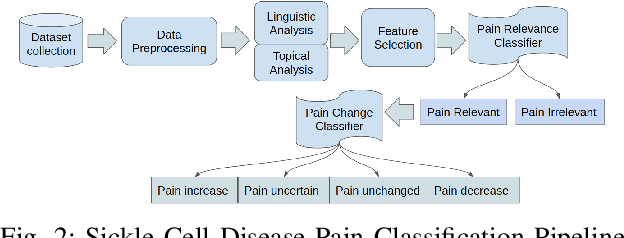
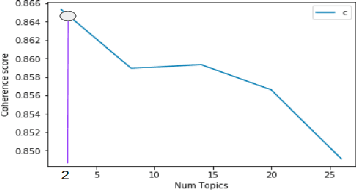
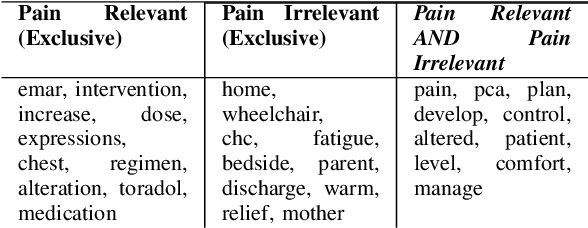
Sickle Cell Disease (SCD) is a hereditary disorder of red blood cells in humans. Complications such as pain, stroke, and organ failure occur in SCD as malformed, sickled red blood cells passing through small blood vessels get trapped. Particularly, acute pain is known to be the primary symptom of SCD. The insidious and subjective nature of SCD pain leads to challenges in pain assessment among Medical Practitioners (MPs). Thus, accurate identification of markers of pain in patients with SCD is crucial for pain management. Classifying clinical notes of patients with SCD based on their pain level enables MPs to give appropriate treatment. We propose a binary classification model to predict pain relevance of clinical notes and a multiclass classification model to predict pain level. While our four binary machine learning (ML) classifiers are comparable in their performance, Decision Trees had the best performance for the multiclass classification task achieving 0.70 in F-measure. Our results show the potential clinical text analysis and machine learning offer to pain management in sickle cell patients.
Toward Sensor-based Sleep Monitoring with Electrodermal Activity Measures
Jan 31, 2019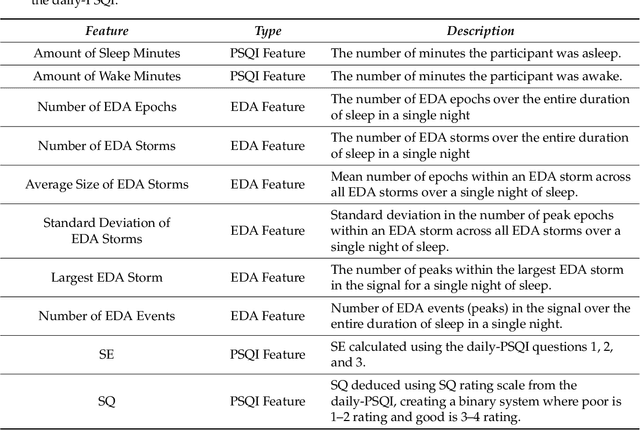
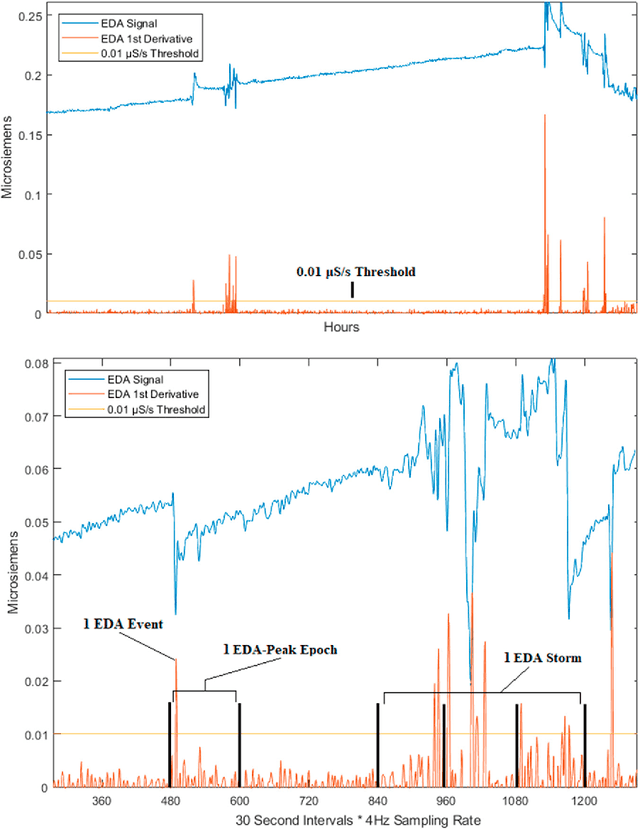
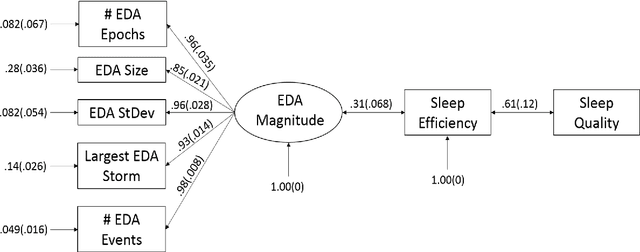
We use self-report and electrodermal activity (EDA) wearable sensor data from 77 nights of sleep on six participants to test the efficacy of EDA data for sleep monitoring. We used factor analysis to find latent factors in the EDA data, and causal model search to find the most probable graphical model accounting for self-reported sleep efficiency (SE), sleep quality (SQ), and the latent EDA factors. Structural equation modeling was used to confirm fit of the extracted graph. Based on the generated graph, logistic regression and naive Bayes models were used to test the efficacy of the EDA data in predicting SE and SQ. Six EDA features extracted from the total signal over a night's sleep could be explained by two latent factors, EDA Magnitude and EDA Storms. EDA Magnitude performed as a strong predictor for SE to aid detection of substantial changes in time asleep. The performance of EDA Magnitured and SE in classifying SQ showed promise for wearable sleep monitoring applications. However, our data suggest that obtaining a more accurate sensor-based measure of SE will be necessary before smaller changes in SQ can be detected from EDA sensor data alone.
Early Hospital Mortality Prediction using Vital Signals
Mar 18, 2018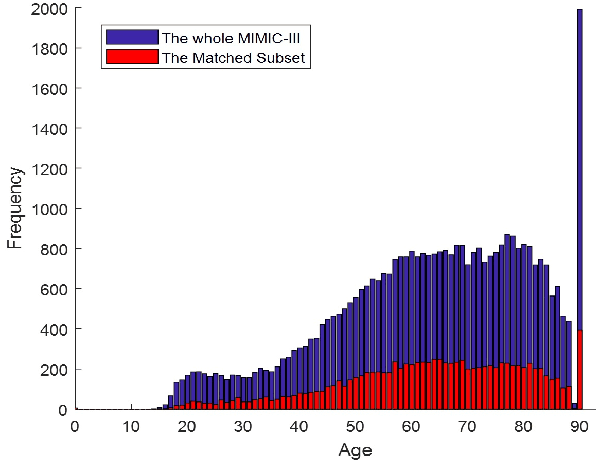
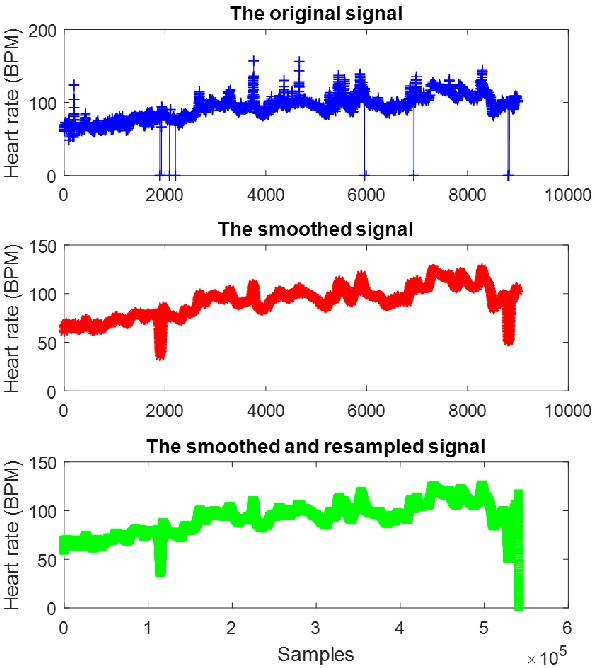
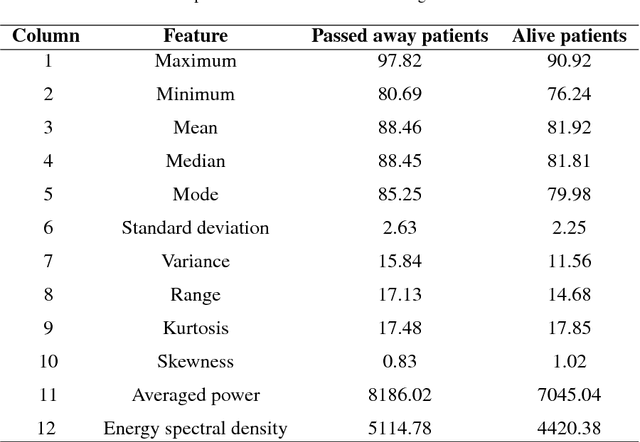
Early hospital mortality prediction is critical as intensivists strive to make efficient medical decisions about the severely ill patients staying in intensive care units. As a result, various methods have been developed to address this problem based on clinical records. However, some of the laboratory test results are time-consuming and need to be processed. In this paper, we propose a novel method to predict mortality using features extracted from the heart signals of patients within the first hour of ICU admission. In order to predict the risk, quantitative features have been computed based on the heart rate signals of ICU patients. Each signal is described in terms of 12 statistical and signal-based features. The extracted features are fed into eight classifiers: decision tree, linear discriminant, logistic regression, support vector machine (SVM), random forest, boosted trees, Gaussian SVM, and K-nearest neighborhood (K-NN). To derive insight into the performance of the proposed method, several experiments have been conducted using the well-known clinical dataset named Medical Information Mart for Intensive Care III (MIMIC-III). The experimental results demonstrate the capability of the proposed method in terms of precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC). The decision tree classifier satisfies both accuracy and interpretability better than the other classifiers, producing an F1-score and AUC equal to 0.91 and 0.93, respectively. It indicates that heart rate signals can be used for predicting mortality in patients in the ICU, achieving a comparable performance with existing predictions that rely on high dimensional features from clinical records which need to be processed and may contain missing information.
Semi-Supervised Approach to Monitoring Clinical Depressive Symptoms in Social Media
Oct 16, 2017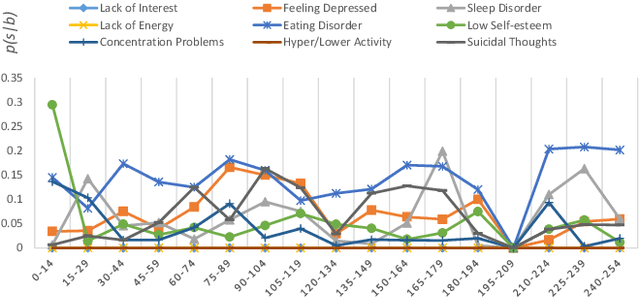
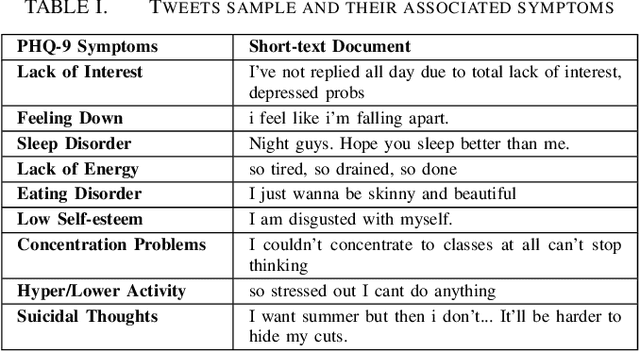
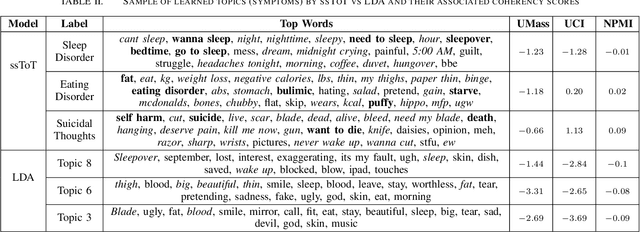
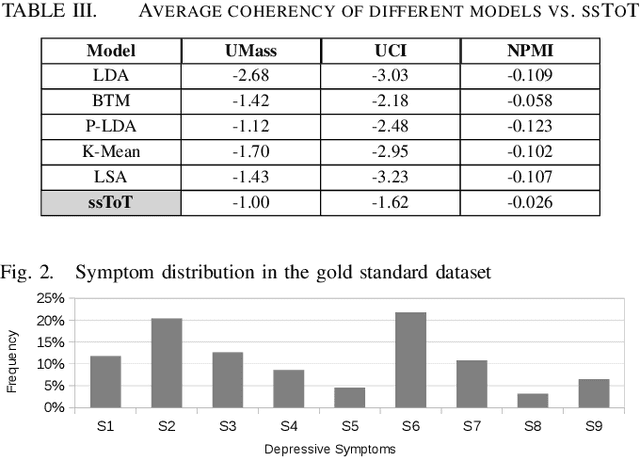
With the rise of social media, millions of people are routinely expressing their moods, feelings, and daily struggles with mental health issues on social media platforms like Twitter. Unlike traditional observational cohort studies conducted through questionnaires and self-reported surveys, we explore the reliable detection of clinical depression from tweets obtained unobtrusively. Based on the analysis of tweets crawled from users with self-reported depressive symptoms in their Twitter profiles, we demonstrate the potential for detecting clinical depression symptoms which emulate the PHQ-9 questionnaire clinicians use today. Our study uses a semi-supervised statistical model to evaluate how the duration of these symptoms and their expression on Twitter (in terms of word usage patterns and topical preferences) align with the medical findings reported via the PHQ-9. Our proactive and automatic screening tool is able to identify clinical depressive symptoms with an accuracy of 68% and precision of 72%.