 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA $\texttt{SUPER}^{\ast}$ Algorithm to Optimize Paper Bidding in Peer Review
Jun 27, 2020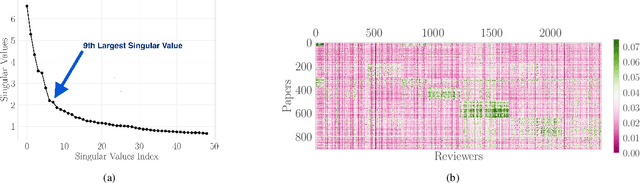
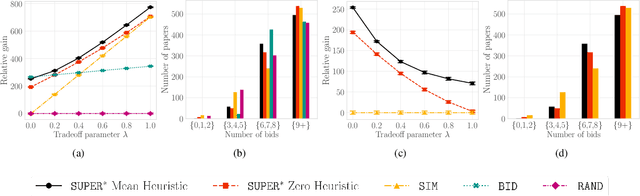
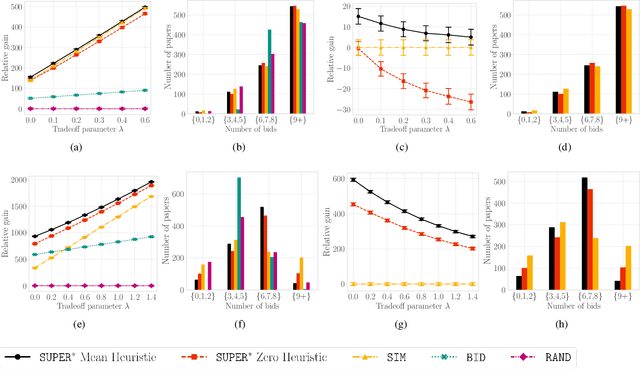
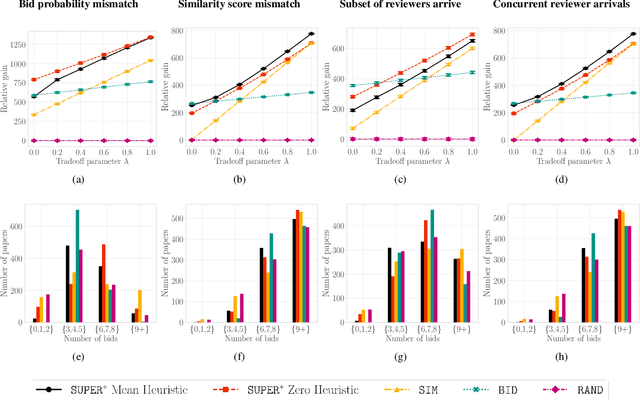
A number of applications involve sequential arrival of users, and require showing each user an ordering of items. A prime example (which forms the focus of this paper) is the bidding process in conference peer review where reviewers enter the system sequentially, each reviewer needs to be shown the list of submitted papers, and the reviewer then "bids" to review some papers. The order of the papers shown has a significant impact on the bids due to primacy effects. In deciding on the ordering of papers to show, there are two competing goals: (i) obtaining sufficiently many bids for each paper, and (ii) satisfying reviewers by showing them relevant items. In this paper, we begin by developing a framework to study this problem in a principled manner. We present an algorithm called $\texttt{SUPER}^{\ast}$, inspired by the A$^{\ast}$ algorithm, for this goal. Theoretically, we show a local optimality guarantee of our algorithm and prove that popular baselines are considerably suboptimal. Moreover, under a community model for the similarities, we prove that $\texttt{SUPER}^{\ast}$ is near-optimal whereas the popular baselines are considerably suboptimal. In experiments on real data from ICLR 2018 and synthetic data, we find that $\texttt{SUPER}^{\ast}$ considerably outperforms baselines deployed in existing systems, consistently reducing the number of papers with fewer than requisite bids by 50-75% or more, and is also robust to various real world complexities.
Sequential Experimental Design for Transductive Linear Bandits
Jun 20, 2019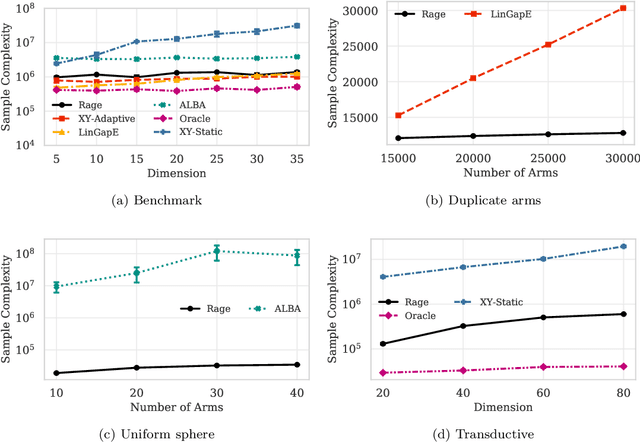
In this paper we introduce the transductive linear bandit problem: given a set of measurement vectors $\mathcal{X}\subset \mathbb{R}^d$, a set of items $\mathcal{Z}\subset \mathbb{R}^d$, a fixed confidence $\delta$, and an unknown vector $\theta^{\ast}\in \mathbb{R}^d$, the goal is to infer $\text{argmax}_{z\in \mathcal{Z}} z^\top\theta^\ast$ with probability $1-\delta$ by making as few sequentially chosen noisy measurements of the form $x^\top\theta^{\ast}$ as possible. When $\mathcal{X}=\mathcal{Z}$, this setting generalizes linear bandits, and when $\mathcal{X}$ is the standard basis vectors and $\mathcal{Z}\subset \{0,1\}^d$, combinatorial bandits. Such a transductive setting naturally arises when the set of measurement vectors is limited due to factors such as availability or cost. As an example, in drug discovery the compounds and dosages $\mathcal{X}$ a practitioner may be willing to evaluate in the lab in vitro due to cost or safety reasons may differ vastly from those compounds and dosages $\mathcal{Z}$ that can be safely administered to patients in vivo. Alternatively, in recommender systems for books, the set of books $\mathcal{X}$ a user is queried about may be restricted to well known best-sellers even though the goal might be to recommend more esoteric titles $\mathcal{Z}$. In this paper, we provide instance-dependent lower bounds for the transductive setting, an algorithm that matches these up to logarithmic factors, and an evaluation. In particular, we provide the first non-asymptotic algorithm for linear bandits that nearly achieves the information theoretic lower bound.
Convergence of Learning Dynamics in Stackelberg Games
Jun 04, 2019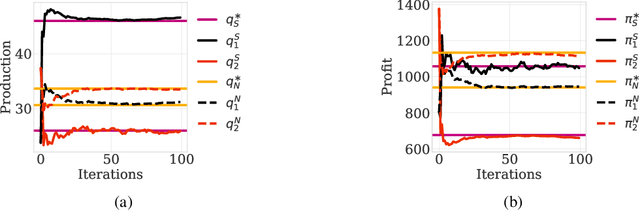
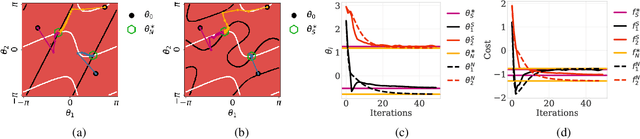
This paper investigates the convergence of learning dynamics in Stackelberg games. In the class of games we consider, there is a hierarchical game being played between a leader and a follower with continuous action spaces. We show that in zero-sum games, the only stable attractors of the Stackelberg gradient dynamics are Stackelberg equilibria. This insight allows us to develop a gradient-based update for the leader that converges to Stackelberg equilibria in zero-sum games and the set of stable attractors in general-sum games. We then consider a follower employing a gradient-play update rule instead of a best response strategy and propose a two-timescale algorithm with similar asymptotic convergence results. For this algorithm, we also provide finite-time high probability bounds for local convergence to a neighborhood of a stable Stackelberg equilibrium in general-sum games.
Combinatorial Bandits for Incentivizing Agents with Dynamic Preferences
Jul 06, 2018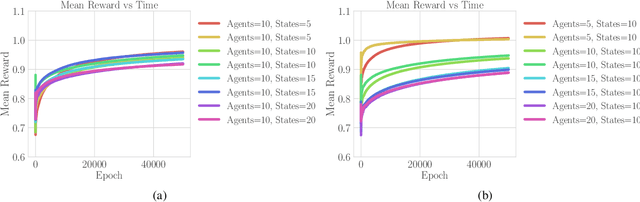
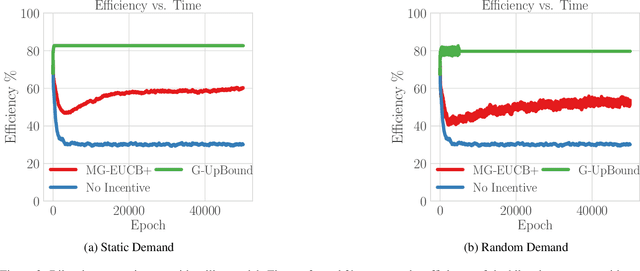
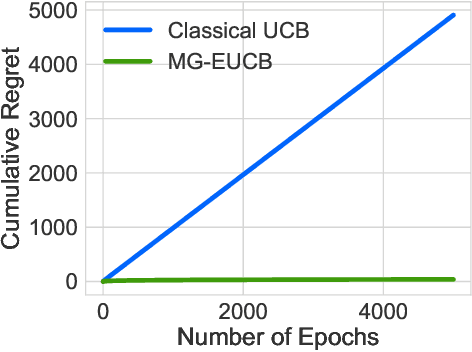
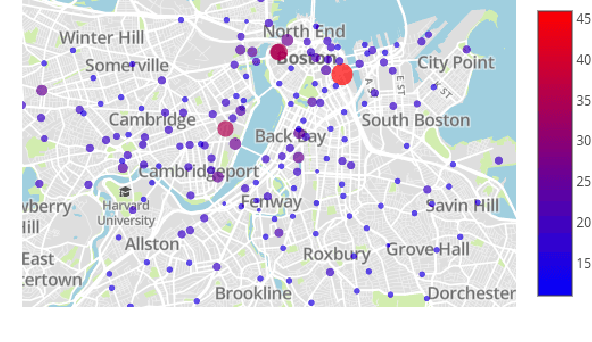
The design of personalized incentives or recommendations to improve user engagement is gaining prominence as digital platform providers continually emerge. We propose a multi-armed bandit framework for matching incentives to users, whose preferences are unknown a priori and evolving dynamically in time, in a resource constrained environment. We design an algorithm that combines ideas from three distinct domains: (i) a greedy matching paradigm, (ii) the upper confidence bound algorithm (UCB) for bandits, and (iii) mixing times from the theory of Markov chains. For this algorithm, we provide theoretical bounds on the regret and demonstrate its performance via both synthetic and realistic (matching supply and demand in a bike-sharing platform) examples.
Incentives in the Dark: Multi-armed Bandits for Evolving Users with Unknown Type
Mar 11, 2018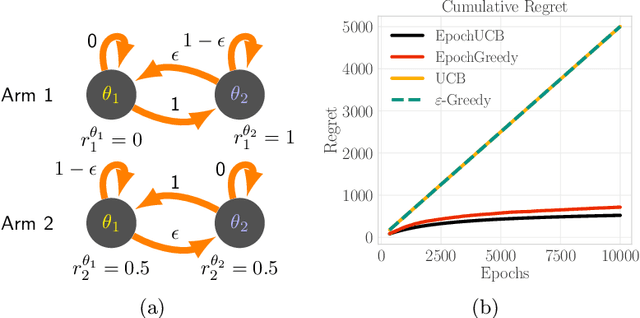
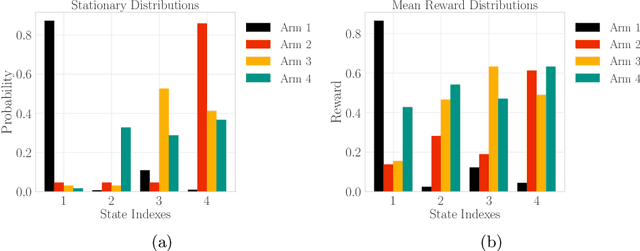
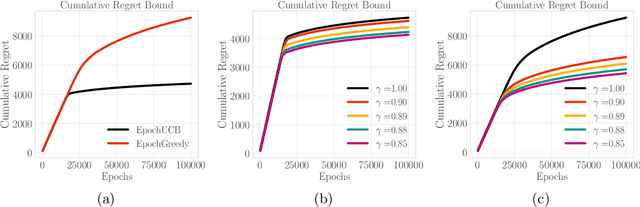
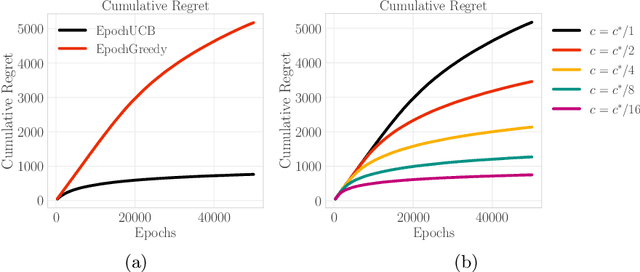
Design of incentives or recommendations to users is becoming more common as platform providers continually emerge. We propose a multi-armed bandit approach to the problem in which users types are unknown a priori and evolve dynamically in time. Unlike the traditional bandit setting, observed rewards are generated by a single Markov process. We demonstrate via an illustrative example that blindly applying the traditional bandit algorithms results in very poor performance as measured by regret. We introduce two variants of classical bandit algorithms, upper confidence bound (UCB) and epsilon-greedy, for which we provide theoretical bounds on the regret. We conduct a number of simulation-based experiments to show how the algorithms perform in comparison to traditional UCB and epsilon-greedy algorithms as well as reinforcement learning (Q-learning).