 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Gaussian Process Inference with Finite-data Mean and Variance Guarantees
Oct 04, 2018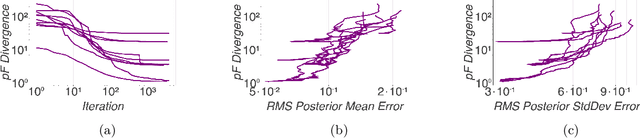

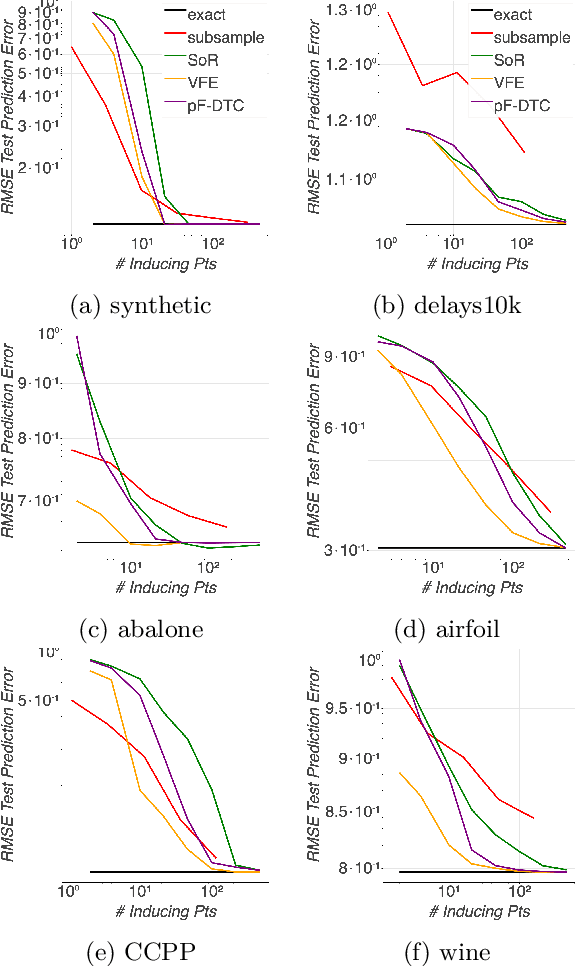
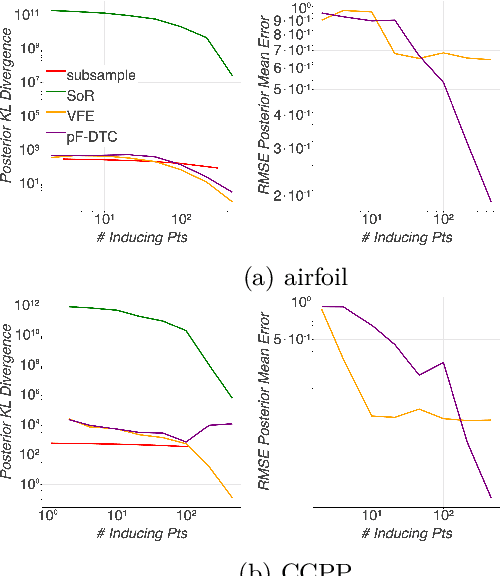
Gaussian processes (GPs) offer a flexible class of priors for nonparametric Bayesian regression, but popular GP posterior inference methods are typically prohibitively slow or lack desirable finite-data guarantees on quality. We develop an approach to scalable approximate GP regression with finite-data guarantees on the accuracy of pointwise posterior mean and variance estimates. Our main contribution is a novel objective for approximate inference in the nonparametric setting: the preconditioned Fisher (pF) divergence. We show that unlike the Kullback--Leibler divergence (used in variational inference), the pF divergence bounds the 2-Wasserstein distance, which in turn provides tight bounds the pointwise difference of the mean and variance functions. We demonstrate that, for sparse GP likelihood approximations, we can minimize the pF divergence efficiently. Our experiments show that optimizing the pF divergence has the same computational requirements as variational sparse GPs while providing comparable empirical performance--in addition to our novel finite-data quality guarantees.
Practical bounds on the error of Bayesian posterior approximations: A nonasymptotic approach
Oct 01, 2018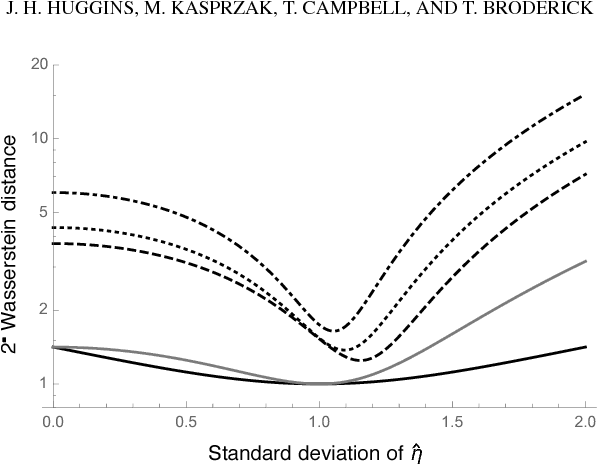
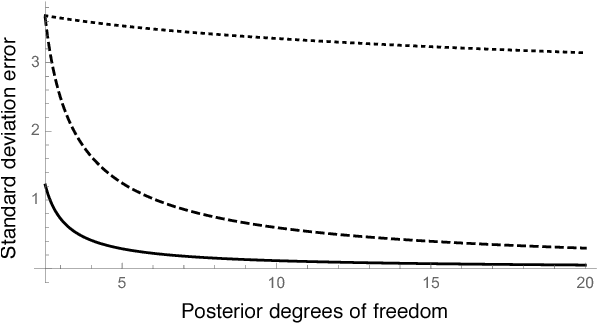
Bayesian inference typically requires the computation of an approximation to the posterior distribution. An important requirement for an approximate Bayesian inference algorithm is to output high-accuracy posterior mean and uncertainty estimates. Classical Monte Carlo methods, particularly Markov Chain Monte Carlo, remain the gold standard for approximate Bayesian inference because they have a robust finite-sample theory and reliable convergence diagnostics. However, alternative methods, which are more scalable or apply to problems where Markov Chain Monte Carlo cannot be used, lack the same finite-data approximation theory and tools for evaluating their accuracy. In this work, we develop a flexible new approach to bounding the error of mean and uncertainty estimates of scalable inference algorithms. Our strategy is to control the estimation errors in terms of Wasserstein distance, then bound the Wasserstein distance via a generalized notion of Fisher distance. Unlike computing the Wasserstein distance, which requires access to the normalized posterior distribution, the Fisher distance is tractable to compute because it requires access only to the gradient of the log posterior density. We demonstrate the usefulness of our Fisher distance approach by deriving bounds on the Wasserstein error of the Laplace approximation and Hilbert coresets. We anticipate that our approach will be applicable to many other approximate inference methods such as the integrated Laplace approximation, variational inference, and approximate Bayesian computation
Minimal I-MAP MCMC for Scalable Structure Discovery in Causal DAG Models
Jun 24, 2018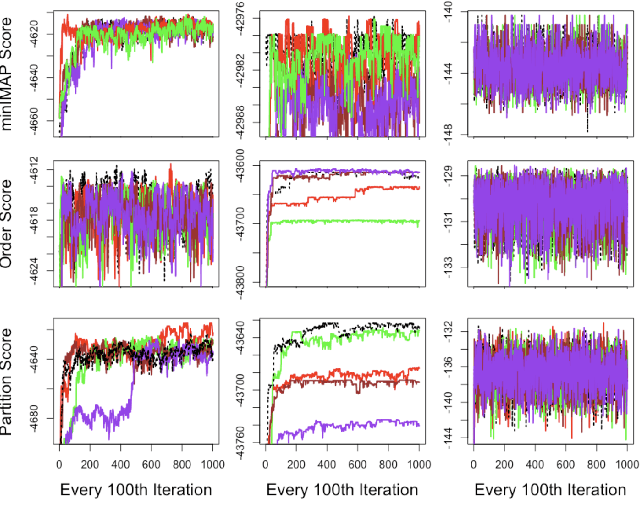
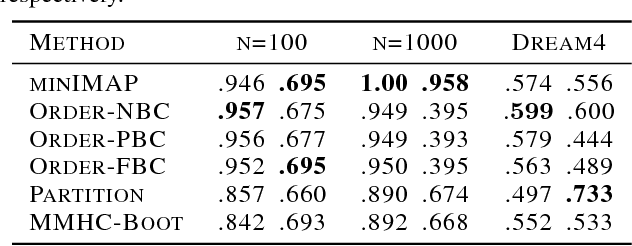
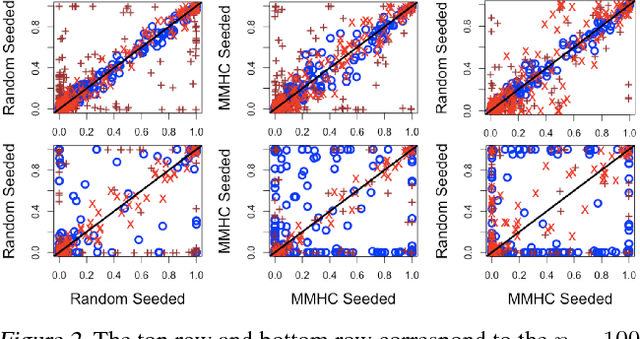

Learning a Bayesian network (BN) from data can be useful for decision-making or discovering causal relationships. However, traditional methods often fail in modern applications, which exhibit a larger number of observed variables than data points. The resulting uncertainty about the underlying network as well as the desire to incorporate prior information recommend a Bayesian approach to learning the BN, but the highly combinatorial structure of BNs poses a striking challenge for inference. The current state-of-the-art methods such as order MCMC are faster than previous methods but prevent the use of many natural structural priors and still have running time exponential in the maximum indegree of the true directed acyclic graph (DAG) of the BN. We here propose an alternative posterior approximation based on the observation that, if we incorporate empirical conditional independence tests, we can focus on a high-probability DAG associated with each order of the vertices. We show that our method allows the desired flexibility in prior specification, removes timing dependence on the maximum indegree and yields provably good posterior approximations; in addition, we show that it achieves superior accuracy, scalability, and sampler mixing on several datasets.
Bayesian Coreset Construction via Greedy Iterative Geodesic Ascent
May 28, 2018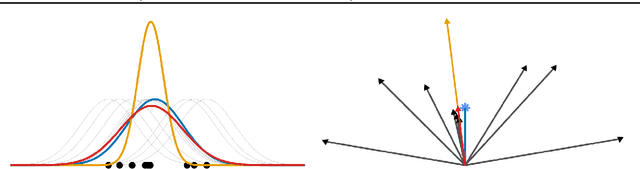
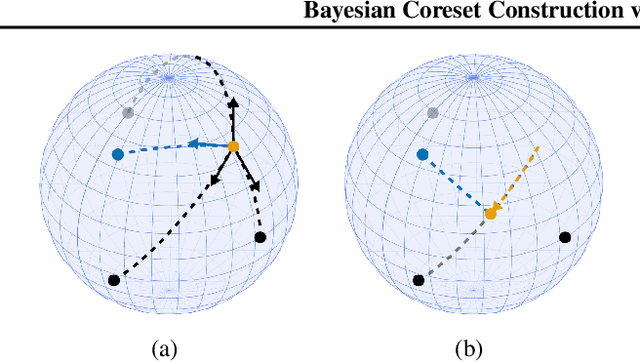
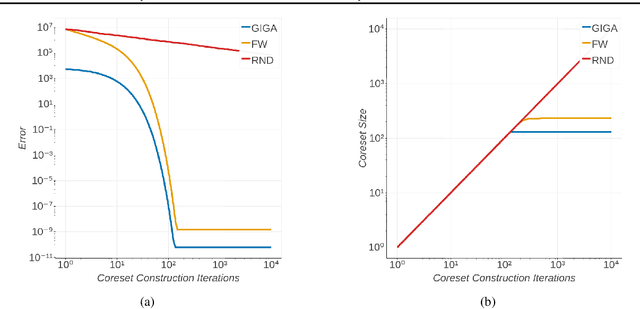
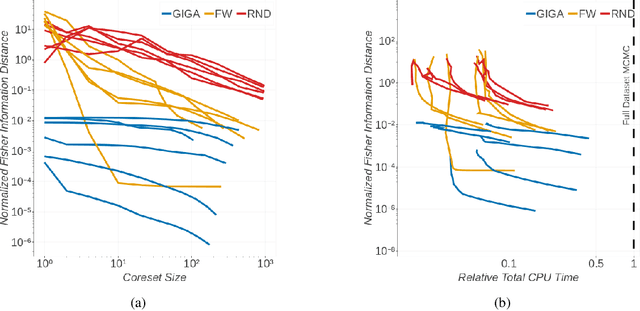
Coherent uncertainty quantification is a key strength of Bayesian methods. But modern algorithms for approximate Bayesian posterior inference often sacrifice accurate posterior uncertainty estimation in the pursuit of scalability. This work shows that previous Bayesian coreset construction algorithms---which build a small, weighted subset of the data that approximates the full dataset---are no exception. We demonstrate that these algorithms scale the coreset log-likelihood suboptimally, resulting in underestimated posterior uncertainty. To address this shortcoming, we develop greedy iterative geodesic ascent (GIGA), a novel algorithm for Bayesian coreset construction that scales the coreset log-likelihood optimally. GIGA provides geometric decay in posterior approximation error as a function of coreset size, and maintains the fast running time of its predecessors. The paper concludes with validation of GIGA on both synthetic and real datasets, demonstrating that it reduces posterior approximation error by orders of magnitude compared with previous coreset constructions.
PASS-GLM: polynomial approximate sufficient statistics for scalable Bayesian GLM inference
Nov 13, 2017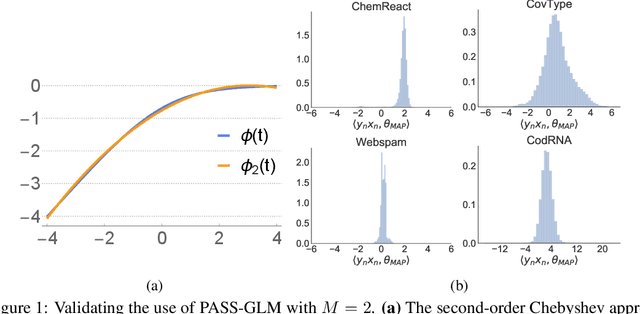
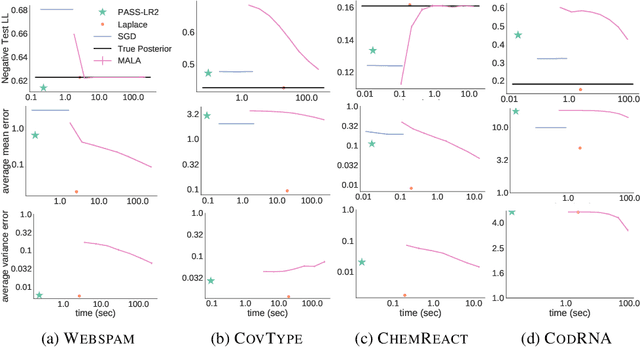
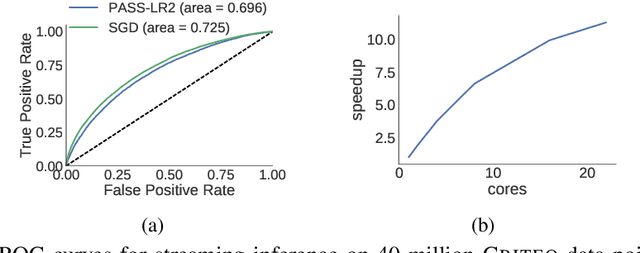
Generalized linear models (GLMs) -- such as logistic regression, Poisson regression, and robust regression -- provide interpretable models for diverse data types. Probabilistic approaches, particularly Bayesian ones, allow coherent estimates of uncertainty, incorporation of prior information, and sharing of power across experiments via hierarchical models. In practice, however, the approximate Bayesian methods necessary for inference have either failed to scale to large data sets or failed to provide theoretical guarantees on the quality of inference. We propose a new approach based on constructing polynomial approximate sufficient statistics for GLMs (PASS-GLM). We demonstrate that our method admits a simple algorithm as well as trivial streaming and distributed extensions that do not compound error across computations. We provide theoretical guarantees on the quality of point (MAP) estimates, the approximate posterior, and posterior mean and uncertainty estimates. We validate our approach empirically in the case of logistic regression using a quadratic approximation and show competitive performance with stochastic gradient descent, MCMC, and the Laplace approximation in terms of speed and multiple measures of accuracy -- including on an advertising data set with 40 million data points and 20,000 covariates.
Automated Scalable Bayesian Inference via Hilbert Coresets
Oct 13, 2017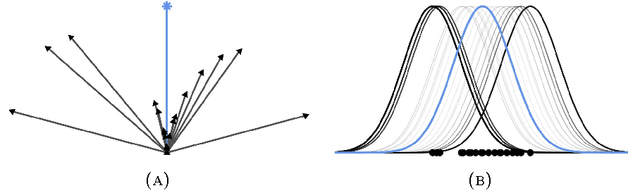
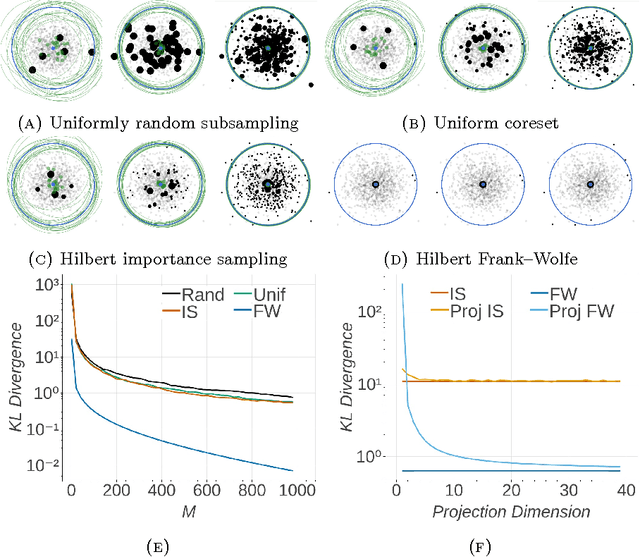
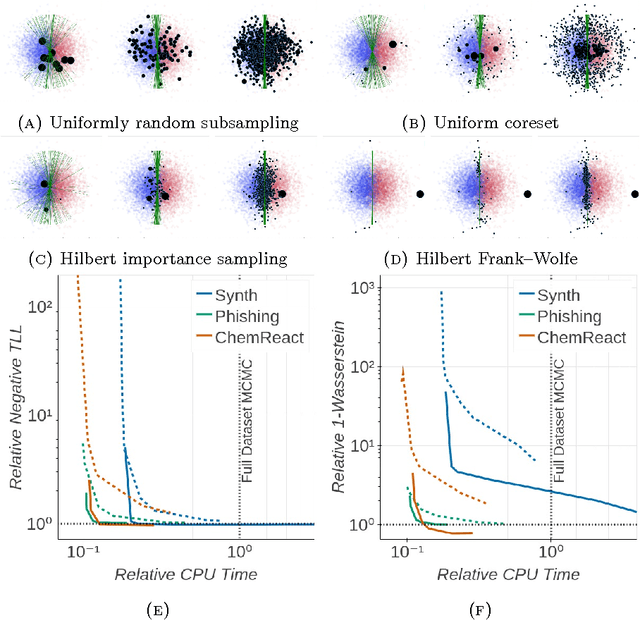
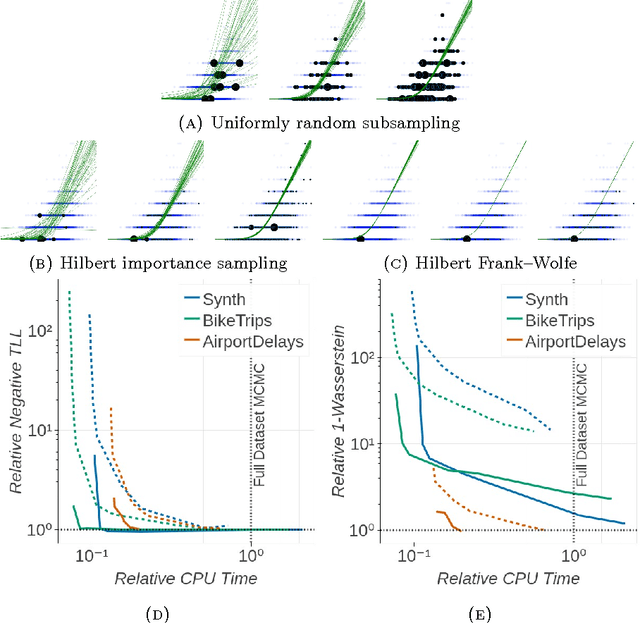
The automation of posterior inference in Bayesian data analysis has enabled experts and nonexperts alike to use more sophisticated models, engage in faster exploratory modeling and analysis, and ensure experimental reproducibility. However, standard automated posterior inference algorithms are not tractable at the scale of massive modern datasets, and modifications to make them so are typically model-specific, require expert tuning, and can break theoretical guarantees on inferential quality. Building on the Bayesian coresets framework, this work instead takes advantage of data redundancy to shrink the dataset itself as a preprocessing step, providing fully-automated, scalable Bayesian inference with theoretical guarantees. We begin with an intuitive reformulation of Bayesian coreset construction as sparse vector sum approximation, and demonstrate that its automation and performance-based shortcomings arise from the use of the supremum norm. To address these shortcomings we develop Hilbert coresets, i.e., Bayesian coresets constructed under a norm induced by an inner-product on the log-likelihood function space. We propose two Hilbert coreset construction algorithms---one based on importance sampling, and one based on the Frank-Wolfe algorithm---along with theoretical guarantees on approximation quality as a function of coreset size. Since the exact computation of the proposed inner-products is model-specific, we automate the construction with a random finite-dimensional projection of the log-likelihood functions. The resulting automated coreset construction algorithm is simple to implement, and experiments on a variety of models with real and synthetic datasets show that it provides high-quality posterior approximations and a significant reduction in the computational cost of inference.
Boosting Variational Inference
Mar 01, 2017



Variational inference (VI) provides fast approximations of a Bayesian posterior in part because it formulates posterior approximation as an optimization problem: to find the closest distribution to the exact posterior over some family of distributions. For practical reasons, the family of distributions in VI is usually constrained so that it does not include the exact posterior, even as a limit point. Thus, no matter how long VI is run, the resulting approximation will not approach the exact posterior. We propose to instead consider a more flexible approximating family consisting of all possible finite mixtures of a parametric base distribution (e.g., Gaussian). For efficient inference, we borrow ideas from gradient boosting to develop an algorithm we call boosting variational inference (BVI). BVI iteratively improves the current approximation by mixing it with a new component from the base distribution family and thereby yields progressively more accurate posterior approximations as more computing time is spent. Unlike a number of common VI variants including mean-field VI, BVI is able to capture multimodality, general posterior covariance, and nonstandard posterior shapes.
Coresets for Scalable Bayesian Logistic Regression
Feb 06, 2017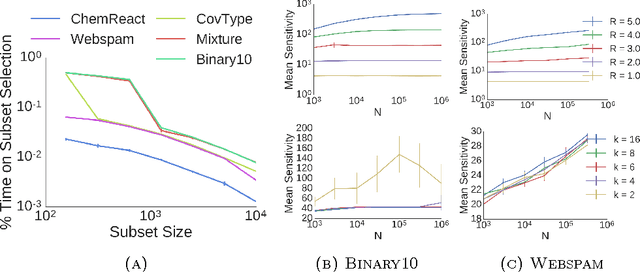
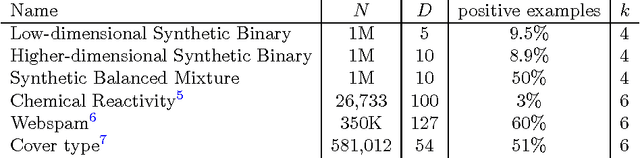
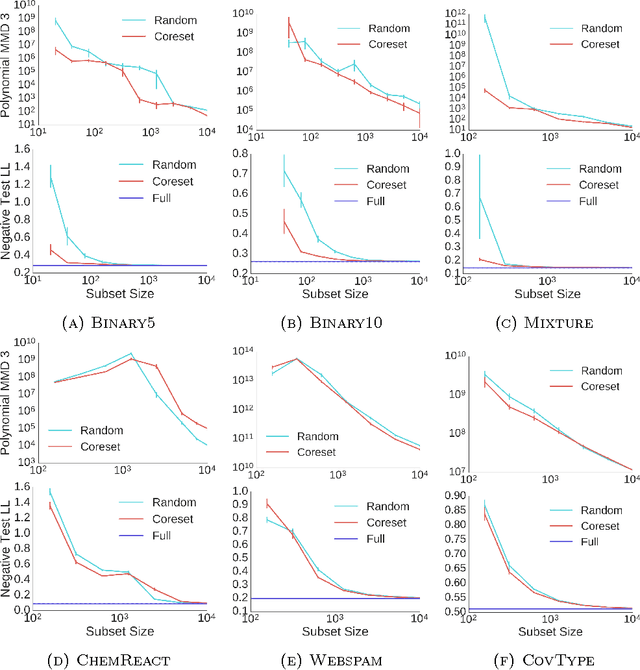
The use of Bayesian methods in large-scale data settings is attractive because of the rich hierarchical models, uncertainty quantification, and prior specification they provide. Standard Bayesian inference algorithms are computationally expensive, however, making their direct application to large datasets difficult or infeasible. Recent work on scaling Bayesian inference has focused on modifying the underlying algorithms to, for example, use only a random data subsample at each iteration. We leverage the insight that data is often redundant to instead obtain a weighted subset of the data (called a coreset) that is much smaller than the original dataset. We can then use this small coreset in any number of existing posterior inference algorithms without modification. In this paper, we develop an efficient coreset construction algorithm for Bayesian logistic regression models. We provide theoretical guarantees on the size and approximation quality of the coreset -- both for fixed, known datasets, and in expectation for a wide class of data generative models. Crucially, the proposed approach also permits efficient construction of the coreset in both streaming and parallel settings, with minimal additional effort. We demonstrate the efficacy of our approach on a number of synthetic and real-world datasets, and find that, in practice, the size of the coreset is independent of the original dataset size. Furthermore, constructing the coreset takes a negligible amount of time compared to that required to run MCMC on it.
Edge-exchangeable graphs and sparsity (NIPS 2016)
Feb 03, 2017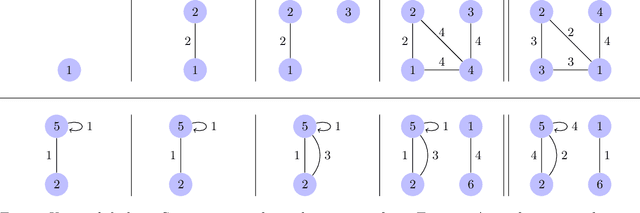
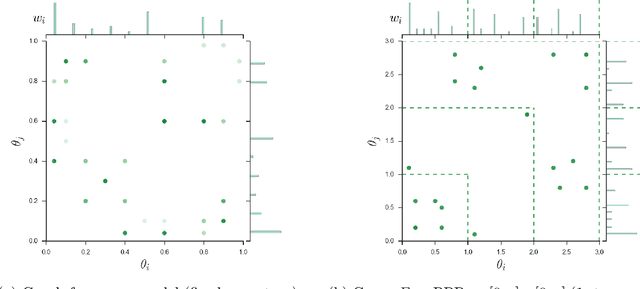
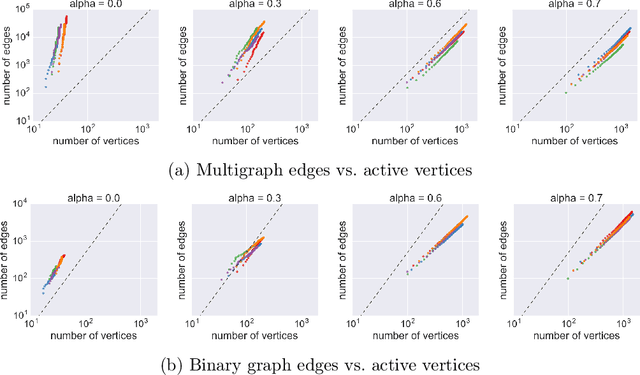
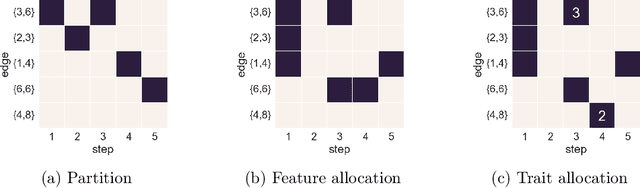
Many popular network models rely on the assumption of (vertex) exchangeability, in which the distribution of the graph is invariant to relabelings of the vertices. However, the Aldous-Hoover theorem guarantees that these graphs are dense or empty with probability one, whereas many real-world graphs are sparse. We present an alternative notion of exchangeability for random graphs, which we call edge exchangeability, in which the distribution of a graph sequence is invariant to the order of the edges. We demonstrate that edge-exchangeable models, unlike models that are traditionally vertex exchangeable, can exhibit sparsity. To do so, we outline a general framework for graph generative models; by contrast to the pioneering work of Caron and Fox (2015), models within our framework are stationary across steps of the graph sequence. In particular, our model grows the graph by instantiating more latent atoms of a single random measure as the dataset size increases, rather than adding new atoms to the measure.
Fast robustness quantification with variational Bayes
Jun 23, 2016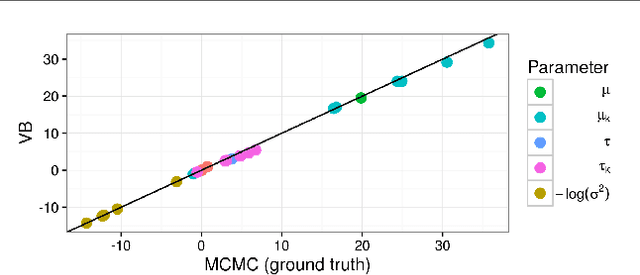
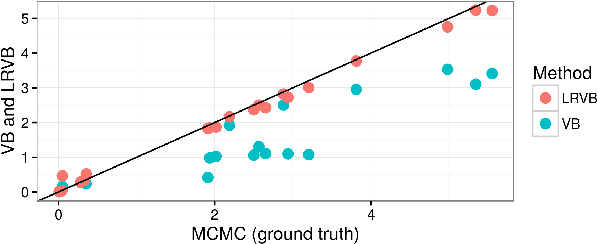
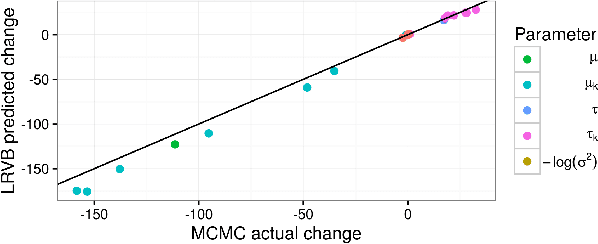
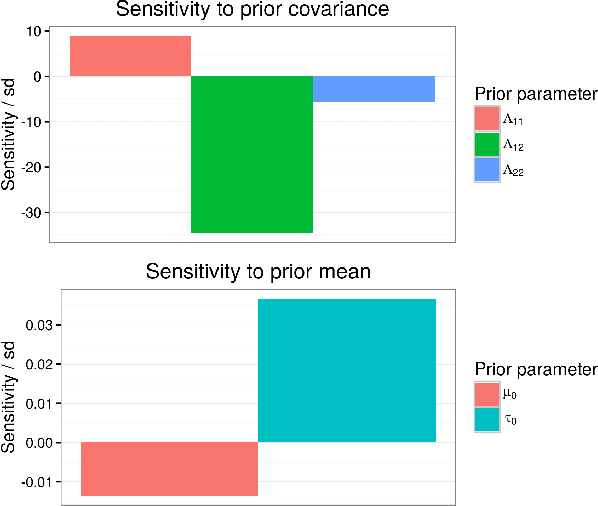
Bayesian hierarchical models are increasing popular in economics. When using hierarchical models, it is useful not only to calculate posterior expectations, but also to measure the robustness of these expectations to reasonable alternative prior choices. We use variational Bayes and linear response methods to provide fast, accurate posterior means and robustness measures with an application to measuring the effectiveness of microcredit in the developing world.