 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInner-Scene Similarities as a Contextual Cue for Object Detection
Jul 14, 2017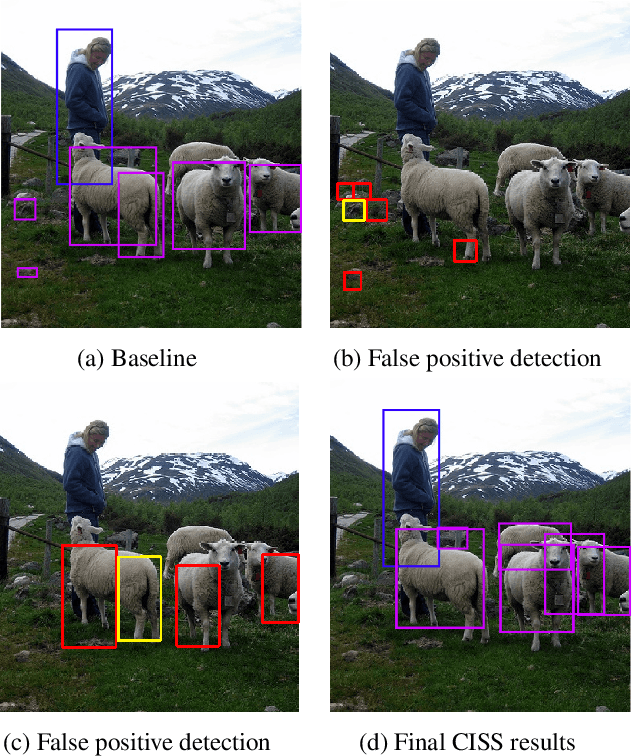



Using image context is an effective approach for improving object detection. Previously proposed methods used contextual cues that rely on semantic or spatial information. In this work, we explore a different kind of contextual information: inner-scene similarity. We present the CISS (Context by Inner Scene Similarity) algorithm, which is based on the observation that two visually similar sub-image patches are likely to share semantic identities, especially when both appear in the same image. CISS uses base-scores provided by a base detector and performs as a post-detection stage. For each candidate sub-image (denoted anchor), the CISS algorithm finds a few similar sub-images (denoted supporters), and, using them, calculates a new enhanced score for the anchor. This is done by utilizing the base-scores of the supporters and a pre-trained dependency model. The new scores are modeled as a linear function of the base scores of the anchor and the supporters and is estimated using a minimum mean square error optimization. This approach results in: (a) improved detection of partly occluded objects (when there are similar non-occluded objects in the scene), and (b) fewer false alarms (when the base detector mistakenly classifies a background patch as an object). This work relates to Duncan and Humphreys' "similarity theory," a psychophysical study. which suggested that the human visual system perceptually groups similar image regions and that the classification of one region is affected by the estimated identity of the other. Experimental results demonstrate the enhancement of a base detector's scores on the PASCAL VOC dataset.
Graph Based Over-Segmentation Methods for 3D Point Clouds
Feb 14, 2017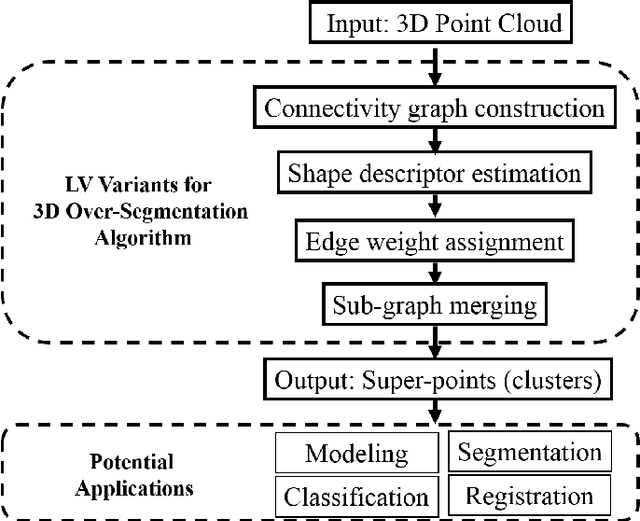
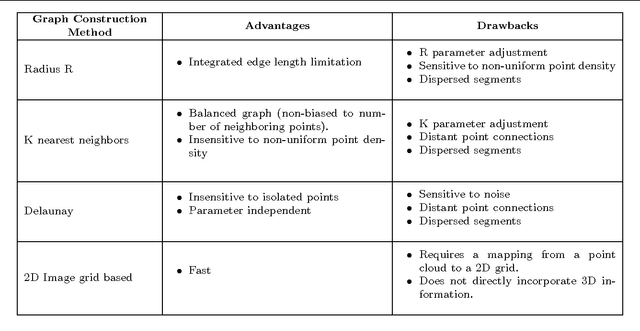

Over-segmentation, or super-pixel generation, is a common preliminary stage for many computer vision applications. New acquisition technologies enable the capturing of 3D point clouds that contain color and geometrical information. This 3D information introduces a new conceptual change that can be utilized to improve the results of over-segmentation, which uses mainly color information, and to generate clusters of points we call super-points. We consider a variety of possible 3D extensions of the Local Variation (LV) graph based over-segmentation algorithms, and compare them thoroughly. We consider different alternatives for constructing the connectivity graph, for assigning the edge weights, and for defining the merge criterion, which must now account for the geometric information and not only color. Following this evaluation, we derive a new generic algorithm for over-segmentation of 3D point clouds. We call this new algorithm Point Cloud Local Variation (PCLV). The advantages of the new over-segmentation algorithm are demonstrated on both outdoor and cluttered indoor scenes. Performance analysis of the proposed approach compared to state-of-the-art 2D and 3D over-segmentation algorithms shows significant improvement according to the common performance measures.
Depth Perception in Autostereograms: 1/f-Noise is Best
Jun 16, 2015


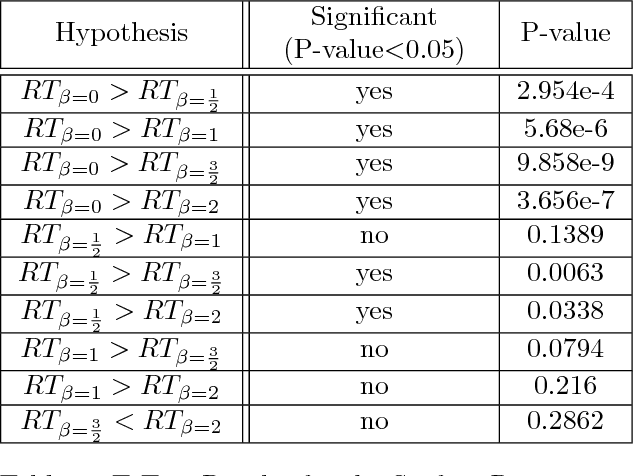
An autostereogram is a single image that encodes depth information that pops out when looking at it. The trick is achieved by replicating a vertical strip that sets a basic two-dimensional pattern with disparity shifts that encode a three-dimensional scene. It is of interest to explore the dependency between the ease of perceiving depth in autostereograms and the choice of the basic pattern used for generating them. In this work we confirm a theory proposed by Bruckstein et al. to explain the process of autostereographic depth perception, providing a measure for the ease of "locking into" the depth profile, based on the spectral properties of the basic pattern used. We report the results of three sets of psychophysical experiments using autostereograms generated from two-dimensional random noise patterns having power spectra of the form $1/f^\beta$. The experiments were designed to test the ability of human subjects to identify smooth, low resolution surfaces, as well as detail, in the form of higher resolution objects in the depth profile, and to determine limits in identifying small objects as a function of their size. In accordance with the theory, we discover a significant advantage of the $1/f$ noise pattern (pink noise) for fast depth lock-in and fine detail detection, showing that such patterns are optimal choices for autostereogram design. Validating the theoretical model predictions strengthens its underlying assumptions, and contributes to a better understanding of the visual system's binocular disparity mechanisms.