 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking (Global) Barriers in Parallel Stochastic Optimization with Wait-Avoiding Group Averaging
Apr 30, 2020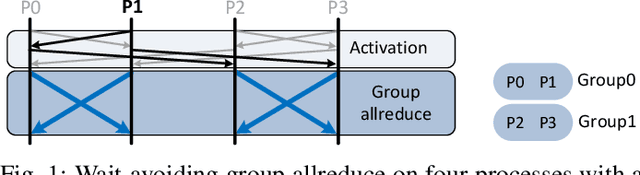
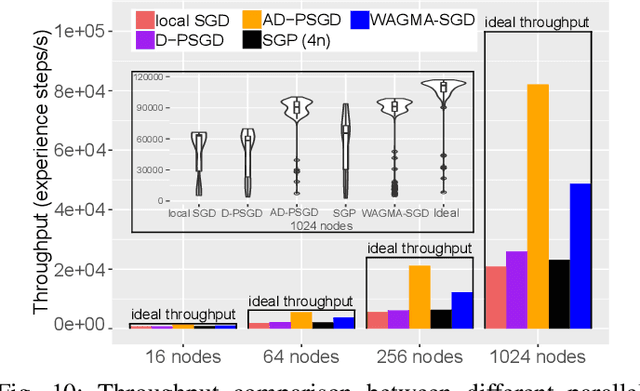
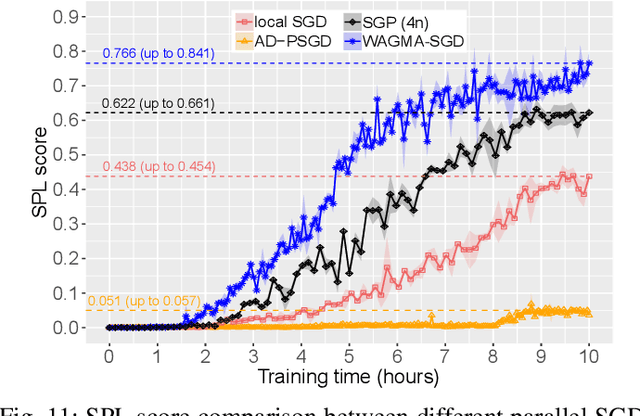
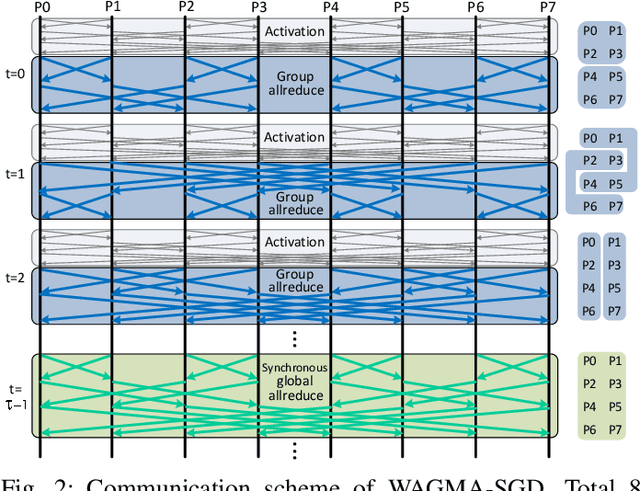
Deep learning at scale is dominated by communication time. Distributing samples across nodes usually yields the best performance, but poses scaling challenges due to global information dissemination and load imbalance across uneven sample lengths. State-of-the-art decentralized optimizers mitigate the problem, but require more iterations to achieve the same accuracy as their globally-communicating counterparts. We present Wait-Avoiding Group Model Averaging (WAGMA) SGD, a wait-avoiding stochastic optimizer that reduces global communication via subgroup weight exchange. The key insight is a combination of algorithmic changes to the averaging scheme and the use of a group allreduce operation. We prove the convergence of WAGMA-SGD, and empirically show that it retains convergence rates equivalent to Allreduce-SGD. For evaluation, we train ResNet-50 on ImageNet; Transformer for machine translation; and deep reinforcement learning for navigation at scale. Compared with state-of-the-art decentralized SGD, WAGMA-SGD significantly improves training throughput (by 2.1x on 1,024 GPUs) and achieves the fastest time-to-solution.
ProGraML: Graph-based Deep Learning for Program Optimization and Analysis
Mar 23, 2020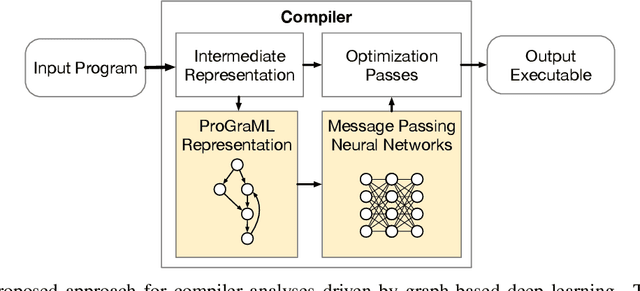
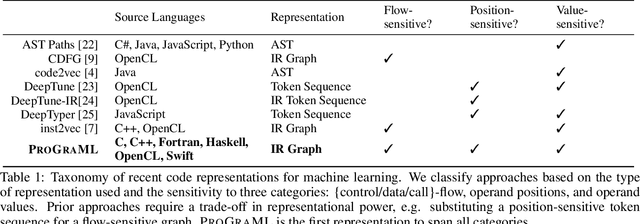

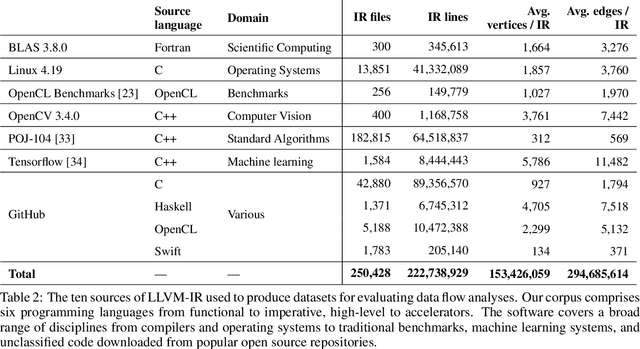
The increasing complexity of computing systems places a tremendous burden on optimizing compilers, requiring ever more accurate and aggressive optimizations. Machine learning offers significant benefits for constructing optimization heuristics but there remains a gap between what state-of-the-art methods achieve and the performance of an optimal heuristic. Closing this gap requires improvements in two key areas: a representation that accurately captures the semantics of programs, and a model architecture with sufficient expressiveness to reason about this representation. We introduce ProGraML - Program Graphs for Machine Learning - a novel graph-based program representation using a low level, language agnostic, and portable format; and machine learning models capable of performing complex downstream tasks over these graphs. The ProGraML representation is a directed attributed multigraph that captures control, data, and call relations, and summarizes instruction and operand types and ordering. Message Passing Neural Networks propagate information through this structured representation, enabling whole-program or per-vertex classification tasks. ProGraML provides a general-purpose program representation that equips learnable models to perform the types of program analysis that are fundamental to optimization. To this end, we evaluate the performance of our approach first on a suite of traditional compiler analysis tasks: control flow reachability, dominator trees, data dependencies, variable liveness, and common subexpression detection. On a benchmark dataset of 250k LLVM-IR files covering six source programming languages, ProGraML achieves an average 94.0 F1 score, significantly outperforming the state-of-the-art approaches. We then apply our approach to two high-level tasks - heterogeneous device mapping and program classification - setting new state-of-the-art performance in both.
Predicting Weather Uncertainty with Deep Convnets
Dec 04, 2019
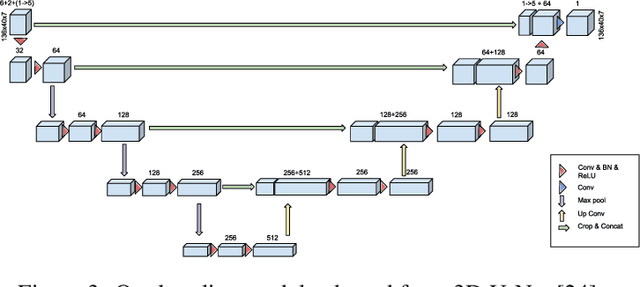
Modern weather forecast models perform uncertainty quantification using ensemble prediction systems, which collect nonparametric statistics based on multiple perturbed simulations. To provide accurate estimation, dozens of such computationally intensive simulations must be run. We show that deep neural networks can be used on a small set of numerical weather simulations to estimate the spread of a weather forecast, significantly reducing computational cost. To train the system, we both modify the 3D U-Net architecture and explore models that incorporate temporal data. Our models serve as a starting point to improve uncertainty quantification in current real-time weather forecasting systems, which is vital for predicting extreme events.
Taming Unbalanced Training Workloads in Deep Learning with Partial Collective Operations
Aug 13, 2019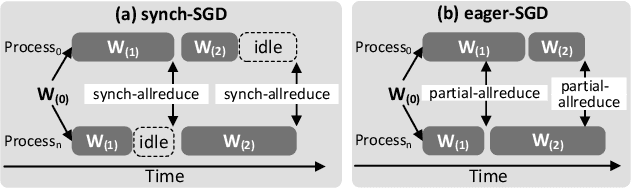

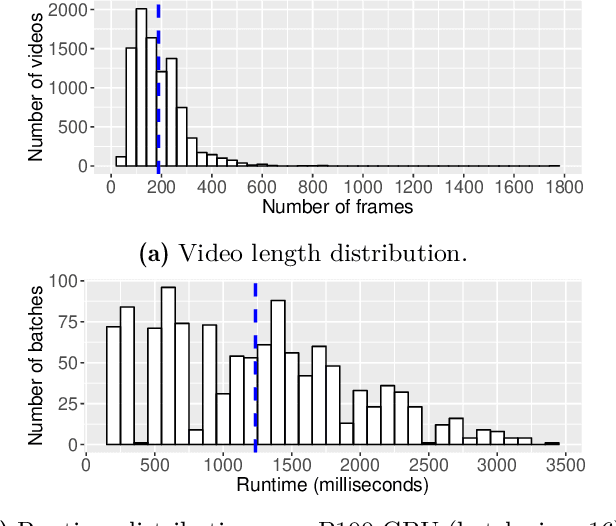
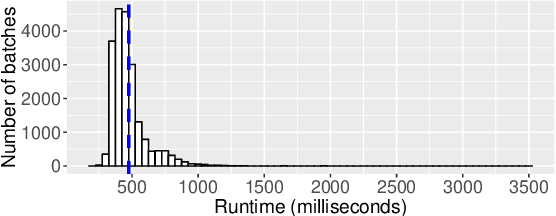
Load imbalance pervasively exists in distributed deep learning training systems, either caused by the inherent imbalance in learned tasks or by the system itself. Traditional synchronous Stochastic Gradient Descent (SGD) achieves good accuracy for a wide variety of tasks, but relies on global synchronization to accumulate the gradients at every training step. In this paper, we propose eager-SGD, which relaxes the global synchronization for decentralized accumulation. To implement eager-SGD, we propose to use two partial collectives: solo and majority. With solo allreduce, the faster processes contribute their gradients eagerly without waiting for the slower processes, whereas with majority allreduce, at least half of the participants must contribute gradients before continuing, all without using a central parameter server. We theoretically prove the convergence of the algorithms and describe the partial collectives in detail. Experimental results on load-imbalanced environments (CIFAR-10, ImageNet, and UCF101 datasets) show that eager-SGD achieves 1.27x speedup over the state-of-the-art synchronous SGD, without losing accuracy.
Mix & Match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency
Aug 12, 2019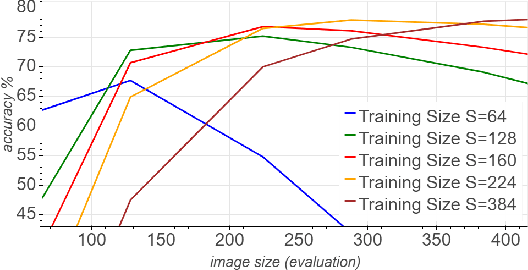
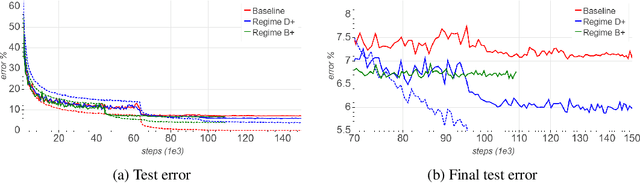
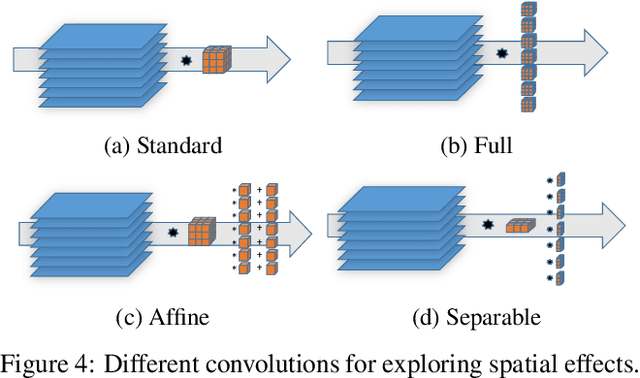
Convolutional neural networks (CNNs) are commonly trained using a fixed spatial image size predetermined for a given model. Although trained on images of aspecific size, it is well established that CNNs can be used to evaluate a wide range of image sizes at test time, by adjusting the size of intermediate feature maps. In this work, we describe and evaluate a novel mixed-size training regime that mixes several image sizes at training time. We demonstrate that models trained using our method are more resilient to image size changes and generalize well even on small images. This allows faster inference by using smaller images attest time. For instance, we receive a 76.43% top-1 accuracy using ResNet50 with an image size of 160, which matches the accuracy of the baseline model with 2x fewer computations. Furthermore, for a given image size used at test time, we show this method can be exploited either to accelerate training or the final test accuracy. For example, we are able to reach a 79.27% accuracy with a model evaluated at a 288 spatial size for a relative improvement of 14% over the baseline.
A Modular Benchmarking Infrastructure for High-Performance and Reproducible Deep Learning
Jan 29, 2019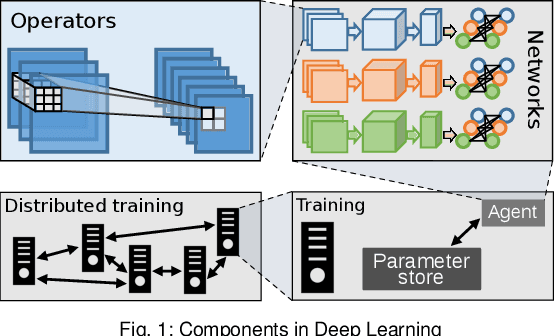
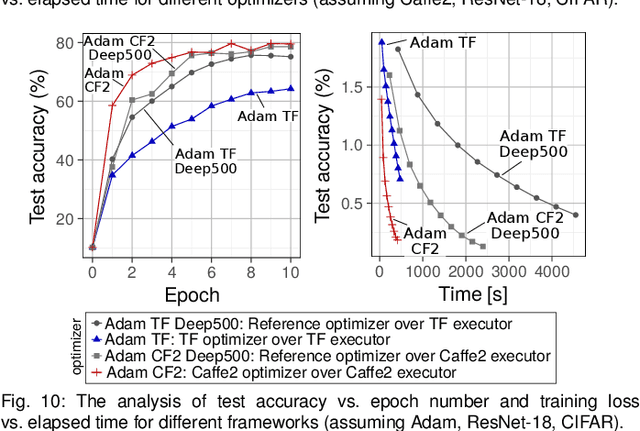
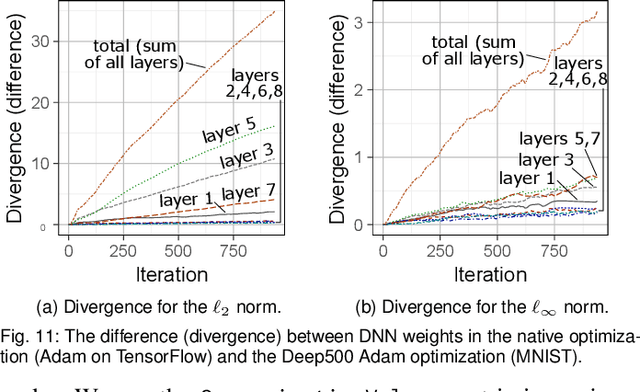
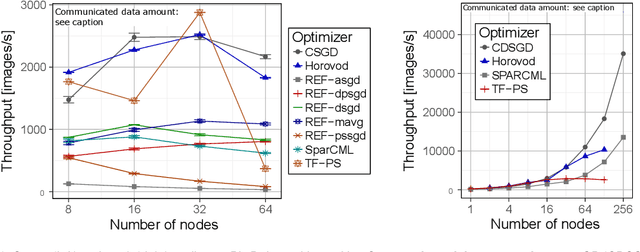
We introduce Deep500: the first customizable benchmarking infrastructure that enables fair comparison of the plethora of deep learning frameworks, algorithms, libraries, and techniques. The key idea behind Deep500 is its modular design, where deep learning is factorized into four distinct levels: operators, network processing, training, and distributed training. Our evaluation illustrates that Deep500 is customizable (enables combining and benchmarking different deep learning codes) and fair (uses carefully selected metrics). Moreover, Deep500 is fast (incurs negligible overheads), verifiable (offers infrastructure to analyze correctness), and reproducible. Finally, as the first distributed and reproducible benchmarking system for deep learning, Deep500 provides software infrastructure to utilize the most powerful supercomputers for extreme-scale workloads.
Augment your batch: better training with larger batches
Jan 27, 2019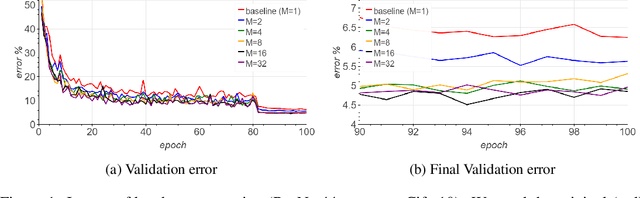
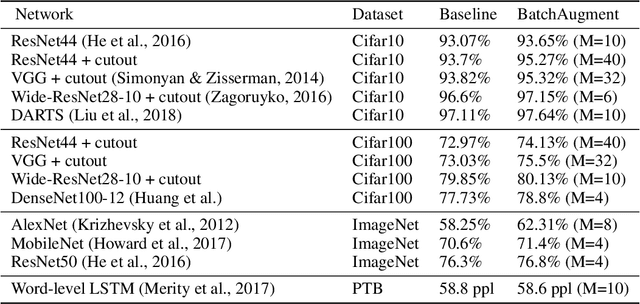
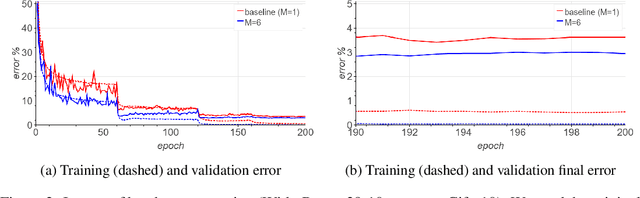

Large-batch SGD is important for scaling training of deep neural networks. However, without fine-tuning hyperparameter schedules, the generalization of the model may be hampered. We propose to use batch augmentation: replicating instances of samples within the same batch with different data augmentations. Batch augmentation acts as a regularizer and an accelerator, increasing both generalization and performance scaling. We analyze the effect of batch augmentation on gradient variance and show that it empirically improves convergence for a wide variety of deep neural networks and datasets. Our results show that batch augmentation reduces the number of necessary SGD updates to achieve the same accuracy as the state-of-the-art. Overall, this simple yet effective method enables faster training and better generalization by allowing more computational resources to be used concurrently.
Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis
Sep 15, 2018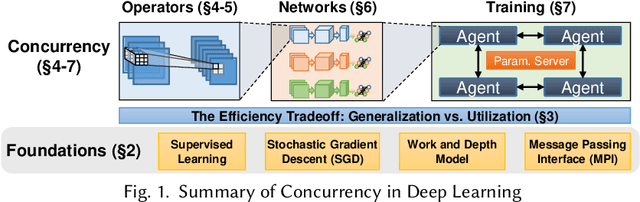


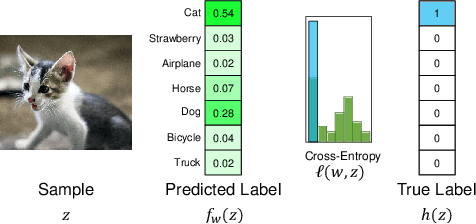
Deep Neural Networks (DNNs) are becoming an important tool in modern computing applications. Accelerating their training is a major challenge and techniques range from distributed algorithms to low-level circuit design. In this survey, we describe the problem from a theoretical perspective, followed by approaches for its parallelization. We present trends in DNN architectures and the resulting implications on parallelization strategies. We then review and model the different types of concurrency in DNNs: from the single operator, through parallelism in network inference and training, to distributed deep learning. We discuss asynchronous stochastic optimization, distributed system architectures, communication schemes, and neural architecture search. Based on those approaches, we extrapolate potential directions for parallelism in deep learning.
Neural Code Comprehension: A Learnable Representation of Code Semantics
Jul 31, 2018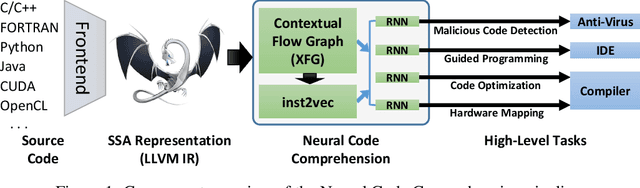
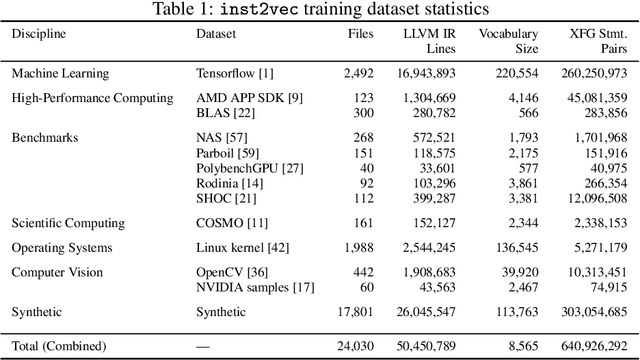
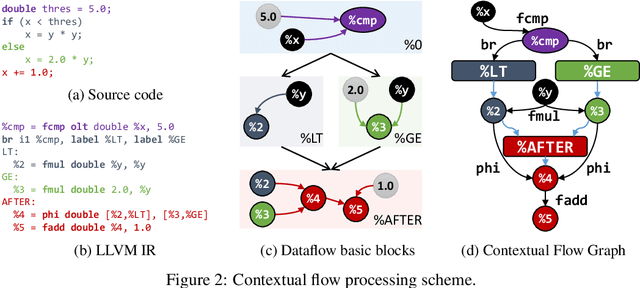
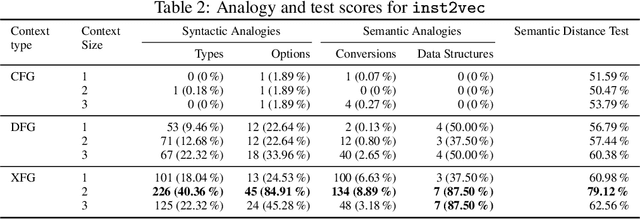
With the recent success of embeddings in natural language processing, research has been conducted into applying similar methods to code analysis. Most works attempt to process the code directly or use a syntactic tree representation, treating it like sentences written in a natural language. However, none of the existing methods are sufficient to comprehend program semantics robustly, due to structural features such as function calls, branching, and interchangeable order of statements. In this paper, we propose a novel processing technique to learn code semantics, and apply it to a variety of program analysis tasks. In particular, we stipulate that a robust distributional hypothesis of code applies to both human- and machine-generated programs. Following this hypothesis, we define an embedding space, inst2vec, based on an Intermediate Representation (IR) of the code that is independent of the source programming language. We provide a novel definition of contextual flow for this IR, leveraging both the underlying data- and control-flow of the program. We then analyze the embeddings qualitatively using analogies and clustering, and evaluate the learned representation on three different high-level tasks. We show that with a single RNN architecture and pre-trained fixed embeddings, inst2vec outperforms specialized approaches for performance prediction (compute device mapping, optimal thread coarsening); and algorithm classification from raw code (104 classes), where we set a new state-of-the-art.
μ-cuDNN: Accelerating Deep Learning Frameworks with Micro-Batching
Apr 13, 2018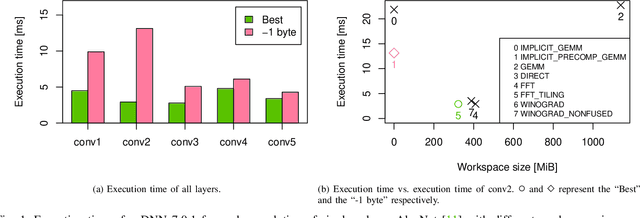
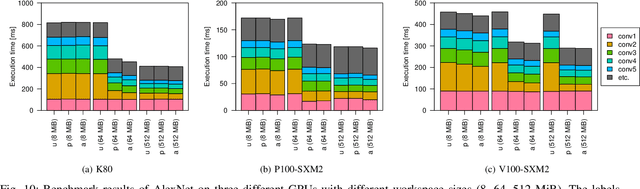
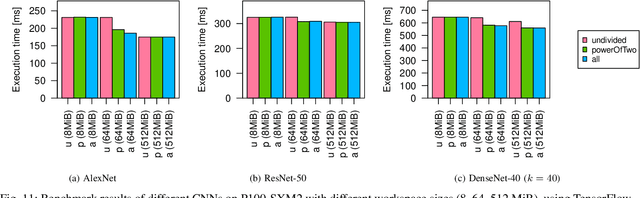
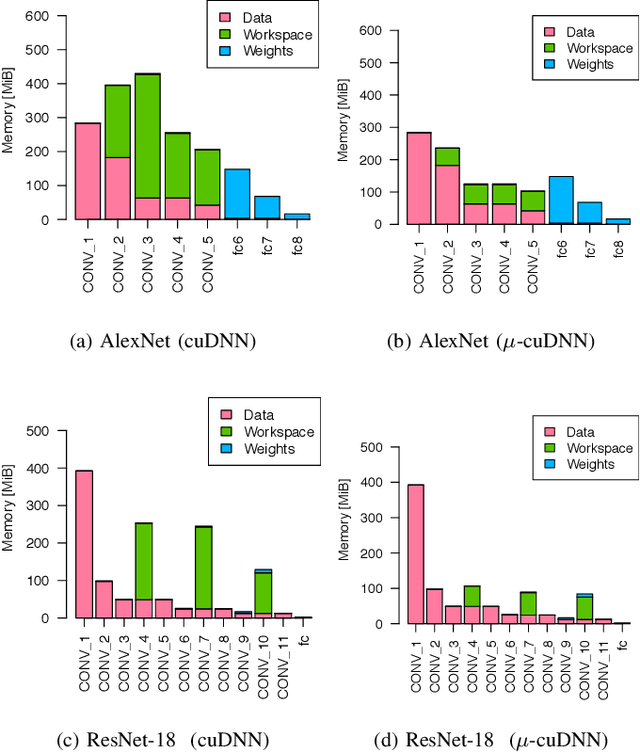
NVIDIA cuDNN is a low-level library that provides GPU kernels frequently used in deep learning. Specifically, cuDNN implements several equivalent convolution algorithms, whose performance and memory footprint may vary considerably, depending on the layer dimensions. When an algorithm is automatically selected by cuDNN, the decision is performed on a per-layer basis, and thus it often resorts to slower algorithms that fit the workspace size constraints. We present {\mu}-cuDNN, a transparent wrapper library for cuDNN, which divides layers' mini-batch computation into several micro-batches. Based on Dynamic Programming and Integer Linear Programming, {\mu}-cuDNN enables faster algorithms by decreasing the workspace requirements. At the same time, {\mu}-cuDNN keeps the computational semantics unchanged, so that it decouples statistical efficiency from the hardware efficiency safely. We demonstrate the effectiveness of {\mu}-cuDNN over two frameworks, Caffe and TensorFlow, achieving speedups of 1.63x for AlexNet and 1.21x for ResNet-18 on P100-SXM2 GPU. These results indicate that using micro-batches can seamlessly increase the performance of deep learning, while maintaining the same memory footprint.