 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Performance of Analog Training for Transfer Learning
May 16, 2025



Analog in-memory computing is a next-generation computing paradigm that promises fast, parallel, and energy-efficient deep learning training and transfer learning (TL). However, achieving this promise has remained elusive due to a lack of suitable training algorithms. Analog memory devices exhibit asymmetric and non-linear switching behavior in addition to device-to-device variation, meaning that most, if not all, of the current off-the-shelf training algorithms cannot achieve good training outcomes. Also, recently introduced algorithms have enjoyed limited attention, as they require bi-directionally switching devices of unrealistically high symmetry and precision and are highly sensitive. A new algorithm chopped TTv2 (c-TTv2), has been introduced, which leverages the chopped technique to address many of the challenges mentioned above. In this paper, we assess the performance of the c-TTv2 algorithm for analog TL using a Swin-ViT model on a subset of the CIFAR100 dataset. We also investigate the robustness of our algorithm to changes in some device specifications, including weight transfer noise, symmetry point skew, and symmetry point variability
Zero-shifting Technique for Deep Neural Network Training on Resistive Cross-point Arrays
Aug 02, 2019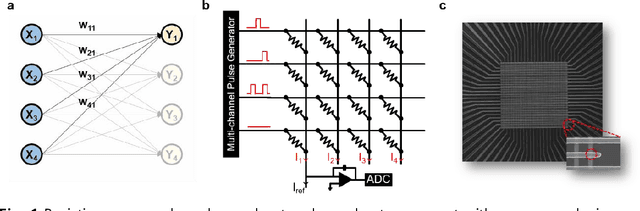
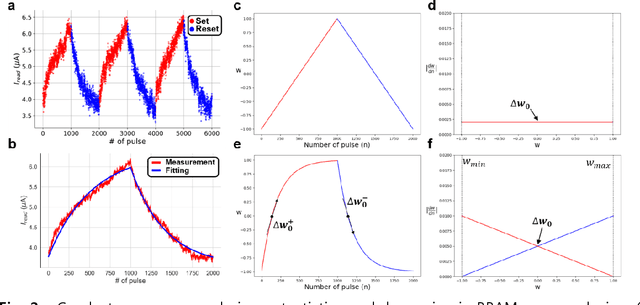
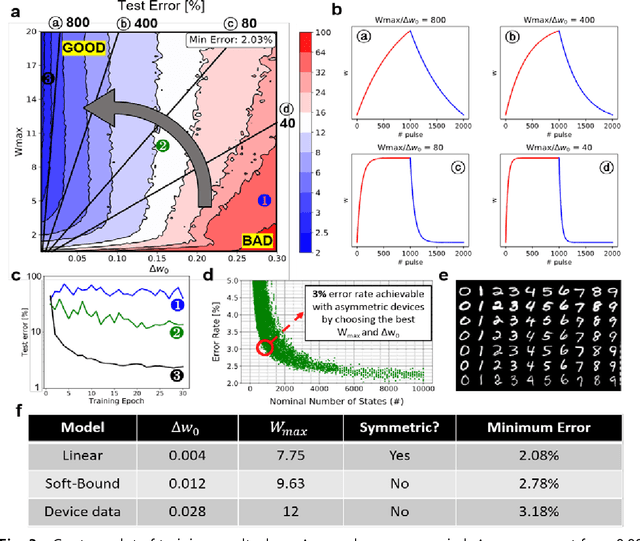
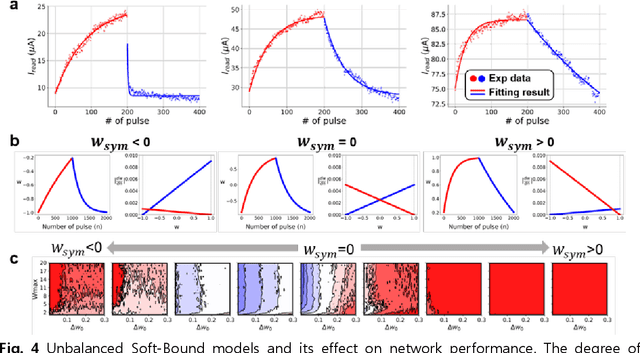
A resistive memory device-based computing architecture is one of the promising platforms for energy-efficient Deep Neural Network (DNN) training accelerators. The key technical challenge in realizing such accelerators is to accumulate the gradient information without a bias. Unlike the digital numbers in software which can be assigned and accessed with desired accuracy, numbers stored in resistive memory devices can only be manipulated following the physics of the device, which can significantly limit the training performance. Therefore, additional techniques and algorithm-level remedies are required to achieve the best possible performance in resistive memory device-based accelerators. In this paper, we analyze asymmetric conductance modulation characteristics in RRAM by Soft-bound synapse model and present an in-depth analysis on the relationship between device characteristics and DNN model accuracy using a 3-layer DNN trained on the MNIST dataset. We show that the imbalance between up and down update leads to a poor network performance. We introduce a concept of symmetry point and propose a zero-shifting technique which can compensate imbalance by programming the reference device and changing the zero value point of the weight. By using this zero-shifting method, we show that network performance dramatically improves for imbalanced synapse devices.