 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIBERO-Occ: Evaluating and Improving Vision-Language-Action Models under Scene-Induced Occlusion via Viewpoint Imagination
Jun 09, 2026Vision-Language-Action (VLA) models achieve strong performance on standard manipulation benchmarks, but most evaluations assume that task-relevant objects are fully visible. This assumption often fails in realistic settings, where occlusion makes manipulation partially observable. In this paper, we study \textit{scene-induced occlusion} as a fundamental challenge for VLA models and introduce \textbf{LIBERO-Occ}, an occlusion-oriented extension of LIBERO. Experiments show that state-of-the-art VLAs suffer substantial performance degradation under occlusion. To address this issue, we propose \textbf{Viewpoint Imagination (VIM)}, which generates a complementary view from an occluded primary observation and conditions action prediction on both observed and imagined evidence. VIM improves robustness across task suites, occlusion types, and severity levels without requiring additional cameras at deployment time, suggesting that viewpoint imagination is an promising mechanism for perception completion in partially observable manipulation. Our benchmark and corresponding code are available at: \href{https://github.com/litsh/Libero-Occ}{https://github.com/litsh/Libero-Occ}.
Recommending POIs for Tourists by User Behavior Modeling and Pseudo-Rating
Oct 14, 2021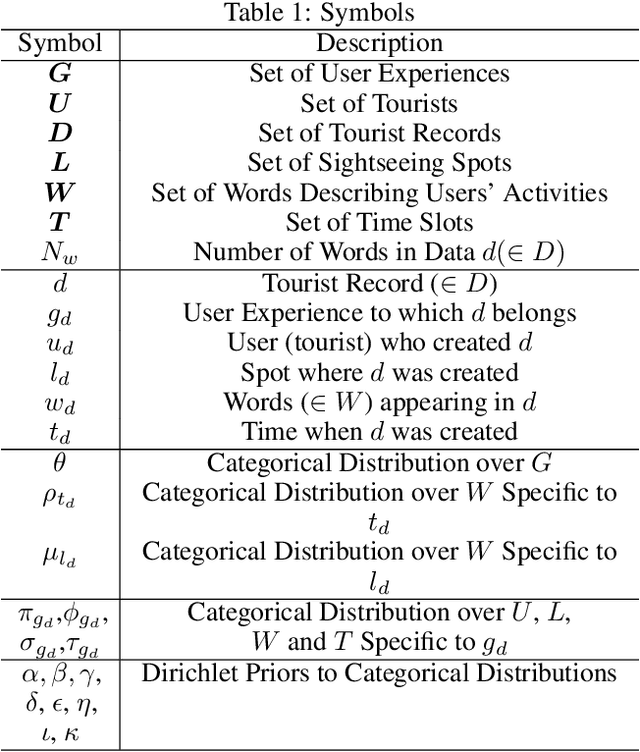
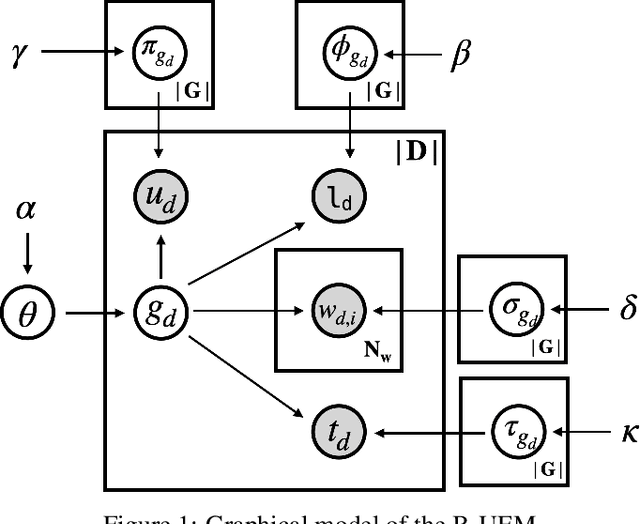
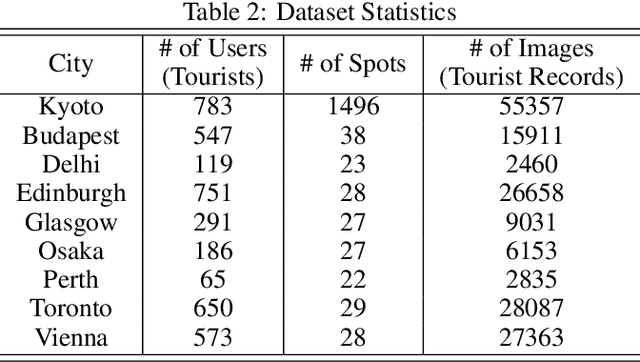
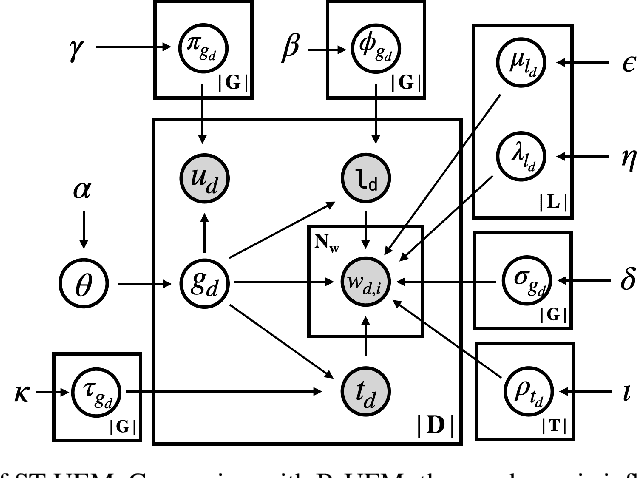
POI recommendation is a key task in tourism information systems. However, in contrast to conventional point of interest (POI) recommender systems, the available data is extremely sparse; most tourist visit a few sightseeing spots once and most of these spots have no check-in data from new tourists. Most conventional systems rank sightseeing spots based on their popularity, reputations, and category-based similarities with users' preferences. They do not clarify what users can experience in these spots, which makes it difficult to meet diverse tourism needs. To this end, in this work, we propose a mechanism to recommend POIs to tourists. Our mechanism include two components: one is a probabilistic model that reveals the user behaviors in tourism; the other is a pseudo rating mechanism to handle the cold-start issue in POIs recommendations. We carried out extensive experiments with two datasets collected from Flickr. The experimental results demonstrate that our methods are superior to the state-of-the-art methods in both the recommendation performances (precision, recall and F-measure) and fairness. The experimental results also validate the robustness of the proposed methods, i.e., our methods can handle well the issue of data sparsity.