 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVOID: The Adverse Visual Conditions Dataset with Obstacles for Driving Scene Understanding
Dec 29, 2025Understanding road scenes for visual perception remains crucial for intelligent self-driving cars. In particular, it is desirable to detect unexpected small road hazards reliably in real-time, especially under varying adverse conditions (e.g., weather and daylight). However, existing road driving datasets provide large-scale images acquired in either normal or adverse scenarios only, and often do not contain the road obstacles captured in the same visual domain as for the other classes. To address this, we introduce a new dataset called AVOID, the Adverse Visual Conditions Dataset, for real-time obstacle detection collected in a simulated environment. AVOID consists of a large set of unexpected road obstacles located along each path captured under various weather and time conditions. Each image is coupled with the corresponding semantic and depth maps, raw and semantic LiDAR data, and waypoints, thereby supporting most visual perception tasks. We benchmark the results on high-performing real-time networks for the obstacle detection task, and also propose and conduct ablation studies using a comprehensive multi-task network for semantic segmentation, depth and waypoint prediction tasks.
3-D Scene Graph: A Sparse and Semantic Representation of Physical Environments for Intelligent Agents
Aug 14, 2019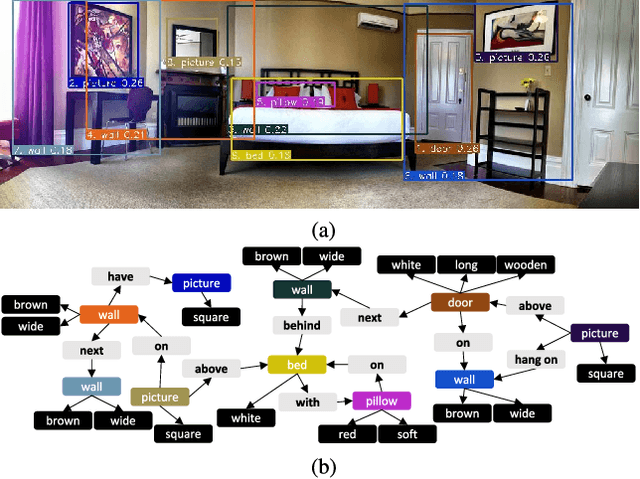
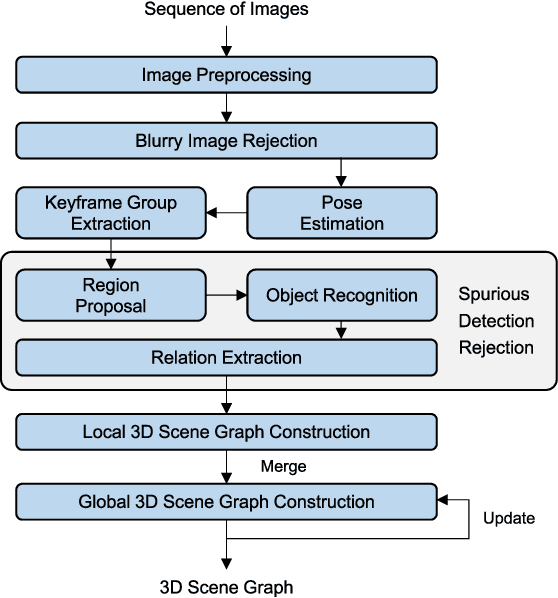
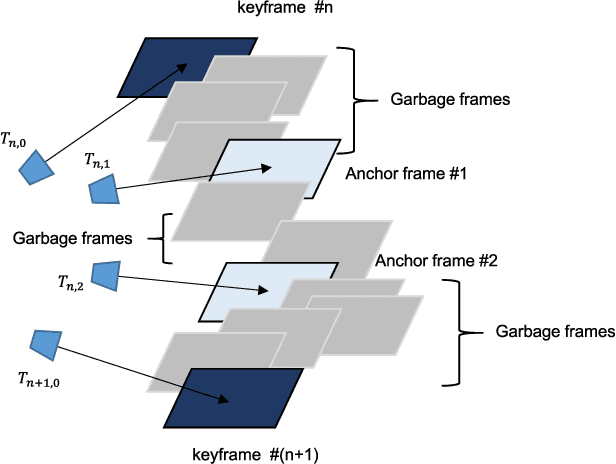
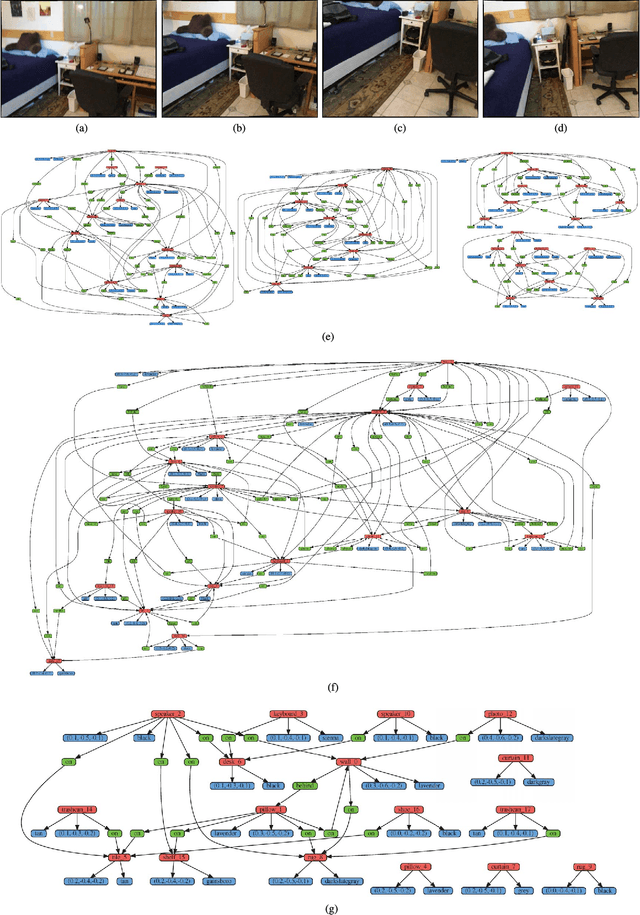
Intelligent agents gather information and perceive semantics within the environments before taking on given tasks. The agents store the collected information in the form of environment models that compactly represent the surrounding environments. The agents, however, can only conduct limited tasks without an efficient and effective environment model. Thus, such an environment model takes a crucial role for the autonomy systems of intelligent agents. We claim the following characteristics for a versatile environment model: accuracy, applicability, usability, and scalability. Although a number of researchers have attempted to develop such models that represent environments precisely to a certain degree, they lack broad applicability, intuitive usability, and satisfactory scalability. To tackle these limitations, we propose 3-D scene graph as an environment model and the 3-D scene graph construction framework. The concise and widely used graph structure readily guarantees usability as well as scalability for 3-D scene graph. We demonstrate the accuracy and applicability of the 3-D scene graph by exhibiting the deployment of the 3-D scene graph in practical applications. Moreover, we verify the performance of the proposed 3-D scene graph and the framework by conducting a series of comprehensive experiments under various conditions.