 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-inspired probabilistic generative model for double articulation analysis of spoken language
Jul 06, 2022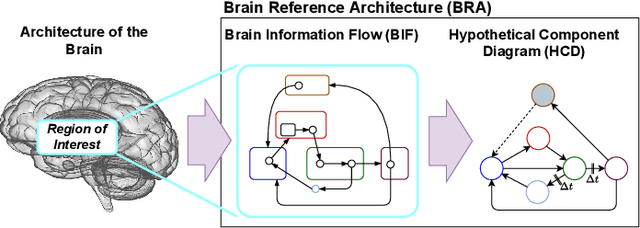
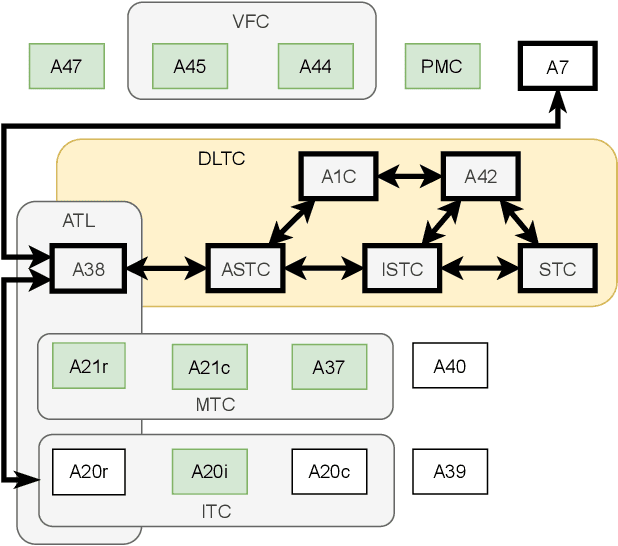
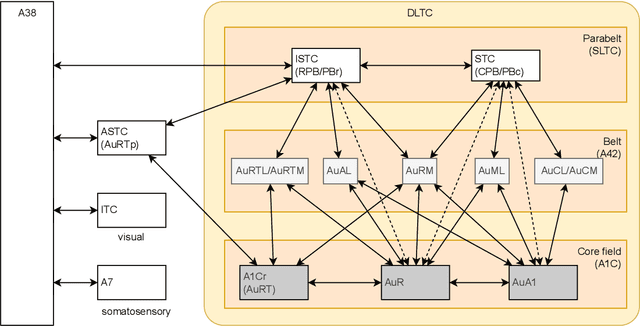
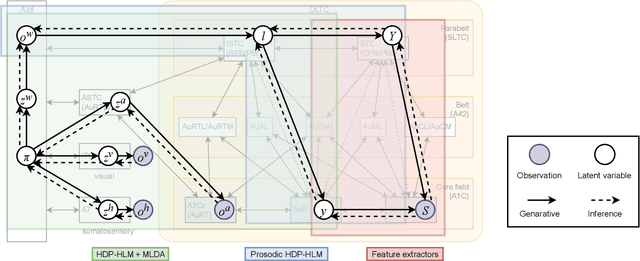
The human brain, among its several functions, analyzes the double articulation structure in spoken language, i.e., double articulation analysis (DAA). A hierarchical structure in which words are connected to form a sentence and words are composed of phonemes or syllables is called a double articulation structure. Where and how DAA is performed in the human brain has not been established, although some insights have been obtained. In addition, existing computational models based on a probabilistic generative model (PGM) do not incorporate neuroscientific findings, and their consistency with the brain has not been previously discussed. This study compared, mapped, and integrated these existing computational models with neuroscientific findings to bridge this gap, and the findings are relevant for future applications and further research. This study proposes a PGM for a DAA hypothesis that can be realized in the brain based on the outcomes of several neuroscientific surveys. The study involved (i) investigation and organization of anatomical structures related to spoken language processing, and (ii) design of a PGM that matches the anatomy and functions of the region of interest. Therefore, this study provides novel insights that will be foundational to further exploring DAA in the brain.
Speak Like a Dog: Human to Non-human creature Voice Conversion
Jun 09, 2022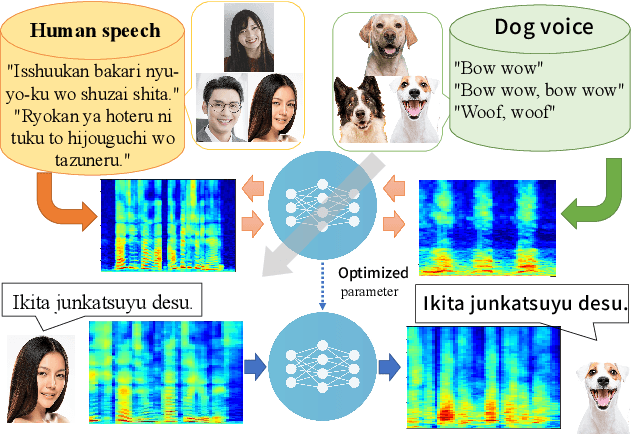
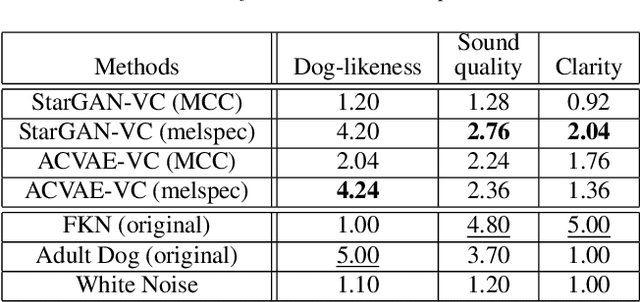
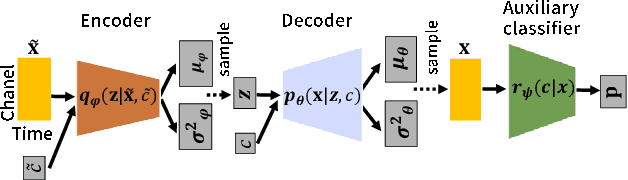
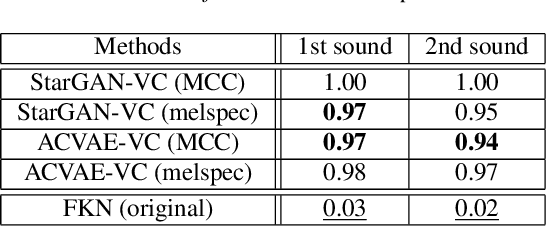
This paper proposes a new voice conversion (VC) task from human speech to dog-like speech while preserving linguistic information as an example of human to non-human creature voice conversion (H2NH-VC) tasks. Although most VC studies deal with human to human VC, H2NH-VC aims to convert human speech into non-human creature-like speech. Non-parallel VC allows us to develop H2NH-VC, because we cannot collect a parallel dataset that non-human creatures speak human language. In this study, we propose to use dogs as an example of a non-human creature target domain and define the "speak like a dog" task. To clarify the possibilities and characteristics of the "speak like a dog" task, we conducted a comparative experiment using existing representative non-parallel VC methods in acoustic features (Mel-cepstral coefficients and Mel-spectrograms), network architectures (five different kernel-size settings), and training criteria (variational autoencoder (VAE)- based and generative adversarial network-based). Finally, the converted voices were evaluated using mean opinion scores: dog-likeness, sound quality and intelligibility, and character error rate (CER). The experiment showed that the employment of the Mel-spectrogram improved the dog-likeness of the converted speech, while it is challenging to preserve linguistic information. Challenges and limitations of the current VC methods for H2NH-VC are highlighted.
Symbol Emergence as Inter-personal Categorization with Head-to-head Latent Word
May 24, 2022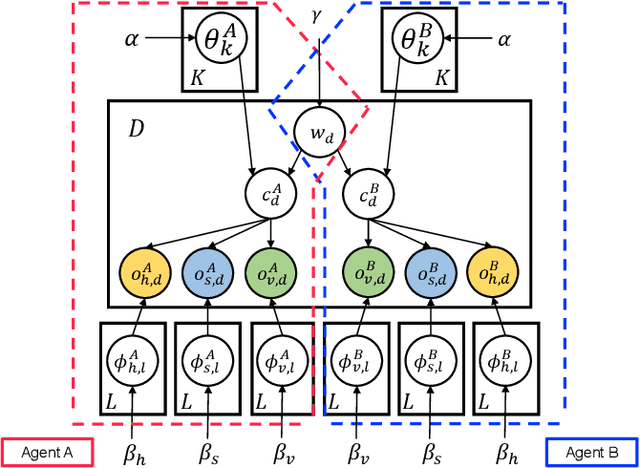
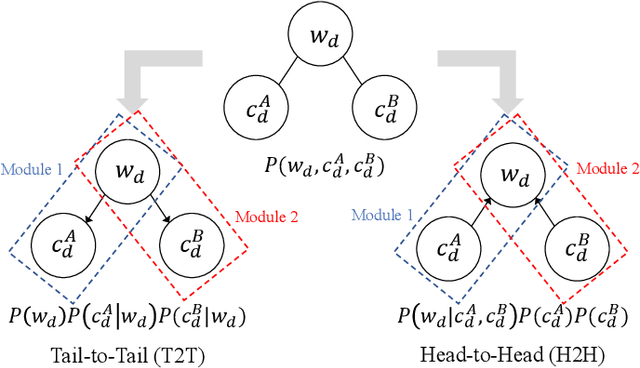
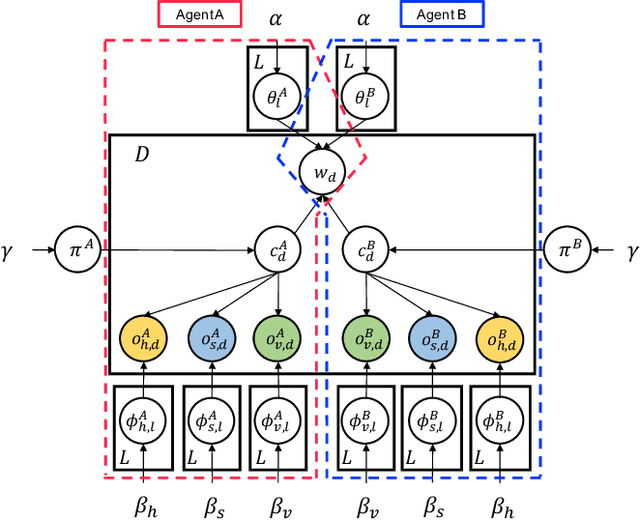
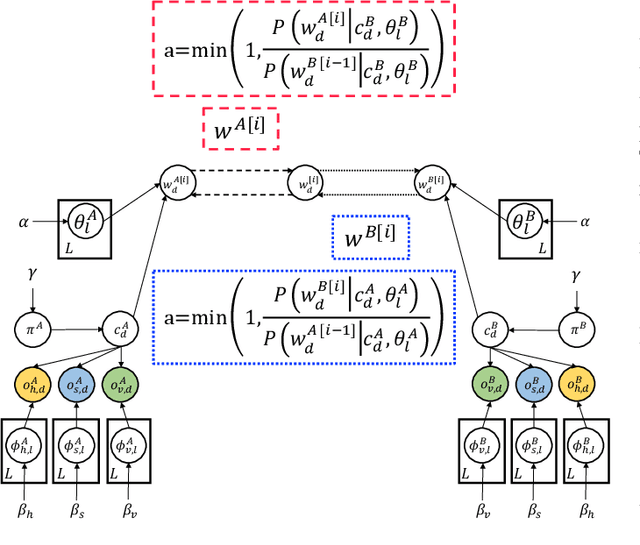
In this study, we propose a head-to-head type (H2H-type) inter-personal multimodal Dirichlet mixture (Inter-MDM) by modifying the original Inter-MDM, which is a probabilistic generative model that represents the symbol emergence between two agents as multiagent multimodal categorization. A Metropolis--Hastings method-based naming game based on the Inter-MDM enables two agents to collaboratively perform multimodal categorization and share signs with a solid mathematical foundation of convergence. However, the conventional Inter-MDM presumes a tail-to-tail connection across a latent word variable, causing inflexibility of the further extension of Inter-MDM for modeling a more complex symbol emergence. Therefore, we propose herein a head-to-head type (H2H-type) Inter-MDM that treats a latent word variable as a child node of an internal variable of each agent in the same way as many prior studies of multimodal categorization. On the basis of the H2H-type Inter-MDM, we propose a naming game in the same way as the conventional Inter-MDM. The experimental results show that the H2H-type Inter-MDM yields almost the same performance as the conventional Inter-MDM from the viewpoint of multimodal categorization and sign sharing.
Emergent Communication through Metropolis-Hastings Naming Game with Deep Generative Models
May 24, 2022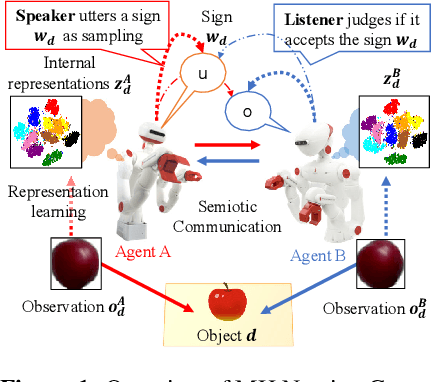
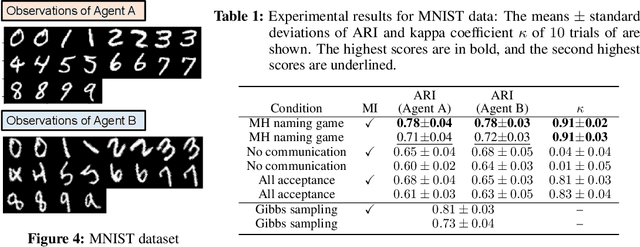
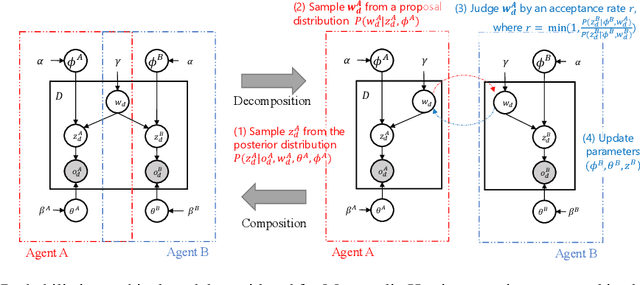
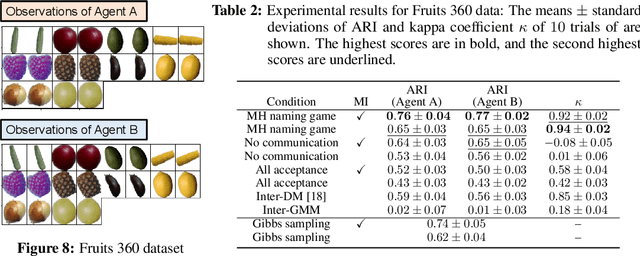
Emergent communication, also known as symbol emergence, seeks to investigate computational models that can better explain human language evolution and the creation of symbol systems. This study aims to provide a new model for emergent communication, which is based on a probabilistic generative model. We define the Metropolis-Hastings (MH) naming game by generalizing a model proposed by Hagiwara et al. \cite{hagiwara2019symbol}. The MH naming game is a sort of MH algorithm for an integrative probabilistic generative model that combines two agents playing the naming game. From this viewpoint, symbol emergence is regarded as decentralized Bayesian inference, and semiotic communication is regarded as inter-personal cross-modal inference. We also offer Inter-GMM+VAE, a deep generative model for simulating emergent communication, in which two agents create internal representations and categories and share signs (i.e., names of objects) from raw visual images observed from different viewpoints. The model has been validated on MNIST and Fruits 360 datasets. Experiment findings show that categories are formed from real images observed by agents, and signs are correctly shared across agents by successfully utilizing both of the agents' views via the MH naming game. Furthermore, it has been verified that the visual images were recalled from the signs uttered by the agents. Notably, emergent communication without supervision and reward feedback improved the performance of unsupervised representation learning.
Self-Supervised Representation Learning as Multimodal Variational Inference
Mar 22, 2022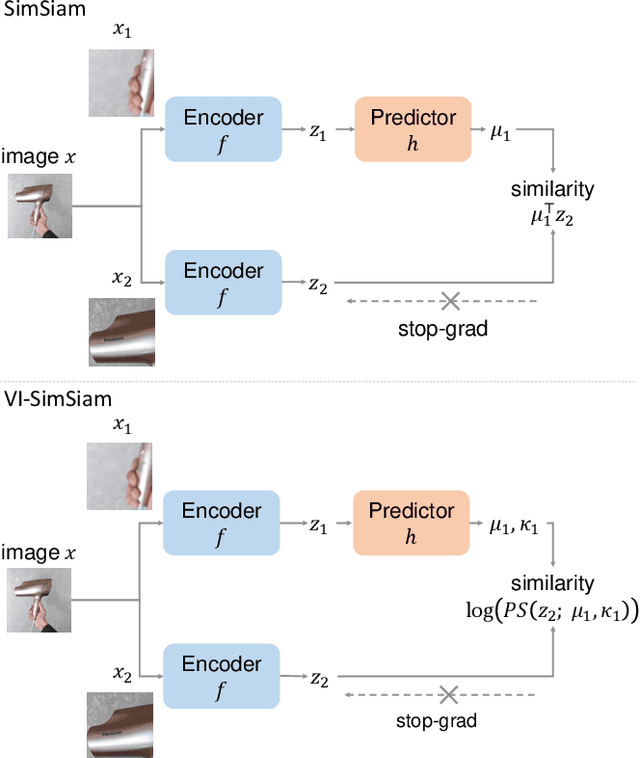

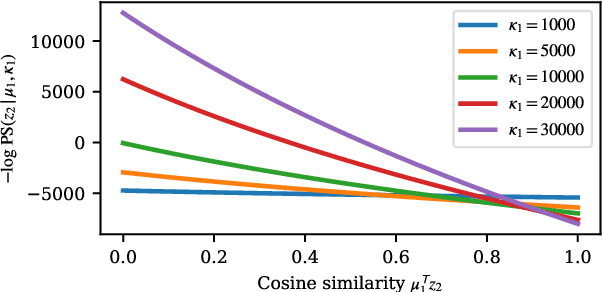
This paper proposes a probabilistic extension of SimSiam, a recent self-supervised learning (SSL) method. SimSiam trains a model by maximizing the similarity between image representations of different augmented views of the same image. Although uncertainty-aware machine learning has been getting general like deep variational inference, SimSiam and other SSL are insufficiently uncertainty-aware, which could lead to limitations on its potential. The proposed extension is to make SimSiam uncertainty-aware based on variational inference. Our main contributions are twofold: Firstly, we clarify the theoretical relationship between non-contrastive SSL and multimodal variational inference. Secondly, we introduce a novel SSL called variational inference SimSiam (VI-SimSiam), which incorporates the uncertainty by involving spherical posterior distributions. Our experiment shows that VI-SimSiam outperforms SimSiam in classification tasks in ImageNette and ImageWoof by successfully estimating the representation uncertainty.
Spatial Concept-based Topometric Semantic Mapping for Hierarchical Path-planning from Speech Instructions
Mar 21, 2022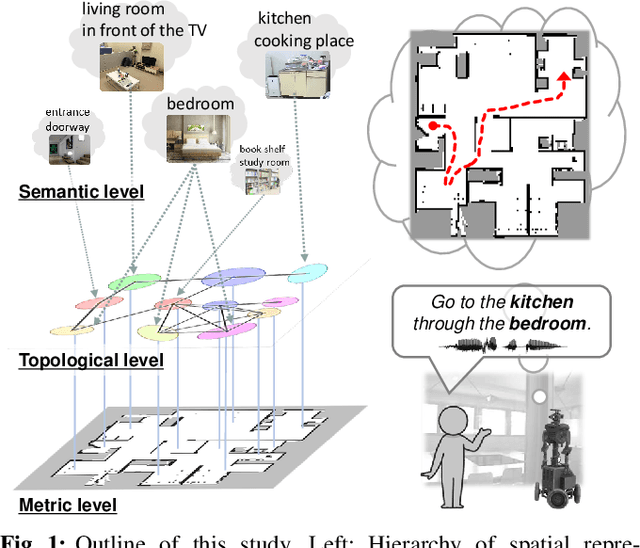
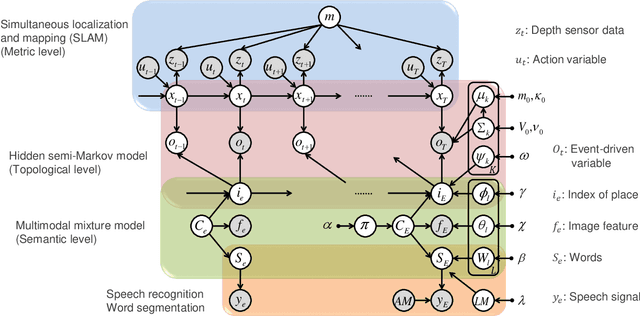
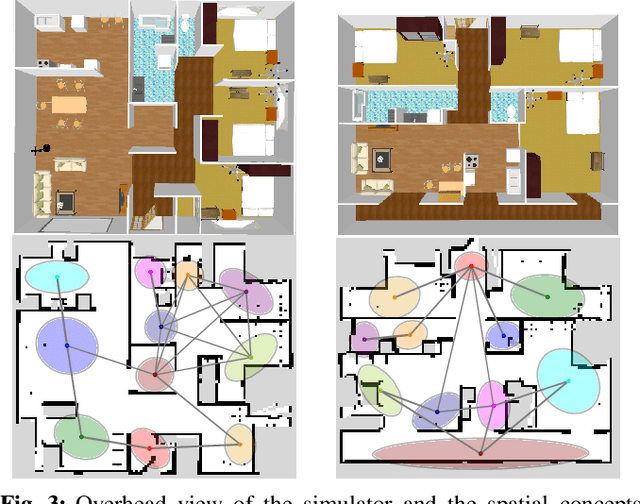
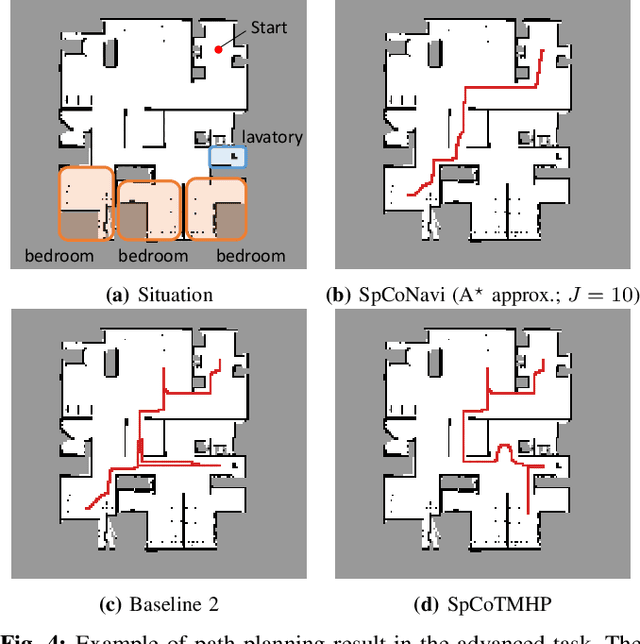
Navigating to destinations using human speech instructions is an important task for autonomous mobile robots that operate in the real world. Spatial representations include a semantic level that represents an abstracted location category, a topological level that represents their connectivity, and a metric level that depends on the structure of the environment. The purpose of this study is to realize a hierarchical spatial representation using a topometric semantic map and planning efficient paths through human-robot interactions. We propose a novel probabilistic generative model, SpCoTMHP, that forms a topometric semantic map that adapts to the environment and leads to hierarchical path planning. We also developed approximate inference methods for path planning, where the levels of the hierarchy can influence each other. The proposed path planning method is theoretically supported by deriving a formulation based on control as probabilistic inference. The navigation experiment using human speech instruction shows that the proposed spatial concept-based hierarchical path planning improves the performance and reduces the calculation cost compared with conventional methods. Hierarchical spatial representation provides a mutually understandable form for humans and robots to render language-based navigation tasks feasible.
Multi-View Dreaming: Multi-View World Model with Contrastive Learning
Mar 15, 2022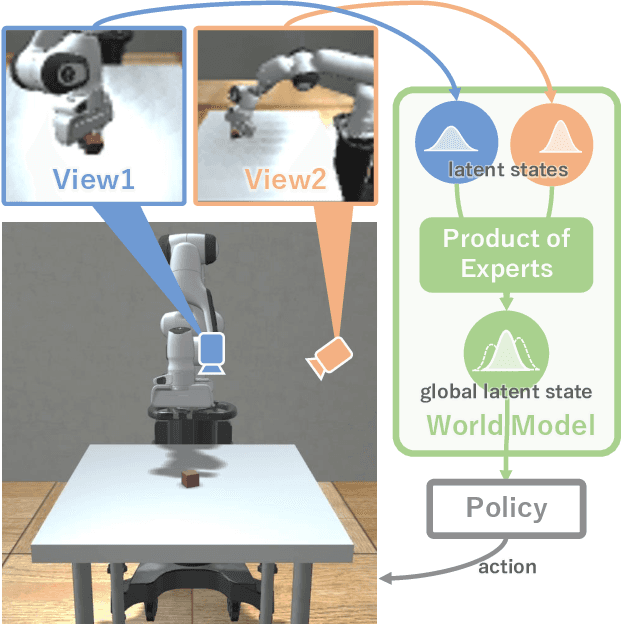
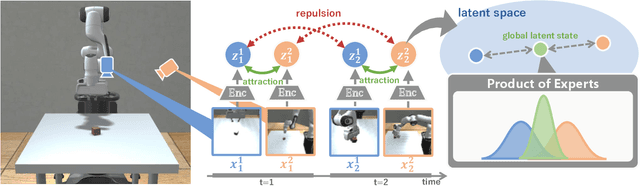
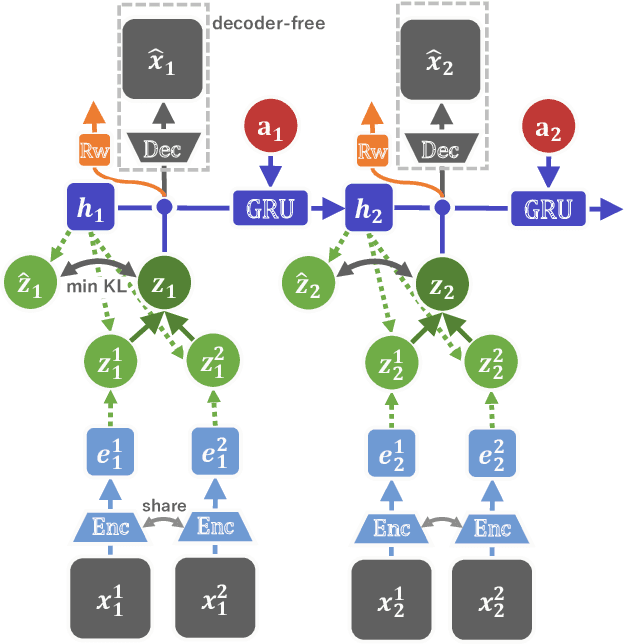
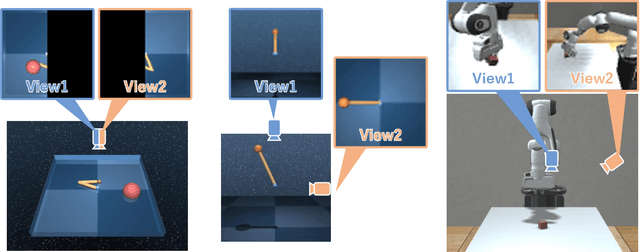
In this paper, we propose Multi-View Dreaming, a novel reinforcement learning agent for integrated recognition and control from multi-view observations by extending Dreaming. Most current reinforcement learning method assumes a single-view observation space, and this imposes limitations on the observed data, such as lack of spatial information and occlusions. This makes obtaining ideal observational information from the environment difficult and is a bottleneck for real-world robotics applications. In this paper, we use contrastive learning to train a shared latent space between different viewpoints, and show how the Products of Experts approach can be used to integrate and control the probability distributions of latent states for multiple viewpoints. We also propose Multi-View DreamingV2, a variant of Multi-View Dreaming that uses a categorical distribution to model the latent state instead of the Gaussian distribution. Experiments show that the proposed method outperforms simple extensions of existing methods in a realistic robot control task.
Tactile-Sensitive NewtonianVAE for High-Accuracy Industrial Connector-Socket Insertion
Mar 10, 2022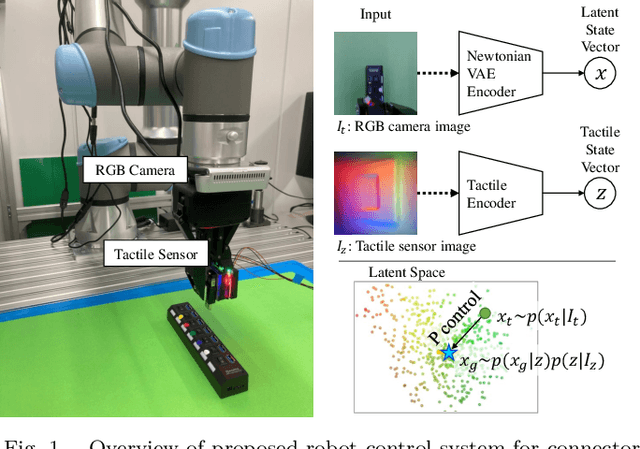
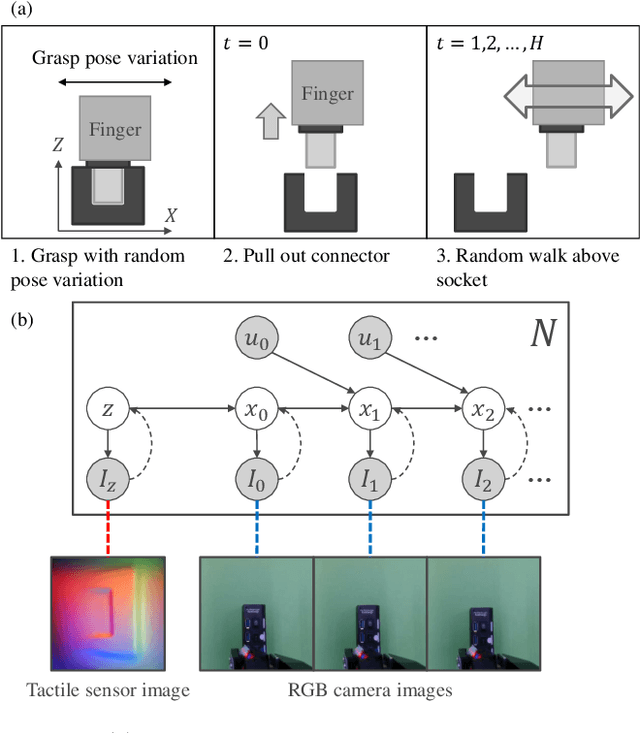
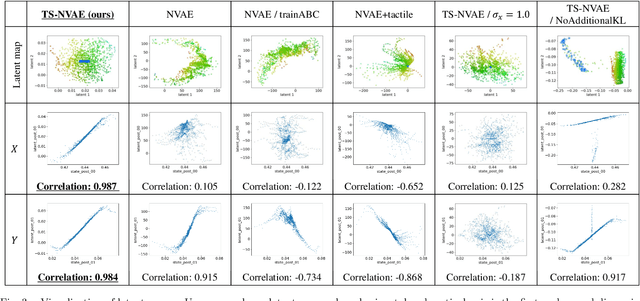
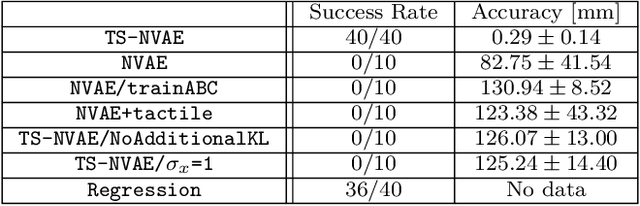
An industrial connector-socket insertion task requires sub-millimeter positioning and compensation of grasp pose of a connector. Thus high accurate estimation of relative pose between socket and connector is a key factor to achieve the task. World models are promising technology for visuo-motor control. They obtain appropriate state representation for control to jointly optimize feature extraction and latent dynamics model. Recent study shows NewtonianVAE, which is a kind of the world models, acquires latent space which is equivalent to mapping from images to physical coordinate. Proportional control can be achieved in the latent space of NewtonianVAE. However, application of NewtonianVAE to high accuracy industrial tasks in physical environments is open problem. Moreover, there is no general frameworks to compensate goal position in the obtained latent space considering the grasp pose. In this work, we apply NewtonianVAE to USB connector insertion with grasp pose variation in the physical environments. We adopt a GelSight type tactile sensor and estimate insertion position compensated by the grasp pose of the connector. Our method trains the latent space in an end-to-end manner, and simple proportional control is available. Therefore, it requires no additional engineering and annotation. Experimental results show that the proposed method, Tactile-Sensitive NewtonianVAE, outperforms naive combination of regression-based grasp pose estimator and coordinate transformation. Moreover, we reveal the original NewtonianVAE does not work in some situation, and demonstrate that domain knowledge induction improves model accuracy. This domain knowledge is easy to be known from specification of robots or measurement.
DreamingV2: Reinforcement Learning with Discrete World Models without Reconstruction
Mar 01, 2022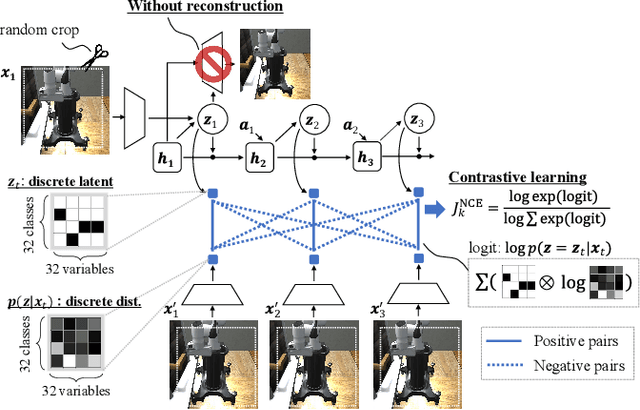
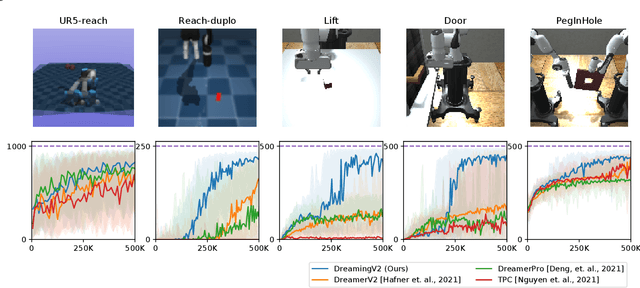
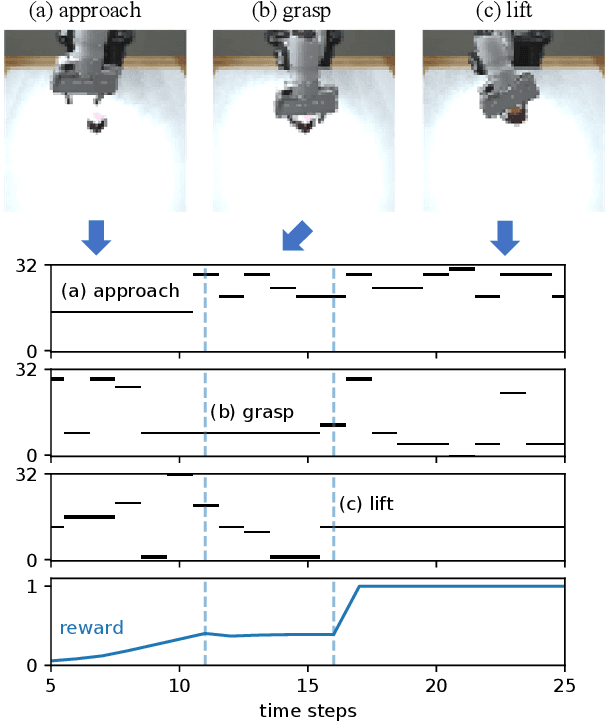
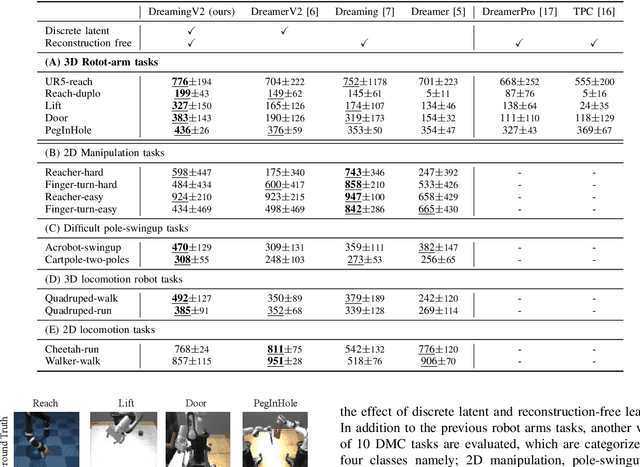
The present paper proposes a novel reinforcement learning method with world models, DreamingV2, a collaborative extension of DreamerV2 and Dreaming. DreamerV2 is a cutting-edge model-based reinforcement learning from pixels that uses discrete world models to represent latent states with categorical variables. Dreaming is also a form of reinforcement learning from pixels that attempts to avoid the autoencoding process in general world model training by involving a reconstruction-free contrastive learning objective. The proposed DreamingV2 is a novel approach of adopting both the discrete representation of DreamingV2 and the reconstruction-free objective of Dreaming. Compared to DreamerV2 and other recent model-based methods without reconstruction, DreamingV2 achieves the best scores on five simulated challenging 3D robot arm tasks. We believe that DreamingV2 will be a reliable solution for robot learning since its discrete representation is suitable to describe discontinuous environments, and the reconstruction-free fashion well manages complex vision observations.
Unsupervised Multimodal Word Discovery based on Double Articulation Analysis with Co-occurrence cues
Jan 18, 2022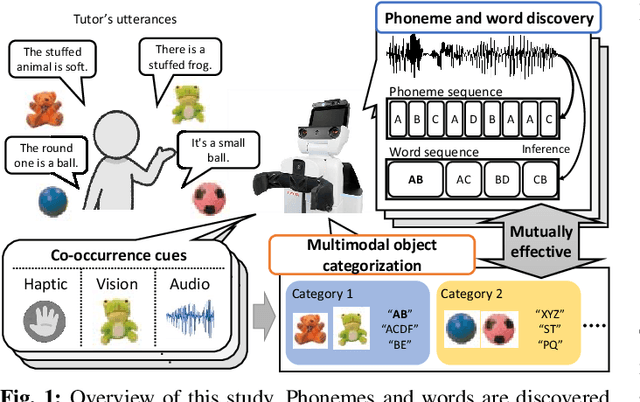
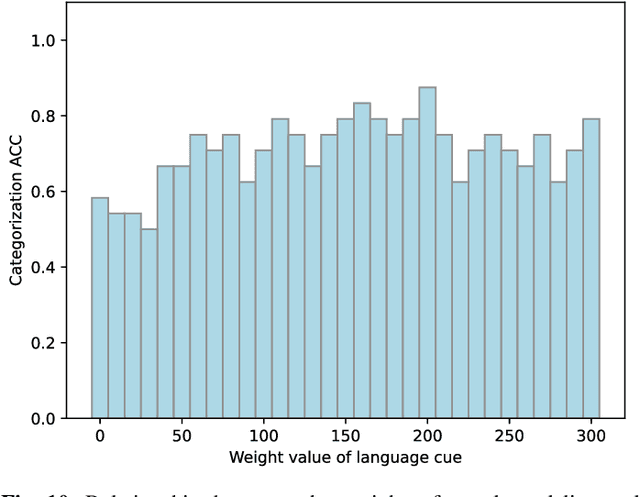
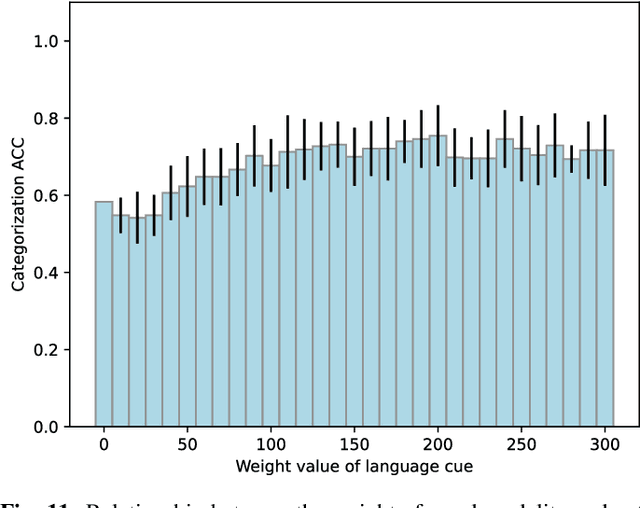
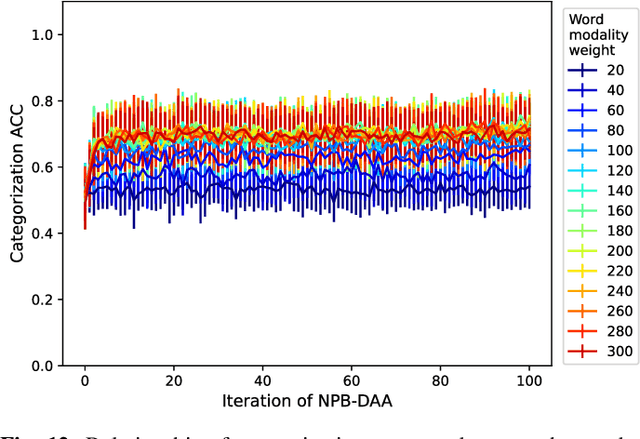
Human infants acquire their verbal lexicon from minimal prior knowledge of language based on the statistical properties of phonological distributions and the co-occurrence of other sensory stimuli. In this study, we propose a novel fully unsupervised learning method discovering speech units by utilizing phonological information as a distributional cue and object information as a co-occurrence cue. The proposed method can not only (1) acquire words and phonemes from speech signals using unsupervised learning, but can also (2) utilize object information based on multiple modalities (i.e., vision, tactile, and auditory) simultaneously. The proposed method is based on the Nonparametric Bayesian Double Articulation Analyzer (NPB-DAA) discovering phonemes and words from phonological features, and Multimodal Latent Dirichlet Allocation (MLDA) categorizing multimodal information obtained from objects. In the experiment, the proposed method showed higher word discovery performance than the baseline methods. In particular, words that expressed the characteristics of the object (i.e., words corresponding to nouns and adjectives) were segmented accurately. Furthermore, we examined how learning performance is affected by differences in the importance of linguistic information. When the weight of the word modality was increased, the performance was further improved compared to the fixed condition.