 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Few-Step Generative Models by Amortizing Sample-based Variational Inference
May 27, 2026Aligning a few-step generative model is challenging, since existing alignment frameworks typically rely on restrictive assumptions: a tractable likelihood, a specific ODE/SDE solver, or a particular model family. We introduce FAV, Few-step Generative Models Alignment via Sample-based Variational Inference, a general alignment framework that requires only sample access to the generator and the reference distribution. We cast alignment as sampling from a reward-tilted distribution anchored to a reference distribution. We leverage Stein Variational Gradient Descent as a sample-based variational inference scheme and amortize its particle updates into the generator parameters via fixed-point regression. We evaluate FAV on two domains: robotics manipulation and image generator alignment. On generative policy alignment for robotic manipulation, FAV outperforms prevailing policy extraction baselines across 56 offline and 30 offline-to-online RL tasks. For image generator alignment, FAV fine-tunes diverse few-step backbones, including GAN, drifting model, consistency models, and flow maps, scaling from ImageNet-$256$ to 1024$^2$ text-to-image synthesis. Code is available at https://github.com/Jaewoopudding/FAV.
Learning by Doing: Controlling a Dynamical System using Causality, Control, and Reinforcement Learning
Feb 12, 2022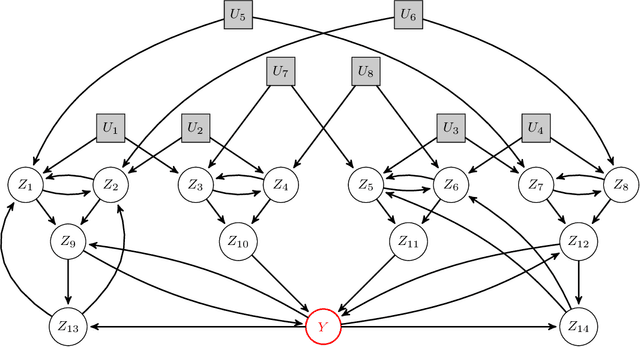
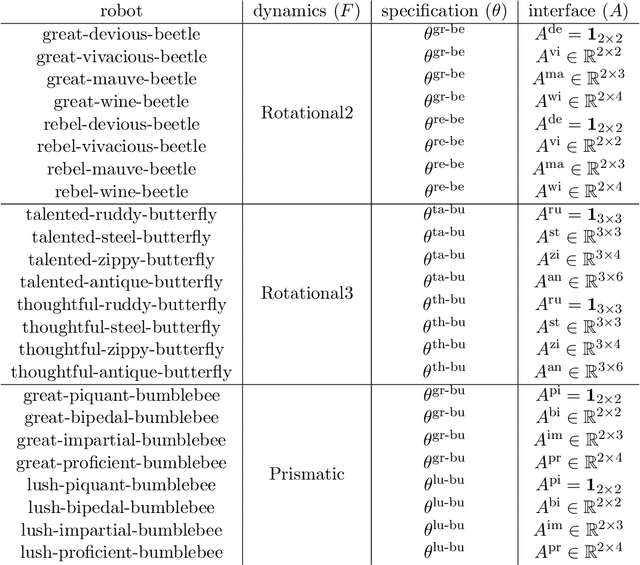
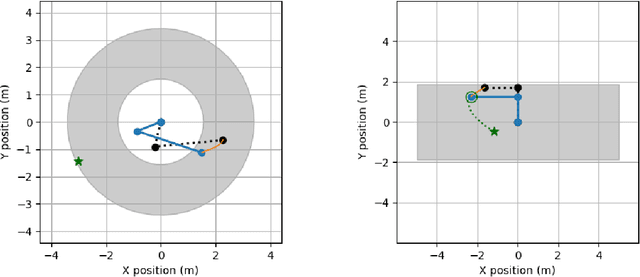
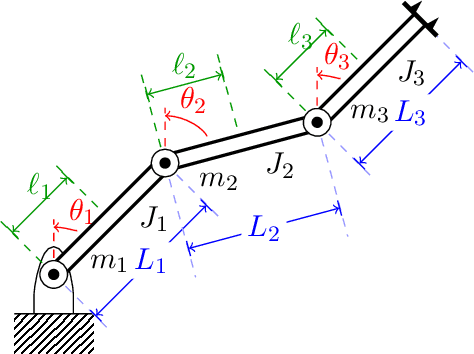
Questions in causality, control, and reinforcement learning go beyond the classical machine learning task of prediction under i.i.d. observations. Instead, these fields consider the problem of learning how to actively perturb a system to achieve a certain effect on a response variable. Arguably, they have complementary views on the problem: In control, one usually aims to first identify the system by excitation strategies to then apply model-based design techniques to control the system. In (non-model-based) reinforcement learning, one directly optimizes a reward. In causality, one focus is on identifiability of causal structure. We believe that combining the different views might create synergies and this competition is meant as a first step toward such synergies. The participants had access to observational and (offline) interventional data generated by dynamical systems. Track CHEM considers an open-loop problem in which a single impulse at the beginning of the dynamics can be set, while Track ROBO considers a closed-loop problem in which control variables can be set at each time step. The goal in both tracks is to infer controls that drive the system to a desired state. Code is open-sourced ( https://github.com/LearningByDoingCompetition/learningbydoing-comp ) to reproduce the winning solutions of the competition and to facilitate trying out new methods on the competition tasks.