 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fair pricing model via adversarial learning
Mar 07, 2022
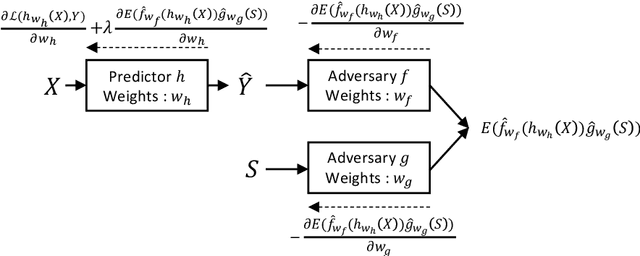

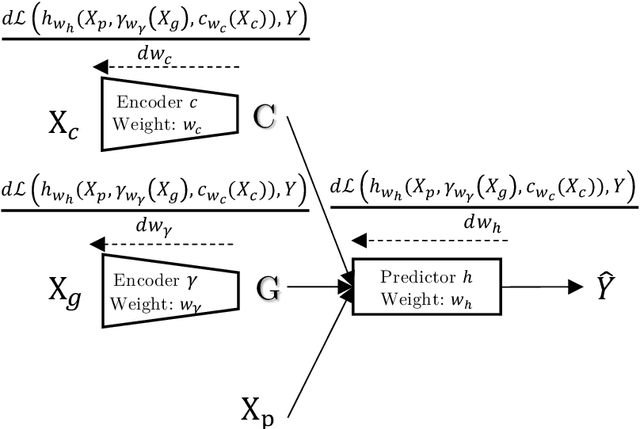
At the core of insurance business lies classification between risky and non-risky insureds, actuarial fairness meaning that risky insureds should contribute more and pay a higher premium than non-risky or less-risky ones. Actuaries, therefore, use econometric or machine learning techniques to classify, but the distinction between a fair actuarial classification and "discrimination" is subtle. For this reason, there is a growing interest about fairness and discrimination in the actuarial community Lindholm, Richman, Tsanakas, and Wuthrich (2022). Presumably, non-sensitive characteristics can serve as substitutes or proxies for protected attributes. For example, the color and model of a car, combined with the driver's occupation, may lead to an undesirable gender bias in the prediction of car insurance prices. Surprisingly, we will show that debiasing the predictor alone may be insufficient to maintain adequate accuracy (1). Indeed, the traditional pricing model is currently built in a two-stage structure that considers many potentially biased components such as car or geographic risks. We will show that this traditional structure has significant limitations in achieving fairness. For this reason, we have developed a novel pricing model approach. Recently some approaches have Blier-Wong, Cossette, Lamontagne, and Marceau (2021); Wuthrich and Merz (2021) shown the value of autoencoders in pricing. In this paper, we will show that (2) this can be generalized to multiple pricing factors (geographic, car type), (3) it perfectly adapted for a fairness context (since it allows to debias the set of pricing components): We extend this main idea to a general framework in which a single whole pricing model is trained by generating the geographic and car pricing components needed to predict the pure premium while mitigating the unwanted bias according to the desired metric.
Generative Cooperative Networks for Natural Language Generation
Jan 28, 2022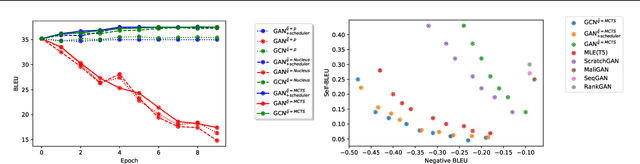
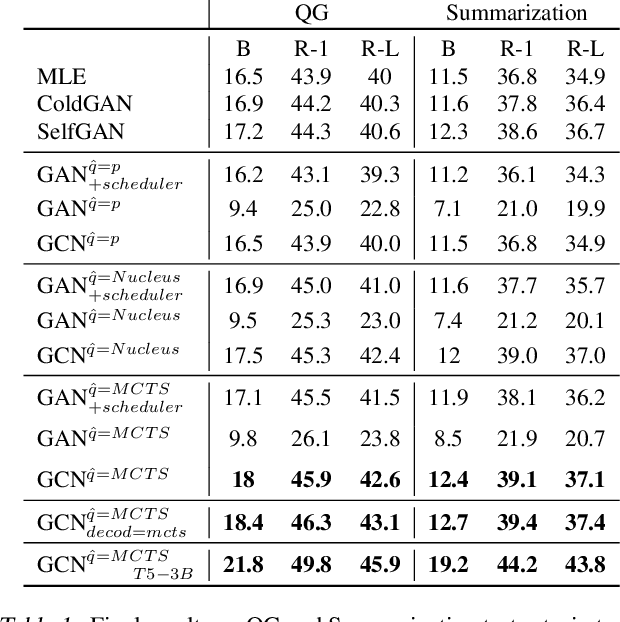
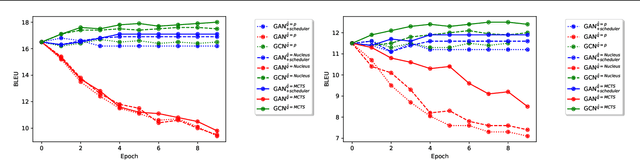
Generative Adversarial Networks (GANs) have known a tremendous success for many continuous generation tasks, especially in the field of image generation. However, for discrete outputs such as language, optimizing GANs remains an open problem with many instabilities, as no gradient can be properly back-propagated from the discriminator output to the generator parameters. An alternative is to learn the generator network via reinforcement learning, using the discriminator signal as a reward, but such a technique suffers from moving rewards and vanishing gradient problems. Finally, it often falls short compared to direct maximum-likelihood approaches. In this paper, we introduce Generative Cooperative Networks, in which the discriminator architecture is cooperatively used along with the generation policy to output samples of realistic texts for the task at hand. We give theoretical guarantees of convergence for our approach, and study various efficient decoding schemes to empirically achieve state-of-the-art results in two main NLG tasks.
Fairness without the sensitive attribute via Causal Variational Autoencoder
Sep 10, 2021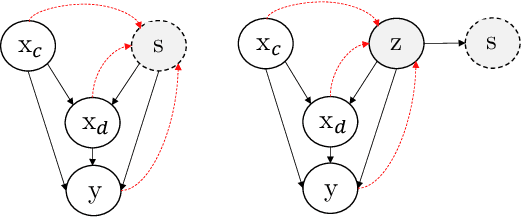
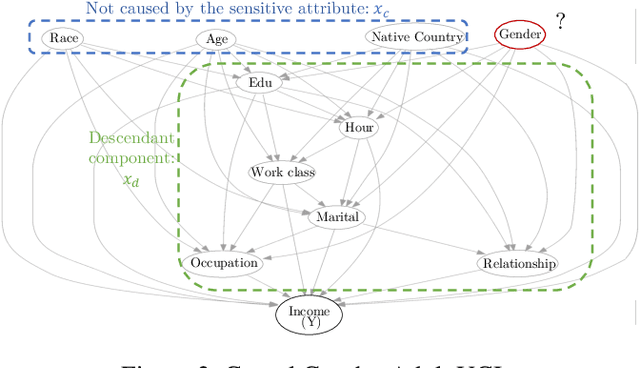
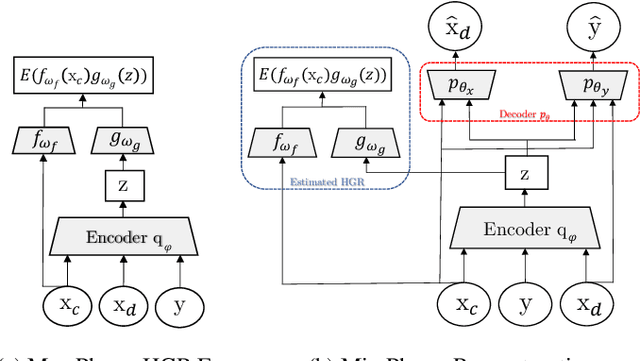
In recent years, most fairness strategies in machine learning models focus on mitigating unwanted biases by assuming that the sensitive information is observed. However this is not always possible in practice. Due to privacy purposes and var-ious regulations such as RGPD in EU, many personal sensitive attributes are frequently not collected. We notice a lack of approaches for mitigating bias in such difficult settings, in particular for achieving classical fairness objectives such as Demographic Parity and Equalized Odds. By leveraging recent developments for approximate inference, we propose an approach to fill this gap. Based on a causal graph, we rely on a new variational auto-encoding based framework named SRCVAE to infer a sensitive information proxy, that serve for bias mitigation in an adversarial fairness approach. We empirically demonstrate significant improvements over existing works in the field. We observe that the generated proxy's latent space recovers sensitive information and that our approach achieves a higher accuracy while obtaining the same level of fairness on two real datasets, as measured using com-mon fairness definitions.
To Beam Or Not To Beam: That is a Question of Cooperation for Language GANs
Jun 11, 2021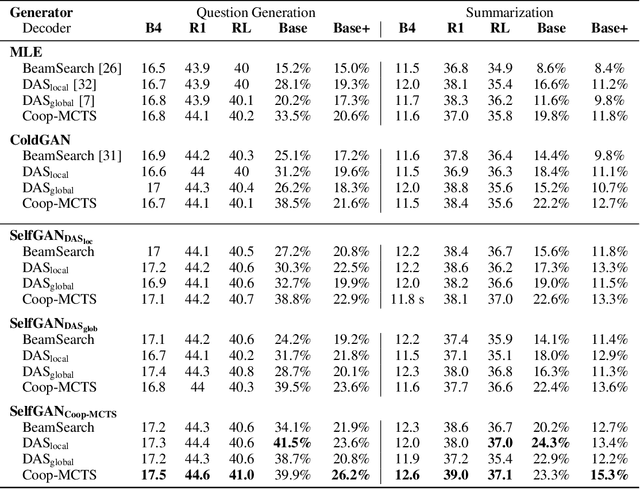
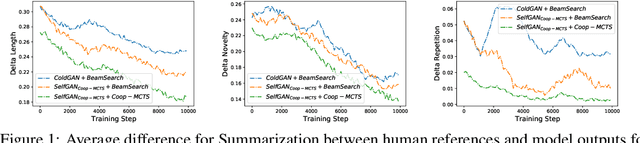
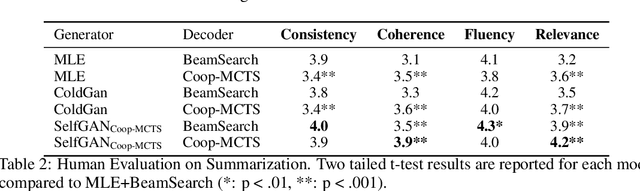
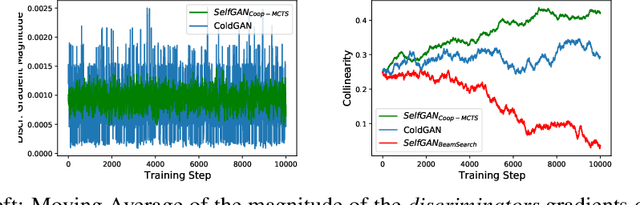
Due to the discrete nature of words, language GANs require to be optimized from rewards provided by discriminator networks, via reinforcement learning methods. This is a much harder setting than for continuous tasks, which enjoy gradient flows from discriminators to generators, usually leading to dramatic learning instabilities. However, we claim that this can be solved by making discriminator and generator networks cooperate to produce output sequences during training. These cooperative outputs, inherently built to obtain higher discrimination scores, not only provide denser rewards for training, but also form a more compact artificial set for discriminator training, hence improving its accuracy and stability. In this paper, we show that our SelfGAN framework, built on this cooperative principle, outperforms Teacher Forcing and obtains state-of-the-art results on two challenging tasks, Summarization and Question Generation.
A Neural Tangent Kernel Perspective of GANs
Jun 10, 2021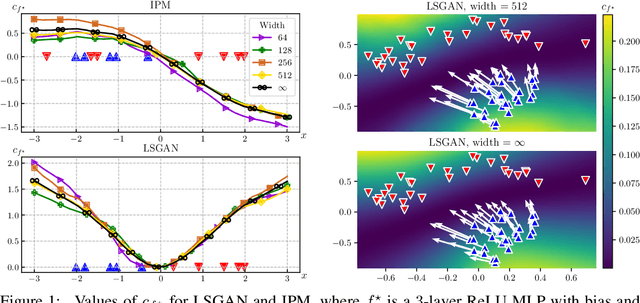

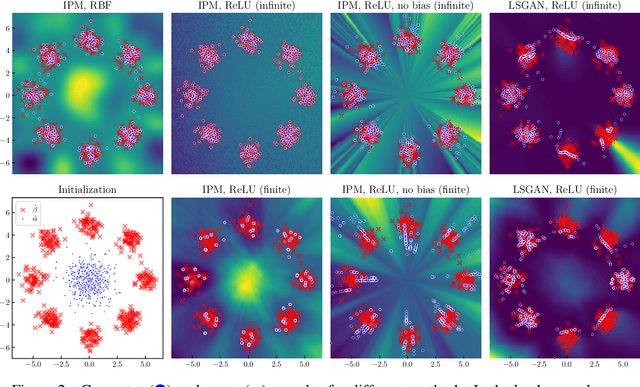

Theoretical analyses for Generative Adversarial Networks (GANs) generally assume an arbitrarily large family of discriminators and do not consider the characteristics of the architectures used in practice. We show that this framework of analysis is too simplistic to properly analyze GAN training. To tackle this issue, we leverage the theory of infinite-width neural networks to model neural discriminator training for a wide range of adversarial losses via its Neural Tangent Kernel (NTK). Our analytical results show that GAN trainability primarily depends on the discriminator's architecture. We further study the discriminator for specific architectures and losses, and highlight properties providing a new understanding of GAN training. For example, we find that GANs trained with the integral probability metric loss minimize the maximum mean discrepancy with the NTK as kernel. Our conclusions demonstrate the analysis opportunities provided by the proposed framework, which paves the way for better and more principled GAN models. We release a generic GAN analysis toolkit based on our framework that supports the empirical part of our study.
Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation
Apr 15, 2021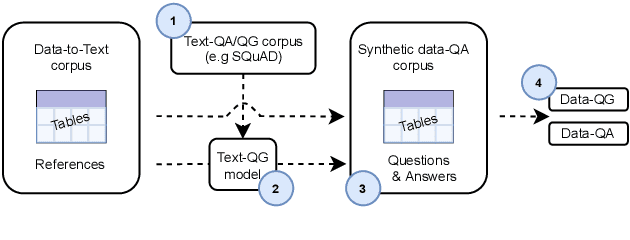
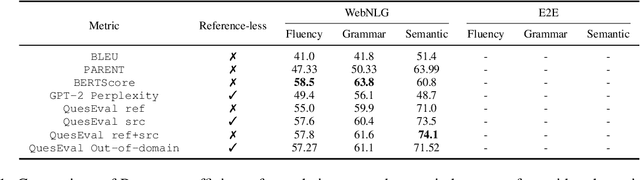

In this paper, we explore how QuestEval, which is a Text-vs-Text metric, can be adapted for the evaluation of Data-to-Text Generation systems. QuestEval is a reference-less metric that compares the predictions directly to the structured input data by automatically asking and answering questions. Its adaptation to Data-to-Text is not straightforward as it requires multi-modal Question Generation and Answering (QG \& QA) systems. To this purpose, we propose to build synthetic multi-modal corpora that enables to train multi-modal QG/QA. The resulting metric is reference-less, multi-modal; it obtains state-of-the-art correlations with human judgement on the E2E and WebNLG benchmark.
QuestEval: Summarization Asks for Fact-based Evaluation
Apr 09, 2021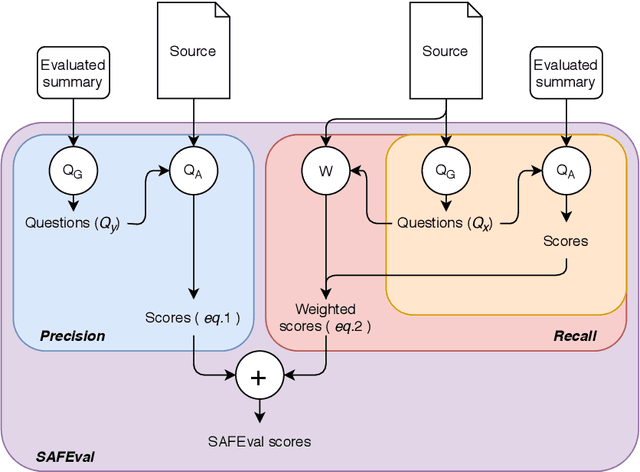
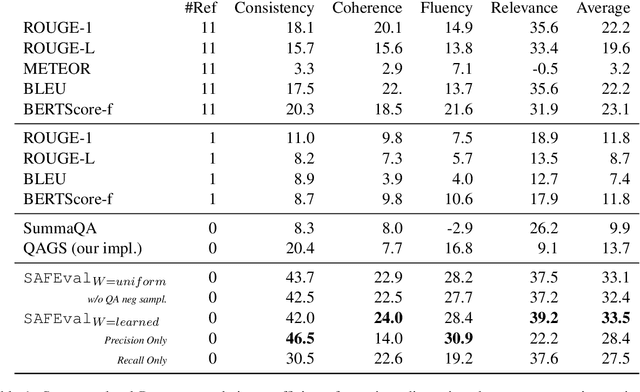

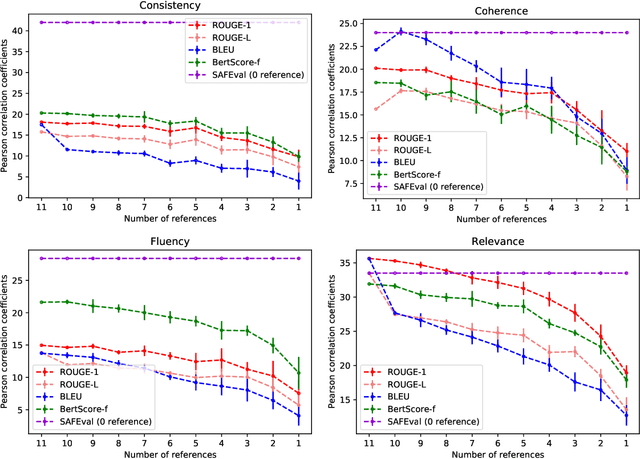
Summarization evaluation remains an open research problem: current metrics such as ROUGE are known to be limited and to correlate poorly with human judgments. To alleviate this issue, recent work has proposed evaluation metrics which rely on question answering models to assess whether a summary contains all the relevant information in its source document. Though promising, the proposed approaches have so far failed to correlate better than ROUGE with human judgments. In this paper, we extend previous approaches and propose a unified framework, named QuestEval. In contrast to established metrics such as ROUGE or BERTScore, QuestEval does not require any ground-truth reference. Nonetheless, QuestEval substantially improves the correlation with human judgments over four evaluation dimensions (consistency, coherence, fluency, and relevance), as shown in the extensive experiments we report.
Improving Robustness of Deep Reinforcement Learning Agents: Environment Attacks based on Critic Networks
Apr 07, 2021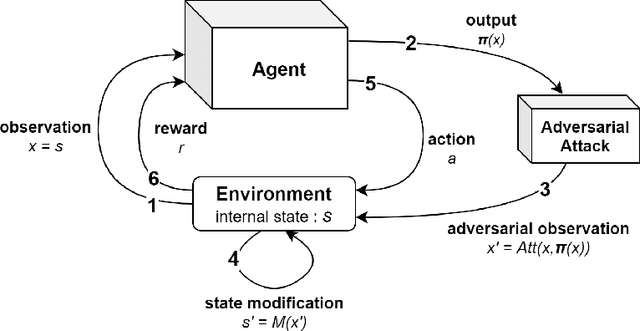
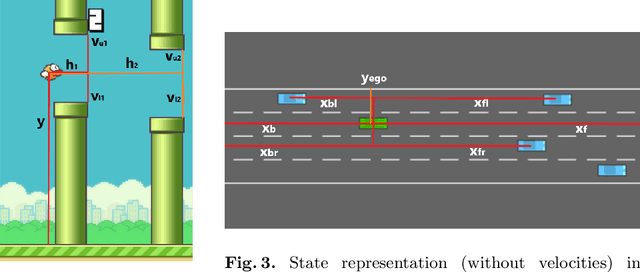
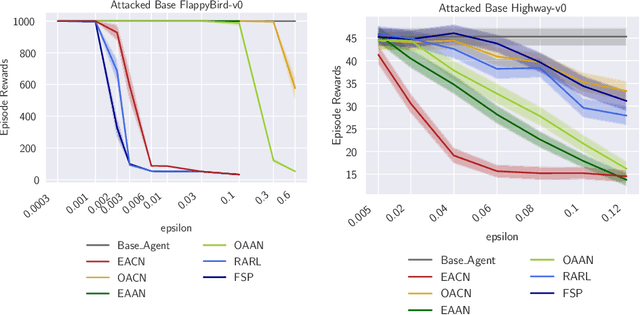
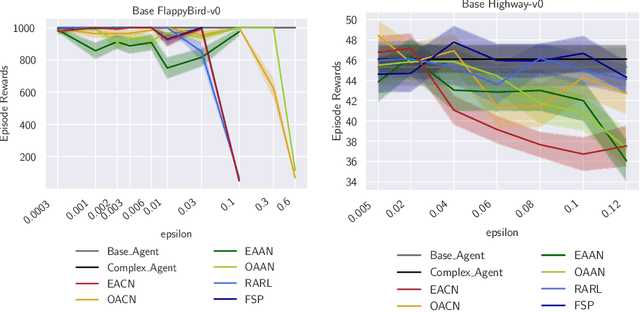
To improve policy robustness of deep reinforcement learning agents, a line of recent works focus on producing disturbances of the environment. Existing approaches of the literature to generate meaningful disturbances of the environment are adversarial reinforcement learning methods. These methods set the problem as a two-player game between the protagonist agent, which learns to perform a task in an environment, and the adversary agent, which learns to disturb the protagonist via modifications of the considered environment. Both protagonist and adversary are trained with deep reinforcement learning algorithms. Alternatively, we propose in this paper to build on gradient-based adversarial attacks, usually used for classification tasks for instance, that we apply on the critic network of the protagonist to identify efficient disturbances of the environment. Rather than learning an attacker policy, which usually reveals as very complex and unstable, we leverage the knowledge of the critic network of the protagonist, to dynamically complexify the task at each step of the learning process. We show that our method, while being faster and lighter, leads to significantly better improvements in policy robustness than existing methods of the literature.
Stochastic sparse adversarial attacks
Nov 24, 2020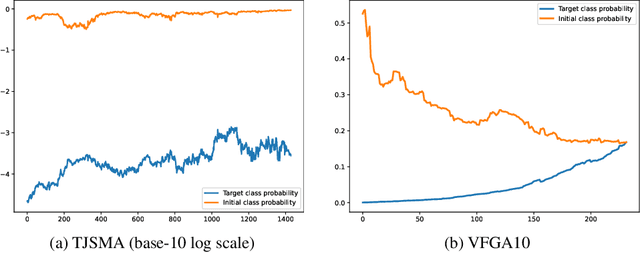
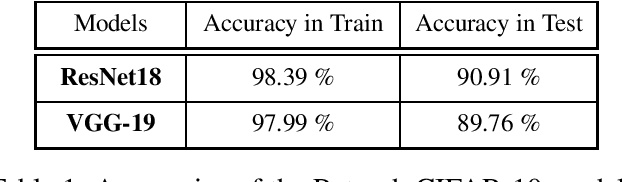
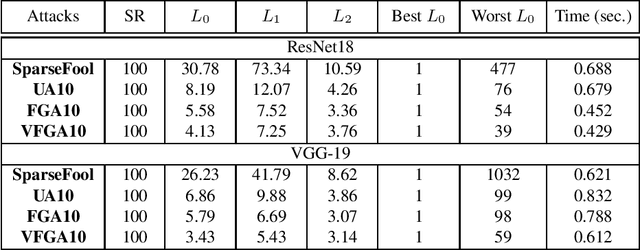

Adversarial attacks of neural network classifiers (NNC) and the use of random noises in these methods have stimulated a large number of works in recent years. However, despite all the previous investigations, existing approaches that rely on random noises to fool NNC have fallen far short of the-state-of-the-art adversarial methods performances. In this paper, we fill this gap by introducing stochastic sparse adversarial attacks (SSAA), standing as simple, fast and purely noise-based targeted and untargeted attacks of NNC. SSAA offer new examples of sparse (or $L_0$) attacks for which only few methods have been proposed previously. These attacks are devised by exploiting a small-time expansion idea widely used for Markov processes. Experiments on small and large datasets (CIFAR-10 and ImageNet) illustrate several advantages of SSAA in comparison with the-state-of-the-art methods. For instance, in the untargeted case, our method called voting folded Gaussian attack (VFGA) scales efficiently to ImageNet and achieves a significantly lower $L_0$ score than SparseFool (up to $\frac{1}{14}$ lower) while being faster. In the targeted setting, VFGA achives appealing results on ImageNet and is significantly much faster than Carlini-Wagner $L_0$ attack.
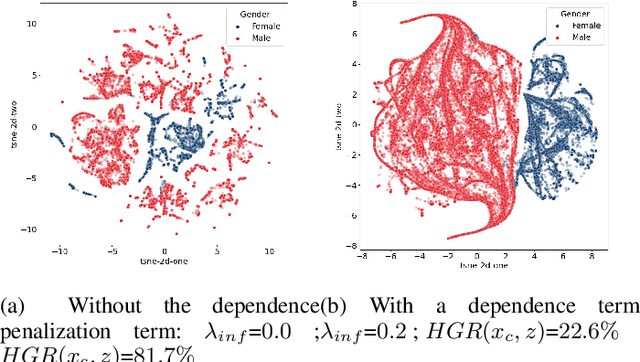
Learning Unbiased Representations via Rényi Minimization
Sep 07, 2020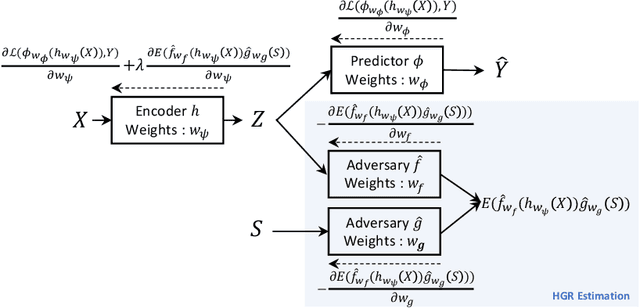

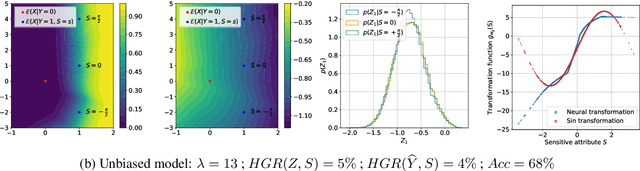
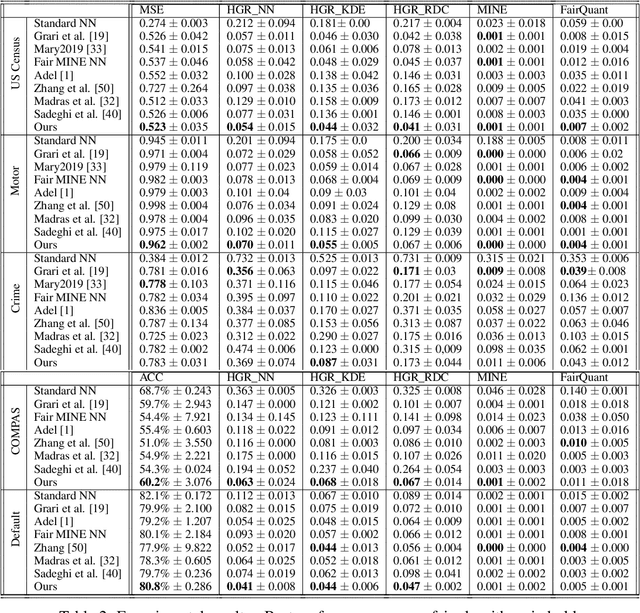
In recent years, significant work has been done to include fairness constraints in the training objective of machine learning algorithms. Many state-of the-art algorithms tackle this challenge by learning a fair representation which captures all the relevant information to predict the output Y while not containing any information about a sensitive attribute S. In this paper, we propose an adversarial algorithm to learn unbiased representations via the Hirschfeld-Gebelein-Renyi (HGR) maximal correlation coefficient. We leverage recent work which has been done to estimate this coefficient by learning deep neural network transformations and use it as a minmax game to penalize the intrinsic bias in a multi dimensional latent representation. Compared to other dependence measures, the HGR coefficient captures more information about the non-linear dependencies with the sensitive variable, making the algorithm more efficient in mitigating bias in the representation. We empirically evaluate and compare our approach and demonstrate significant improvements over existing works in the field.