 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Adversarial Robustness of Adaptive Test-time Defenses
Feb 28, 2022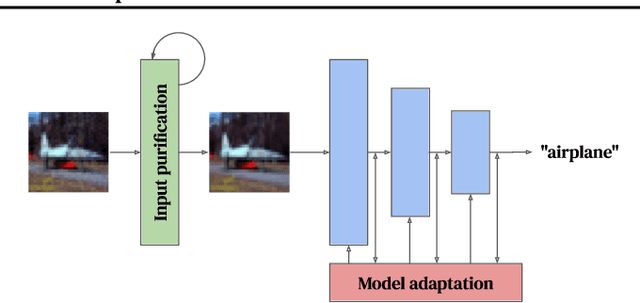



Adaptive defenses that use test-time optimization promise to improve robustness to adversarial examples. We categorize such adaptive test-time defenses and explain their potential benefits and drawbacks. In the process, we evaluate some of the latest proposed adaptive defenses (most of them published at peer-reviewed conferences). Unfortunately, none significantly improve upon static models when evaluated appropriately. Some even weaken the underlying static model while simultaneously increasing inference cost. While these results are disappointing, we still believe that adaptive test-time defenses are a promising avenue of research and, as such, we provide recommendations on evaluating such defenses. We go beyond the checklist provided by Carlini et al. (2019) by providing concrete steps that are specific to this type of defense.
Data Augmentation Can Improve Robustness
Nov 09, 2021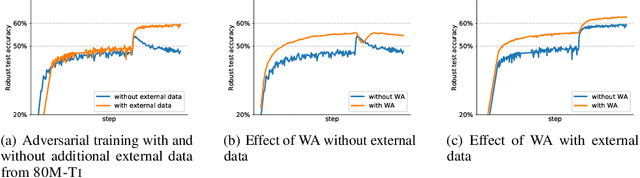
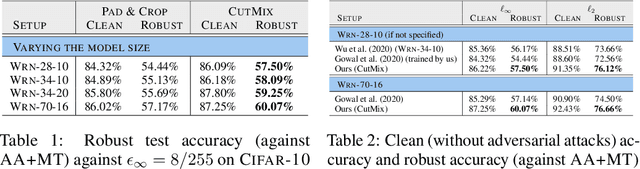
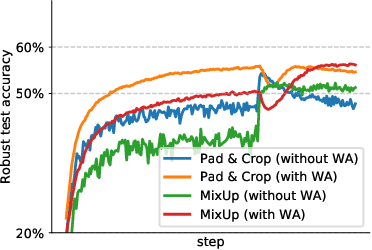
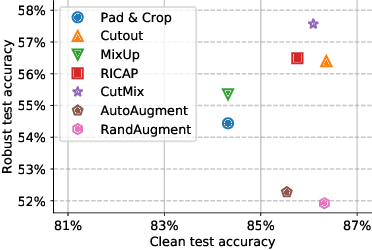
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on reducing robust overfitting by using common data augmentation schemes. We demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Furthermore, we compare various augmentations techniques and observe that spatial composition techniques work the best for adversarial training. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +2.93% and +2.16% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 60.07% robust accuracy without using any external data. We also achieve a significant performance boost with this approach while using other architectures and datasets such as CIFAR-100, SVHN and TinyImageNet.
A Fine-Grained Analysis on Distribution Shift
Oct 21, 2021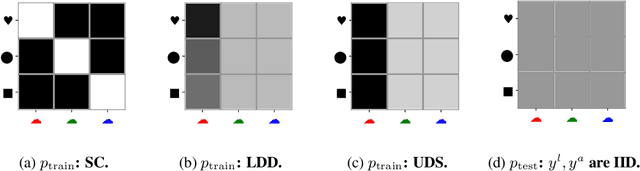

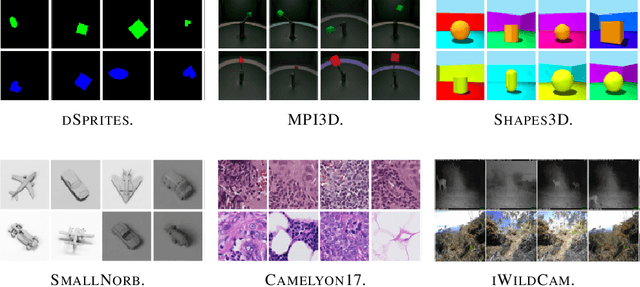

Robustness to distribution shifts is critical for deploying machine learning models in the real world. Despite this necessity, there has been little work in defining the underlying mechanisms that cause these shifts and evaluating the robustness of algorithms across multiple, different distribution shifts. To this end, we introduce a framework that enables fine-grained analysis of various distribution shifts. We provide a holistic analysis of current state-of-the-art methods by evaluating 19 distinct methods grouped into five categories across both synthetic and real-world datasets. Overall, we train more than 85K models. Our experimental framework can be easily extended to include new methods, shifts, and datasets. We find, unlike previous work~\citep{Gulrajani20}, that progress has been made over a standard ERM baseline; in particular, pretraining and augmentations (learned or heuristic) offer large gains in many cases. However, the best methods are not consistent over different datasets and shifts.
Improving Robustness using Generated Data
Oct 18, 2021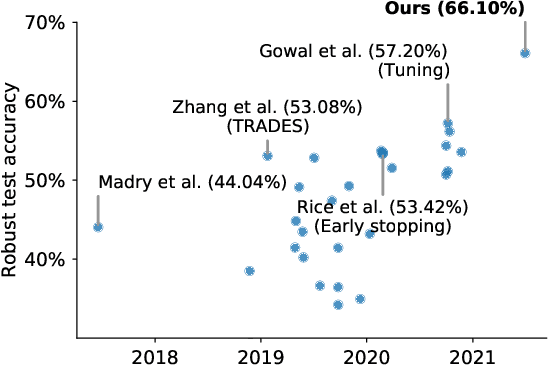
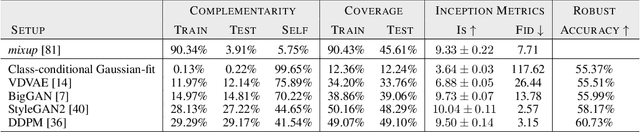
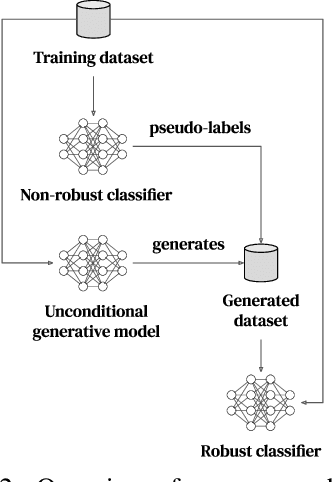
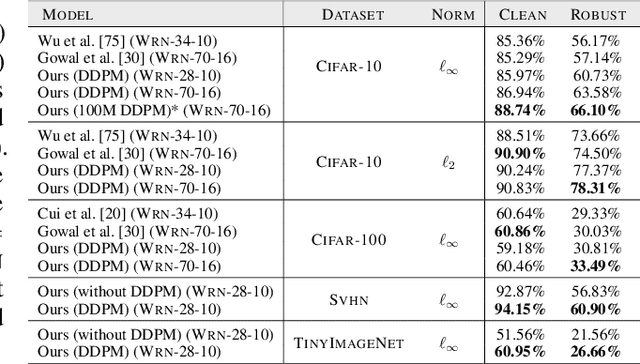
Recent work argues that robust training requires substantially larger datasets than those required for standard classification. On CIFAR-10 and CIFAR-100, this translates into a sizable robust-accuracy gap between models trained solely on data from the original training set and those trained with additional data extracted from the "80 Million Tiny Images" dataset (TI-80M). In this paper, we explore how generative models trained solely on the original training set can be leveraged to artificially increase the size of the original training set and improve adversarial robustness to $\ell_p$ norm-bounded perturbations. We identify the sufficient conditions under which incorporating additional generated data can improve robustness, and demonstrate that it is possible to significantly reduce the robust-accuracy gap to models trained with additional real data. Surprisingly, we even show that even the addition of non-realistic random data (generated by Gaussian sampling) can improve robustness. We evaluate our approach on CIFAR-10, CIFAR-100, SVHN and TinyImageNet against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements in robust accuracy compared to previous state-of-the-art methods. Against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our models achieve 66.10% and 33.49% robust accuracy on CIFAR-10 and CIFAR-100, respectively (improving upon the state-of-the-art by +8.96% and +3.29%). Against $\ell_2$ norm-bounded perturbations of size $\epsilon = 128/255$, our model achieves 78.31% on CIFAR-10 (+3.81%). These results beat most prior works that use external data.
An Empirical Investigation of Learning from Biased Toxicity Labels
Oct 04, 2021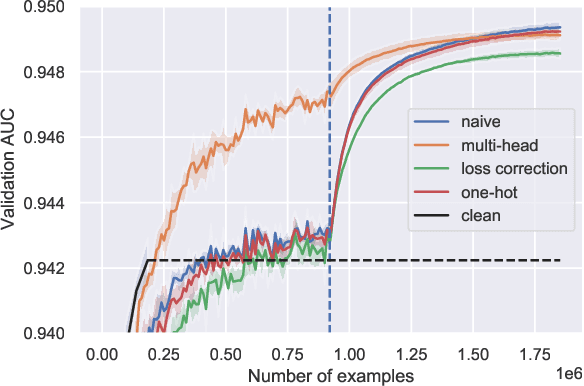


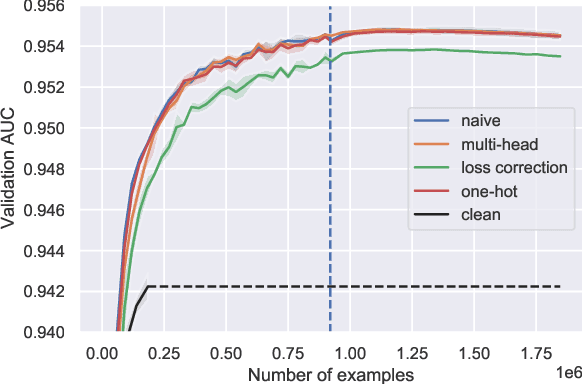
Collecting annotations from human raters often results in a trade-off between the quantity of labels one wishes to gather and the quality of these labels. As such, it is often only possible to gather a small amount of high-quality labels. In this paper, we study how different training strategies can leverage a small dataset of human-annotated labels and a large but noisy dataset of synthetically generated labels (which exhibit bias against identity groups) for predicting toxicity of online comments. We evaluate the accuracy and fairness properties of these approaches, and trade-offs between the two. While we find that initial training on all of the data and fine-tuning on clean data produces models with the highest AUC, we find that no single strategy performs best across all fairness metrics.
A Closer Look at the Adversarial Robustness of Information Bottleneck Models
Jul 12, 2021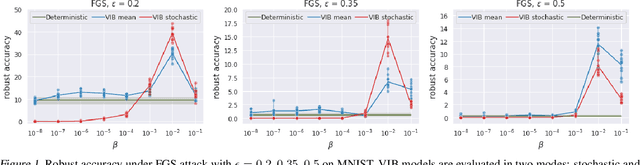
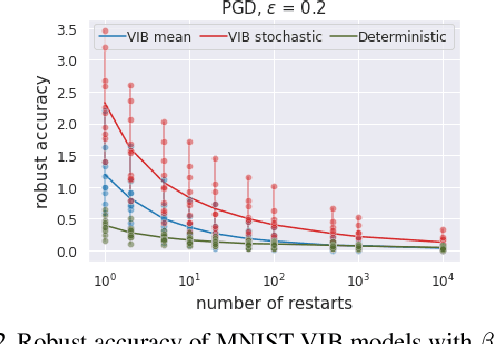
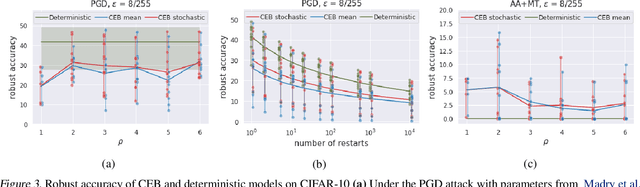
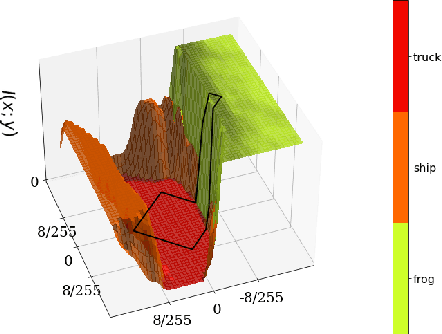
We study the adversarial robustness of information bottleneck models for classification. Previous works showed that the robustness of models trained with information bottlenecks can improve upon adversarial training. Our evaluation under a diverse range of white-box $l_{\infty}$ attacks suggests that information bottlenecks alone are not a strong defense strategy, and that previous results were likely influenced by gradient obfuscation.
Defending Against Image Corruptions Through Adversarial Augmentations
Apr 20, 2021
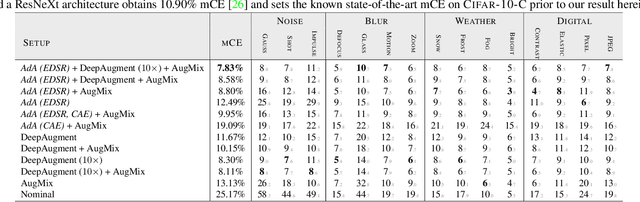
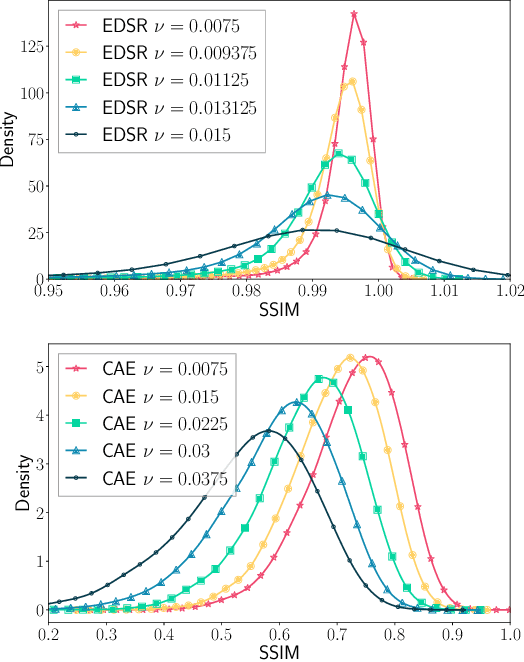
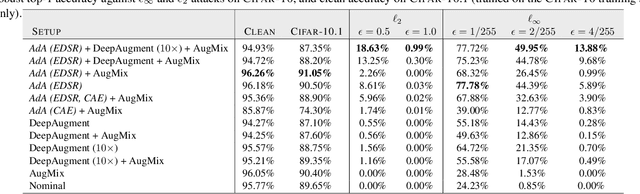
Modern neural networks excel at image classification, yet they remain vulnerable to common image corruptions such as blur, speckle noise or fog. Recent methods that focus on this problem, such as AugMix and DeepAugment, introduce defenses that operate in expectation over a distribution of image corruptions. In contrast, the literature on $\ell_p$-norm bounded perturbations focuses on defenses against worst-case corruptions. In this work, we reconcile both approaches by proposing AdversarialAugment, a technique which optimizes the parameters of image-to-image models to generate adversarially corrupted augmented images. We theoretically motivate our method and give sufficient conditions for the consistency of its idealized version as well as that of DeepAugment. Our classifiers improve upon the state-of-the-art on common image corruption benchmarks conducted in expectation on CIFAR-10-C and improve worst-case performance against $\ell_p$-norm bounded perturbations on both CIFAR-10 and ImageNet.
Fixing Data Augmentation to Improve Adversarial Robustness
Mar 02, 2021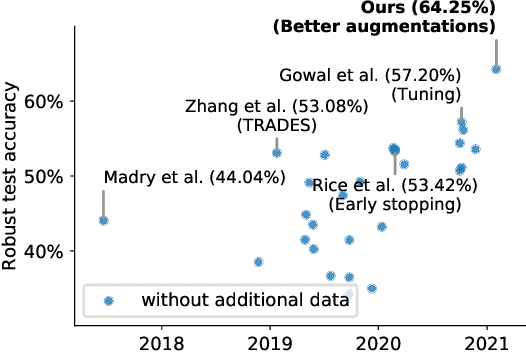
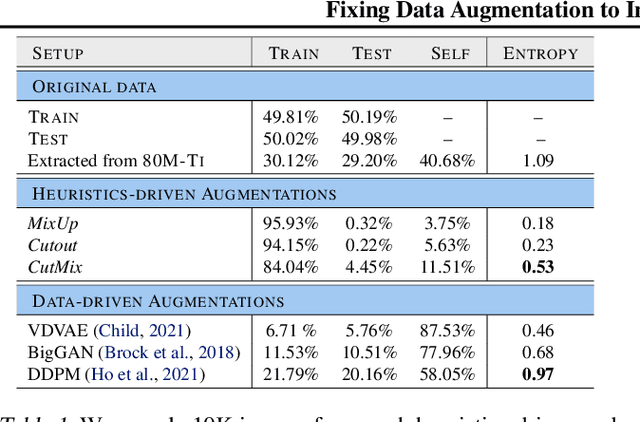
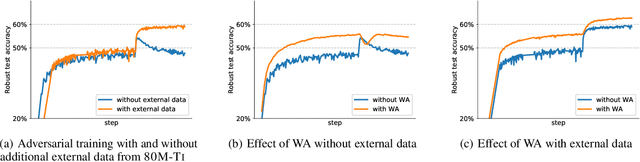
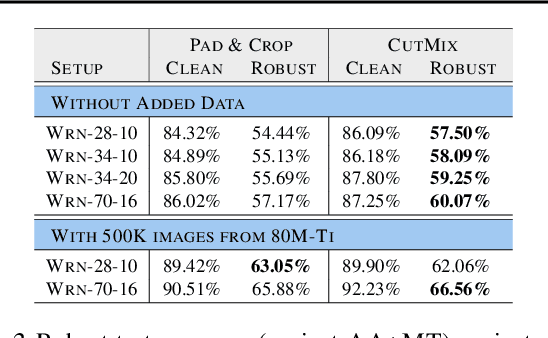
Adversarial training suffers from robust overfitting, a phenomenon where the robust test accuracy starts to decrease during training. In this paper, we focus on both heuristics-driven and data-driven augmentations as a means to reduce robust overfitting. First, we demonstrate that, contrary to previous findings, when combined with model weight averaging, data augmentation can significantly boost robust accuracy. Second, we explore how state-of-the-art generative models can be leveraged to artificially increase the size of the training set and further improve adversarial robustness. Finally, we evaluate our approach on CIFAR-10 against $\ell_\infty$ and $\ell_2$ norm-bounded perturbations of size $\epsilon = 8/255$ and $\epsilon = 128/255$, respectively. We show large absolute improvements of +7.06% and +5.88% in robust accuracy compared to previous state-of-the-art methods. In particular, against $\ell_\infty$ norm-bounded perturbations of size $\epsilon = 8/255$, our model reaches 64.20% robust accuracy without using any external data, beating most prior works that use external data.
Verifying Probabilistic Specifications with Functional Lagrangians
Feb 18, 2021
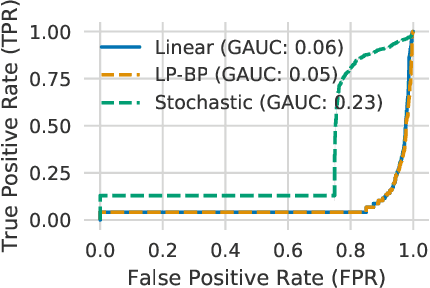
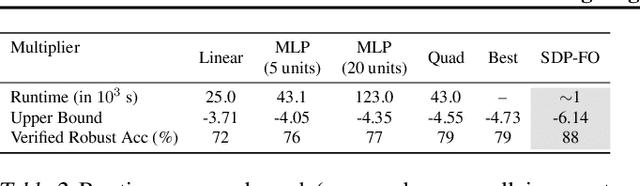

We propose a general framework for verifying input-output specifications of neural networks using functional Lagrange multipliers that generalizes standard Lagrangian duality. We derive theoretical properties of the framework, which can handle arbitrary probabilistic specifications, showing that it provably leads to tight verification when a sufficiently flexible class of functional multipliers is chosen. With a judicious choice of the class of functional multipliers, the framework can accommodate desired trade-offs between tightness and complexity. We demonstrate empirically that the framework can handle a diverse set of networks, including Bayesian neural networks with Gaussian posterior approximations, MC-dropout networks, and verify specifications on adversarial robustness and out-of-distribution(OOD) detection. Our framework improves upon prior work in some settings and also generalizes to new stochastic networks and probabilistic specifications, like distributionally robust OOD detection.
Autoencoding Variational Autoencoder
Dec 07, 2020



Does a Variational AutoEncoder (VAE) consistently encode typical samples generated from its decoder? This paper shows that the perhaps surprising answer to this question is `No'; a (nominally trained) VAE does not necessarily amortize inference for typical samples that it is capable of generating. We study the implications of this behaviour on the learned representations and also the consequences of fixing it by introducing a notion of self consistency. Our approach hinges on an alternative construction of the variational approximation distribution to the true posterior of an extended VAE model with a Markov chain alternating between the encoder and the decoder. The method can be used to train a VAE model from scratch or given an already trained VAE, it can be run as a post processing step in an entirely self supervised way without access to the original training data. Our experimental analysis reveals that encoders trained with our self-consistency approach lead to representations that are robust (insensitive) to perturbations in the input introduced by adversarial attacks. We provide experimental results on the ColorMnist and CelebA benchmark datasets that quantify the properties of the learned representations and compare the approach with a baseline that is specifically trained for the desired property.