 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Average Treatment Effects in Nonparametric Panel Models
Mar 25, 2025This paper studies identification of average treatment effects in a panel data setting. It introduces a novel nonparametric factor model and proves identification of average treatment effects. The identification proof is based on the introduction of a consistent estimator. Underlying the proof is a result that there is a consistent estimator for the expected outcome in the absence of the treatment for each unit and time period; this result can be applied more broadly, for example in problems of decompositions of group-level differences in outcomes, such as the much-studied gender wage gap.
Robust Offline Policy Learning with Observational Data from Multiple Sources
Oct 11, 2024

We consider the problem of using observational bandit feedback data from multiple heterogeneous data sources to learn a personalized decision policy that robustly generalizes across diverse target settings. To achieve this, we propose a minimax regret optimization objective to ensure uniformly low regret under general mixtures of the source distributions. We develop a policy learning algorithm tailored to this objective, combining doubly robust offline policy evaluation techniques and no-regret learning algorithms for minimax optimization. Our regret analysis shows that this approach achieves the minimal worst-case mixture regret up to a moderated vanishing rate of the total data across all sources. Our analysis, extensions, and experimental results demonstrate the benefits of this approach for learning robust decision policies from multiple data sources.
Estimating Wage Disparities Using Foundation Models
Sep 15, 2024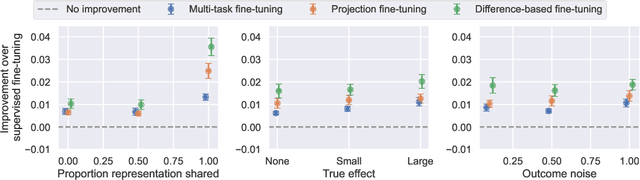
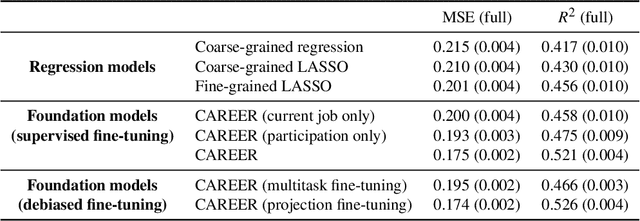
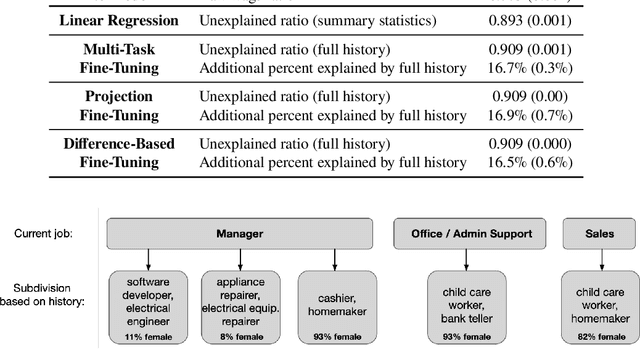
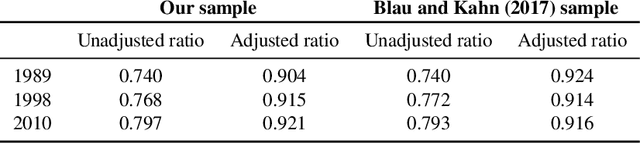
One thread of empirical work in social science focuses on decomposing group differences in outcomes into unexplained components and components explained by observable factors. In this paper, we study gender wage decompositions, which require estimating the portion of the gender wage gap explained by career histories of workers. Classical methods for decomposing the wage gap employ simple predictive models of wages which condition on a small set of simple summaries of labor history. The problem is that these predictive models cannot take advantage of the full complexity of a worker's history, and the resulting decompositions thus suffer from omitted variable bias (OVB), where covariates that are correlated with both gender and wages are not included in the model. Here we explore an alternative methodology for wage gap decomposition that employs powerful foundation models, such as large language models, as the predictive engine. Foundation models excel at making accurate predictions from complex, high-dimensional inputs. We use a custom-built foundation model, designed to predict wages from full labor histories, to decompose the gender wage gap. We prove that the way such models are usually trained might still lead to OVB, but develop fine-tuning algorithms that empirically mitigate this issue. Our model captures a richer representation of career history than simple models and predicts wages more accurately. In detail, we first provide a novel set of conditions under which an estimator of the wage gap based on a fine-tuned foundation model is $\sqrt{n}$-consistent. Building on the theory, we then propose methods for fine-tuning foundation models that minimize OVB. Using data from the Panel Study of Income Dynamics, we find that history explains more of the gender wage gap than standard econometric models can measure, and we identify elements of history that are important for reducing OVB.
LABOR-LLM: Language-Based Occupational Representations with Large Language Models
Jun 25, 2024Many empirical studies of labor market questions rely on estimating relatively simple predictive models using small, carefully constructed longitudinal survey datasets based on hand-engineered features. Large Language Models (LLMs), trained on massive datasets, encode vast quantities of world knowledge and can be used for the next job prediction problem. However, while an off-the-shelf LLM produces plausible career trajectories when prompted, the probability with which an LLM predicts a particular job transition conditional on career history will not, in general, align with the true conditional probability in a given population. Recently, Vafa et al. (2024) introduced a transformer-based "foundation model", CAREER, trained using a large, unrepresentative resume dataset, that predicts transitions between jobs; it further demonstrated how transfer learning techniques can be used to leverage the foundation model to build better predictive models of both transitions and wages that reflect conditional transition probabilities found in nationally representative survey datasets. This paper considers an alternative where the fine-tuning of the CAREER foundation model is replaced by fine-tuning LLMs. For the task of next job prediction, we demonstrate that models trained with our approach outperform several alternatives in terms of predictive performance on the survey data, including traditional econometric models, CAREER, and LLMs with in-context learning, even though the LLM can in principle predict job titles that are not allowed in the survey data. Further, we show that our fine-tuned LLM-based models' predictions are more representative of the career trajectories of various workforce subpopulations than off-the-shelf LLM models and CAREER. We conduct experiments and analyses that highlight the sources of the gains in the performance of our models for representative predictions.
Data-driven Error Estimation: Upper Bounding Multiple Errors with No Technical Debt
May 07, 2024We formulate the problem of constructing multiple simultaneously valid confidence intervals (CIs) as estimating a high probability upper bound on the maximum error for a class/set of estimate-estimand-error tuples, and refer to this as the error estimation problem. For a single such tuple, data-driven confidence intervals can often be used to bound the error in our estimate. However, for a class of estimate-estimand-error tuples, nontrivial high probability upper bounds on the maximum error often require class complexity as input -- limiting the practicality of such methods and often resulting in loose bounds. Rather than deriving theoretical class complexity-based bounds, we propose a completely data-driven approach to estimate an upper bound on the maximum error. The simple and general nature of our solution to this fundamental challenge lends itself to several applications including: multiple CI construction, multiple hypothesis testing, estimating excess risk bounds (a fundamental measure of uncertainty in machine learning) for any training/fine-tuning algorithm, and enabling the development of a contextual bandit pipeline that can leverage any reward model estimation procedure as input (without additional mathematical analysis).
Machine Learning Who to Nudge: Causal vs Predictive Targeting in a Field Experiment on Student Financial Aid Renewal
Oct 12, 2023



In many settings, interventions may be more effective for some individuals than others, so that targeting interventions may be beneficial. We analyze the value of targeting in the context of a large-scale field experiment with over 53,000 college students, where the goal was to use "nudges" to encourage students to renew their financial-aid applications before a non-binding deadline. We begin with baseline approaches to targeting. First, we target based on a causal forest that estimates heterogeneous treatment effects and then assigns students to treatment according to those estimated to have the highest treatment effects. Next, we evaluate two alternative targeting policies, one targeting students with low predicted probability of renewing financial aid in the absence of the treatment, the other targeting those with high probability. The predicted baseline outcome is not the ideal criterion for targeting, nor is it a priori clear whether to prioritize low, high, or intermediate predicted probability. Nonetheless, targeting on low baseline outcomes is common in practice, for example because the relationship between individual characteristics and treatment effects is often difficult or impossible to estimate with historical data. We propose hybrid approaches that incorporate the strengths of both predictive approaches (accurate estimation) and causal approaches (correct criterion); we show that targeting intermediate baseline outcomes is most effective, while targeting based on low baseline outcomes is detrimental. In one year of the experiment, nudging all students improved early filing by an average of 6.4 percentage points over a baseline average of 37% filing, and we estimate that targeting half of the students using our preferred policy attains around 75% of this benefit.
Proportional Response: Contextual Bandits for Simple and Cumulative Regret Minimization
Jul 05, 2023
Simple regret minimization is a critical problem in learning optimal treatment assignment policies across various domains, including healthcare and e-commerce. However, it remains understudied in the contextual bandit setting. We propose a new family of computationally efficient bandit algorithms for the stochastic contextual bandit settings, with the flexibility to be adapted for cumulative regret minimization (with near-optimal minimax guarantees) and simple regret minimization (with SOTA guarantees). Furthermore, our algorithms adapt to model misspecification and extend to the continuous arm settings. These advantages come from constructing and relying on "conformal arm sets" (CASs), which provide a set of arms at every context that encompass the context-specific optimal arm with some probability across the context distribution. Our positive results on simple and cumulative regret guarantees are contrasted by a negative result, which shows that an algorithm can't achieve instance-dependent simple regret guarantees while simultaneously achieving minimax optimal cumulative regret guarantees.
Federated Offline Policy Learning with Heterogeneous Observational Data
May 21, 2023


We consider the problem of learning personalized decision policies on observational data from heterogeneous data sources. Moreover, we examine this problem in the federated setting where a central server aims to learn a policy on the data distributed across the heterogeneous sources without exchanging their raw data. We present a federated policy learning algorithm based on aggregation of local policies trained with doubly robust offline policy evaluation and learning strategies. We provide a novel regret analysis for our approach that establishes a finite-sample upper bound on a notion of global regret across a distribution of clients. In addition, for any individual client, we establish a corresponding local regret upper bound characterized by the presence of distribution shift relative to all other clients. We support our theoretical findings with experimental results. Our analysis and experiments provide insights into the value of heterogeneous client participation in federation for policy learning in heterogeneous settings.
Torch-Choice: A PyTorch Package for Large-Scale Choice Modelling with Python
Apr 04, 2023



The $\texttt{torch-choice}$ is an open-source library for flexible, fast choice modeling with Python and PyTorch. $\texttt{torch-choice}$ provides a $\texttt{ChoiceDataset}$ data structure to manage databases flexibly and memory-efficiently. The paper demonstrates constructing a $\texttt{ChoiceDataset}$ from databases of various formats and functionalities of $\texttt{ChoiceDataset}$. The package implements two widely used models, namely the multinomial logit and nested logit models, and supports regularization during model estimation. The package incorporates the option to take advantage of GPUs for estimation, allowing it to scale to massive datasets while being computationally efficient. Models can be initialized using either R-style formula strings or Python dictionaries. We conclude with a comparison of the computational efficiencies of $\texttt{torch-choice}$ and $\texttt{mlogit}$ in R as (1) the number of observations increases, (2) the number of covariates increases, and (3) the expansion of item sets. Finally, we demonstrate the scalability of $\texttt{torch-choice}$ on large-scale datasets.
Contextual Bandits in a Survey Experiment on Charitable Giving: Within-Experiment Outcomes versus Policy Learning
Nov 22, 2022We design and implement an adaptive experiment (a ``contextual bandit'') to learn a targeted treatment assignment policy, where the goal is to use a participant's survey responses to determine which charity to expose them to in a donation solicitation. The design balances two competing objectives: optimizing the outcomes for the subjects in the experiment (``cumulative regret minimization'') and gathering data that will be most useful for policy learning, that is, for learning an assignment rule that will maximize welfare if used after the experiment (``simple regret minimization''). We evaluate alternative experimental designs by collecting pilot data and then conducting a simulation study. Next, we implement our selected algorithm. Finally, we perform a second simulation study anchored to the collected data that evaluates the benefits of the algorithm we chose. Our first result is that the value of a learned policy in this setting is higher when data is collected via a uniform randomization rather than collected adaptively using standard cumulative regret minimization or policy learning algorithms. We propose a simple heuristic for adaptive experimentation that improves upon uniform randomization from the perspective of policy learning at the expense of increasing cumulative regret relative to alternative bandit algorithms. The heuristic modifies an existing contextual bandit algorithm by (i) imposing a lower bound on assignment probabilities that decay slowly so that no arm is discarded too quickly, and (ii) after adaptively collecting data, restricting policy learning to select from arms where sufficient data has been gathered.