 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization Needs Stochastic Weight Averaging for Robustness on Domain Shifts
Feb 17, 2021
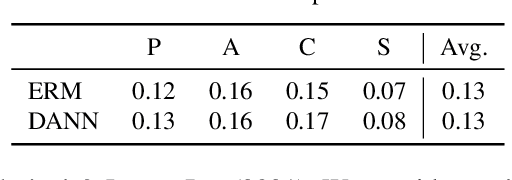
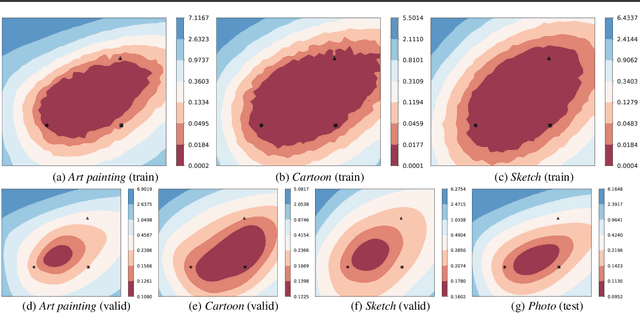
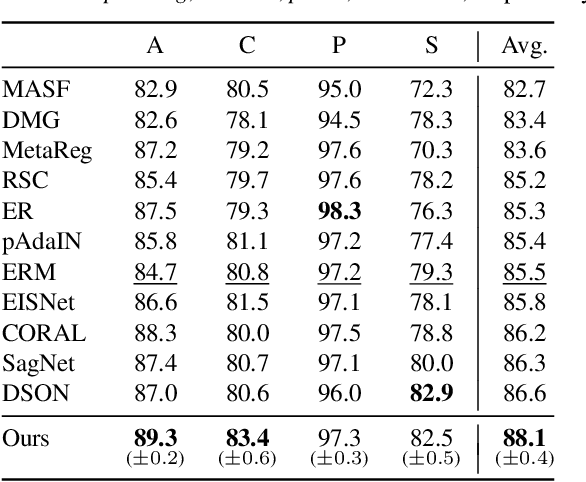
Domain generalization aims to learn a generalizable model to unseen target domains from multiple source domains. Various approaches have been proposed to address this problem. However, recent benchmarks show that most of them do not provide significant improvements compared to the simple empirical risk minimization (ERM) in practical cases. In this paper, we analyze how ERM works in views of domain-invariant feature learning and domain-specific gradient normalization. In addition, we observe that ERM converges to a loss valley shared over multiple training domains and obtain an insight that a center of the valley generalizes better. To estimate the center, we employ stochastic weight averaging (SWA) and provide theoretical analysis describing how SWA supports the generalization bound for an unseen domain. As a result, we achieve state-of-the-art performances over all of widely used domain generalization benchmarks, namely PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet with large margins. Further analysis reveals how SWA operates on domain generalization tasks.
Show, Attend and Distill:Knowledge Distillation via Attention-based Feature Matching
Feb 05, 2021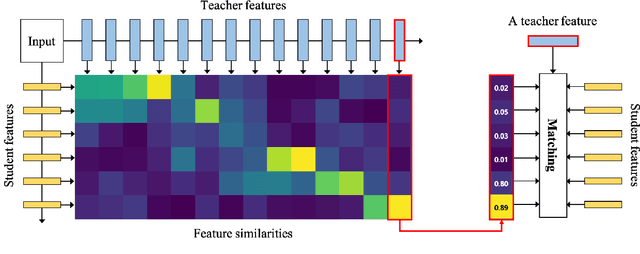
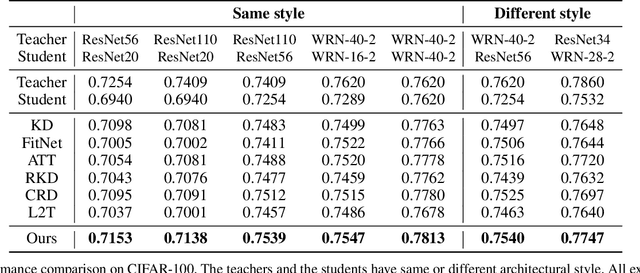
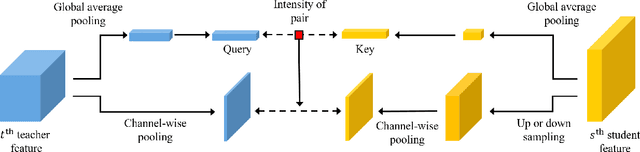
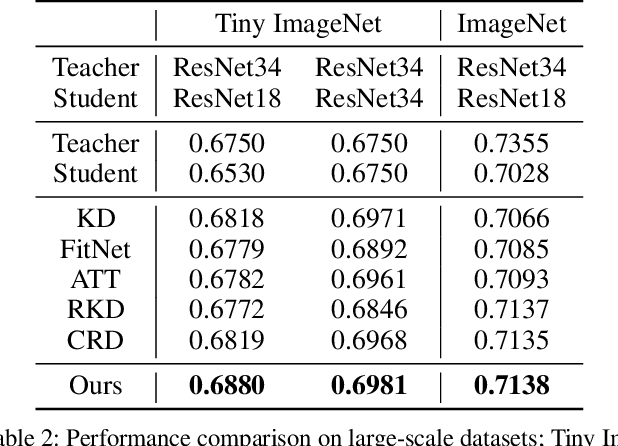
Knowledge distillation extracts general knowledge from a pre-trained teacher network and provides guidance to a target student network. Most studies manually tie intermediate features of the teacher and student, and transfer knowledge through pre-defined links. However, manual selection often constructs ineffective links that limit the improvement from the distillation. There has been an attempt to address the problem, but it is still challenging to identify effective links under practical scenarios. In this paper, we introduce an effective and efficient feature distillation method utilizing all the feature levels of the teacher without manually selecting the links. Specifically, our method utilizes an attention-based meta-network that learns relative similarities between features, and applies identified similarities to control distillation intensities of all possible pairs. As a result, our method determines competent links more efficiently than the previous approach and provides better performance on model compression and transfer learning tasks. Further qualitative analyses and ablative studies describe how our method contributes to better distillation. The implementation code is available at github.com/clovaai/attention-feature-distillation.
Character Region Attention For Text Spotting
Jul 19, 2020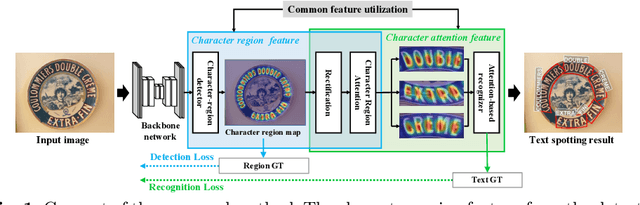
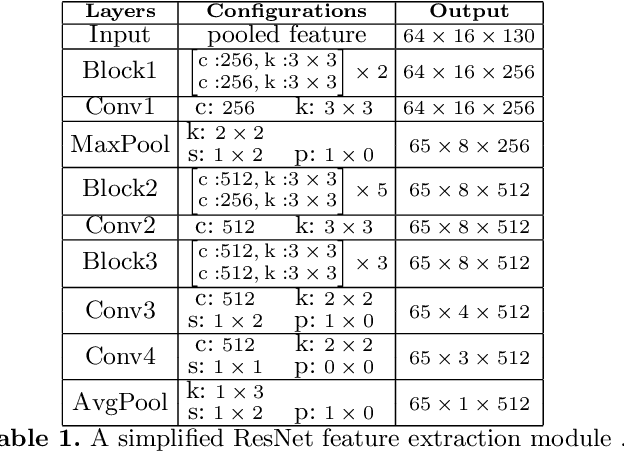
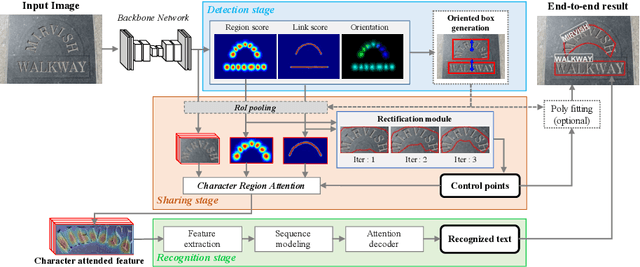
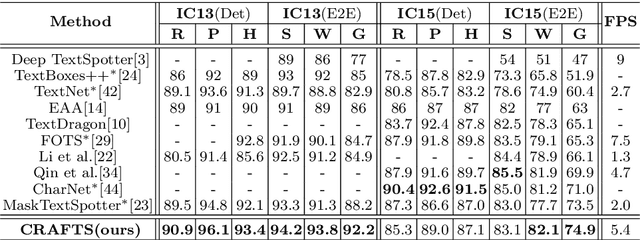
A scene text spotter is composed of text detection and recognition modules. Many studies have been conducted to unify these modules into an end-to-end trainable model to achieve better performance. A typical architecture places detection and recognition modules into separate branches, and a RoI pooling is commonly used to let the branches share a visual feature. However, there still exists a chance of establishing a more complimentary connection between the modules when adopting recognizer that uses attention-based decoder and detector that represents spatial information of the character regions. This is possible since the two modules share a common sub-task which is to find the location of the character regions. Based on the insight, we construct a tightly coupled single pipeline model. This architecture is formed by utilizing detection outputs in the recognizer and propagating the recognition loss through the detection stage. The use of character score map helps the recognizer attend better to the character center points, and the recognition loss propagation to the detector module enhances the localization of the character regions. Also, a strengthened sharing stage allows feature rectification and boundary localization of arbitrary-shaped text regions. Extensive experiments demonstrate state-of-the-art performance in publicly available straight and curved benchmark dataset.
CLEval: Character-Level Evaluation for Text Detection and Recognition Tasks
Jun 11, 2020
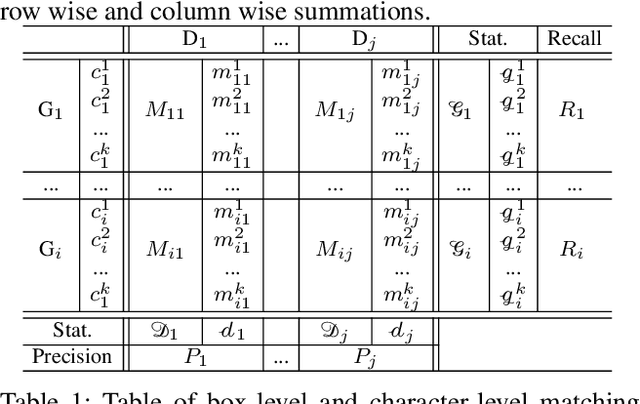


Despite the recent success of text detection and recognition methods, existing evaluation metrics fail to provide a fair and reliable comparison among those methods. In addition, there exists no end-to-end evaluation metric that takes characteristics of OCR tasks into account. Previous end-to-end metric contains cascaded errors from the binary scoring process applied in both detection and recognition tasks. Ignoring partially correct results raises a gap between quantitative and qualitative analysis, and prevents fine-grained assessment. Based on the fact that character is a key element of text, we hereby propose a Character-Level Evaluation metric (CLEval). In CLEval, the \textit{instance matching} process handles split and merge detection cases, and the \textit{scoring process} conducts character-level evaluation. By aggregating character-level scores, the CLEval metric provides a fine-grained evaluation of end-to-end results composed of the detection and recognition as well as individual evaluations for each module from the end-performance perspective. We believe that our metrics can play a key role in developing and analyzing state-of-the-art text detection and recognition methods. The evaluation code is publicly available at https://github.com/clovaai/CLEval.
On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
Oct 10, 2019
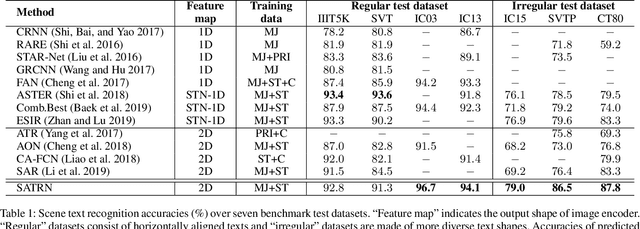
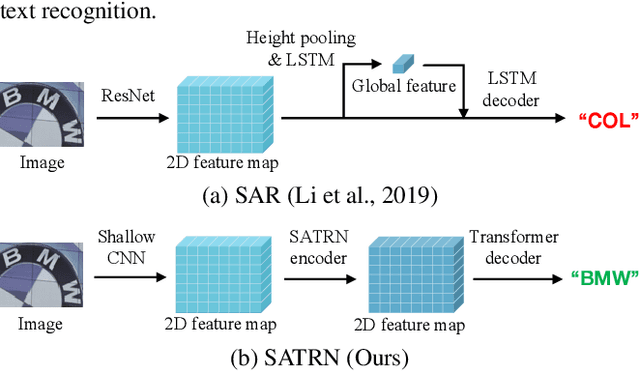
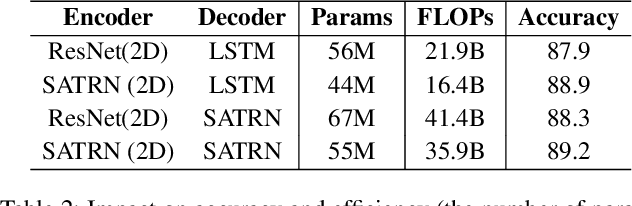
Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in "irregular text" benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
Hierarchical Context enabled Recurrent Neural Network for Recommendation
Apr 26, 2019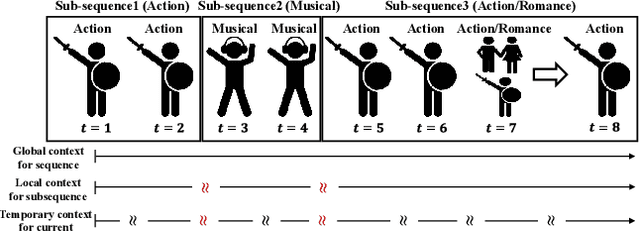
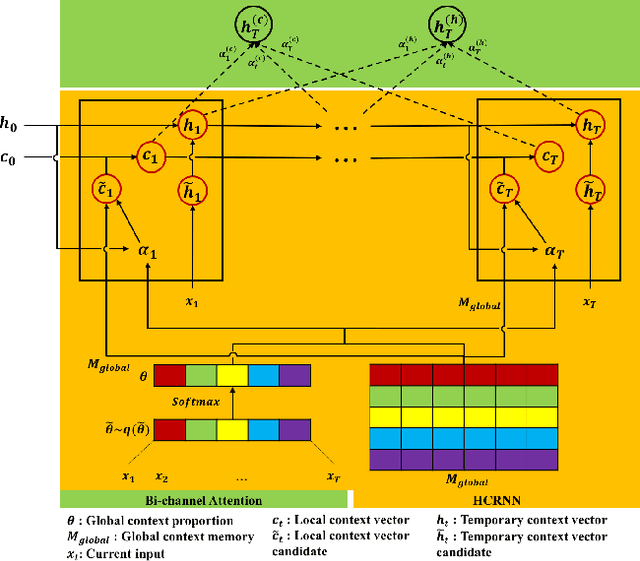
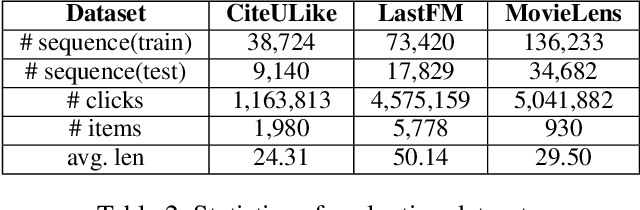
A long user history inevitably reflects the transitions of personal interests over time. The analyses on the user history require the robust sequential model to anticipate the transitions and the decays of user interests. The user history is often modeled by various RNN structures, but the RNN structures in the recommendation system still suffer from the long-term dependency and the interest drifts. To resolve these challenges, we suggest HCRNN with three hierarchical contexts of the global, the local, and the temporary interests. This structure is designed to withhold the global long-term interest of users, to reflect the local sub-sequence interests, and to attend the temporary interests of each transition. Besides, we propose a hierarchical context-based gate structure to incorporate our \textit{interest drift assumption}. As we suggest a new RNN structure, we support HCRNN with a complementary \textit{bi-channel attention} structure to utilize hierarchical context. We experimented the suggested structure on the sequential recommendation tasks with CiteULike, MovieLens, and LastFM, and our model showed the best performances in the sequential recommendations.
Adversarial Dropout for Recurrent Neural Networks
Apr 22, 2019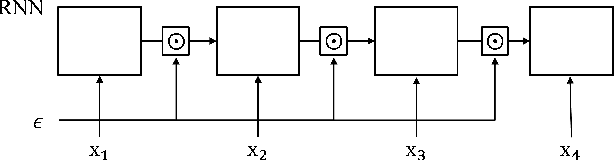

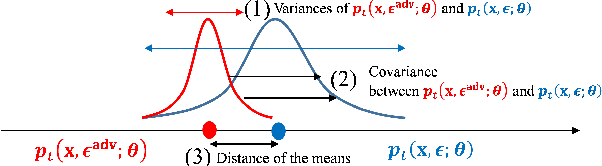
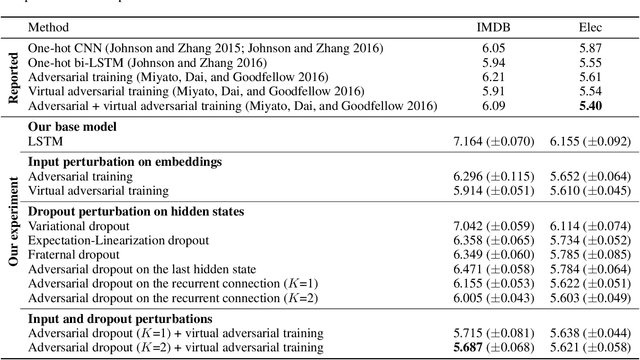
Successful application processing sequential data, such as text and speech, requires an improved generalization performance of recurrent neural networks (RNNs). Dropout techniques for RNNs were introduced to respond to these demands, but we conjecture that the dropout on RNNs could have been improved by adopting the adversarial concept. This paper investigates ways to improve the dropout for RNNs by utilizing intentionally generated dropout masks. Specifically, the guided dropout used in this research is called as adversarial dropout, which adversarially disconnects neurons that are dominantly used to predict correct targets over time. Our analysis showed that our regularizer, which consists of a gap between the original and the reconfigured RNNs, was the upper bound of the gap between the training and the inference phases of the random dropout. We demonstrated that minimizing our regularizer improved the effectiveness of the dropout for RNNs on sequential MNIST tasks, semi-supervised text classification tasks, and language modeling tasks.
What is wrong with scene text recognition model comparisons? dataset and model analysis
Apr 03, 2019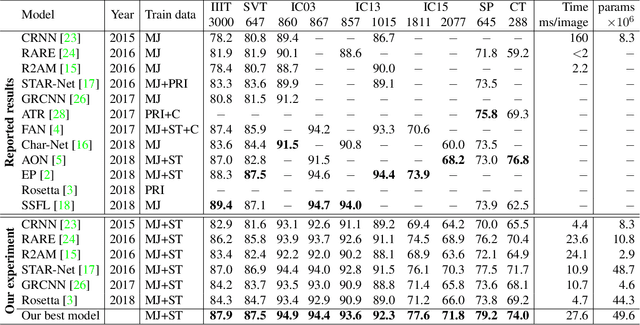



Many new proposals for scene text recognition (STR) models have been introduced in recent years. While each claim to have pushed the boundary of the technology, a holistic and fair comparison has been largely missing in the field due to the inconsistent choices of training and evaluation datasets. This paper addresses this difficulty with three major contributions. First, we examine the inconsistencies of training and evaluation datasets, and the performance gap results from inconsistencies. Second, we introduce a unified four-stage STR framework that most existing STR models fit into. Using this framework allows for the extensive evaluation of previously proposed STR modules and the discovery of previously unexplored module combinations. Third, we analyze the module-wise contributions to performance in terms of accuracy, speed, and memory demand, under one consistent set of training and evaluation datasets. Such analyses clean up the hindrance on the current comparisons to understand the performance gain of the existing modules.
Dirichlet Variational Autoencoder
Jan 09, 2019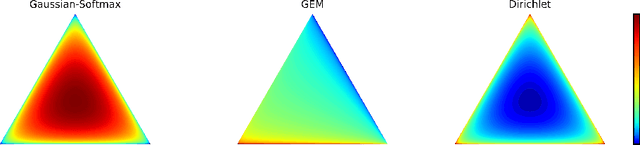
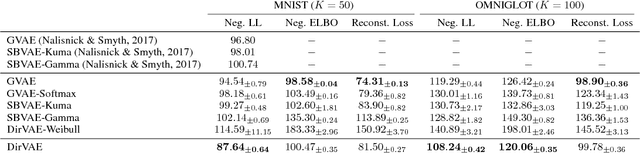
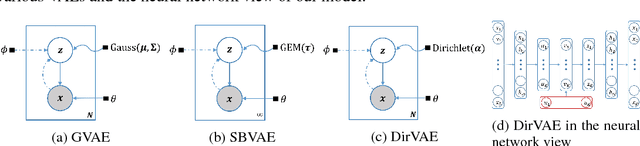

This paper proposes Dirichlet Variational Autoencoder (DirVAE) using a Dirichlet prior for a continuous latent variable that exhibits the characteristic of the categorical probabilities. To infer the parameters of DirVAE, we utilize the stochastic gradient method by approximating the Gamma distribution, which is a component of the Dirichlet distribution, with the inverse Gamma CDF approximation. Additionally, we reshape the component collapsing issue by investigating two problem sources, which are decoder weight collapsing and latent value collapsing, and we show that DirVAE has no component collapsing; while Gaussian VAE exhibits the decoder weight collapsing and Stick-Breaking VAE shows the latent value collapsing. The experimental results show that 1) DirVAE models the latent representation result with the best log-likelihood compared to the baselines; and 2) DirVAE produces more interpretable latent values with no collapsing issues which the baseline models suffer from. Also, we show that the learned latent representation from the DirVAE achieves the best classification accuracy in the semi-supervised and the supervised classification tasks on MNIST, OMNIGLOT, and SVHN compared to the baseline VAEs. Finally, we demonstrated that the DirVAE augmented topic models show better performances in most cases.
Adversarial Dropout for Supervised and Semi-supervised Learning
Sep 18, 2017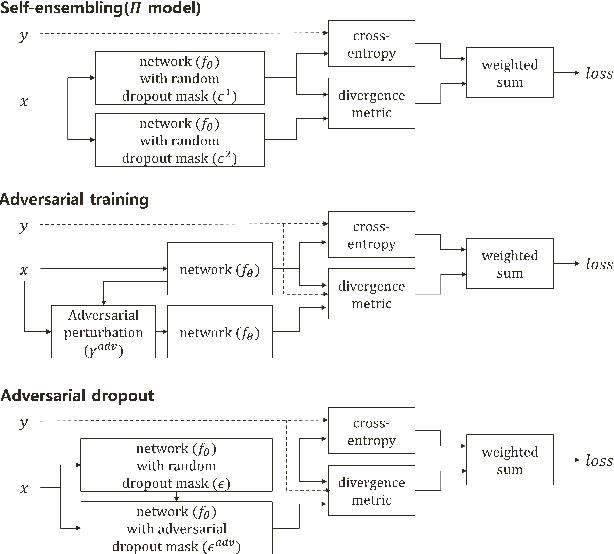
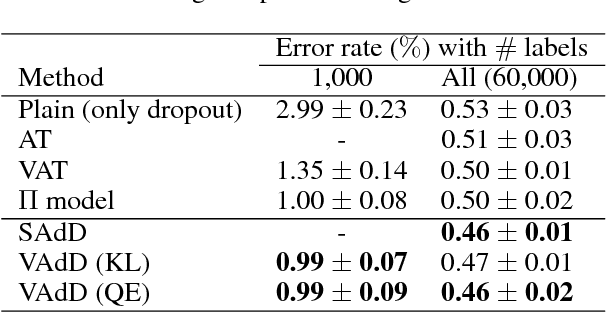
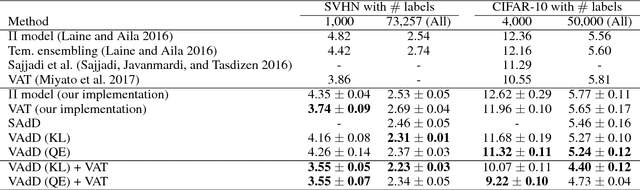

Recently, the training with adversarial examples, which are generated by adding a small but worst-case perturbation on input examples, has been proved to improve generalization performance of neural networks. In contrast to the individually biased inputs to enhance the generality, this paper introduces adversarial dropout, which is a minimal set of dropouts that maximize the divergence between the outputs from the network with the dropouts and the training supervisions. The identified adversarial dropout are used to reconfigure the neural network to train, and we demonstrated that training on the reconfigured sub-network improves the generalization performance of supervised and semi-supervised learning tasks on MNIST and CIFAR-10. We analyzed the trained model to reason the performance improvement, and we found that adversarial dropout increases the sparsity of neural networks more than the standard dropout does.