 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Clustered Representation Learning
Jan 28, 2019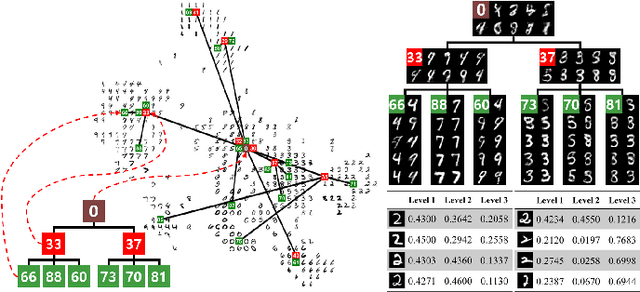
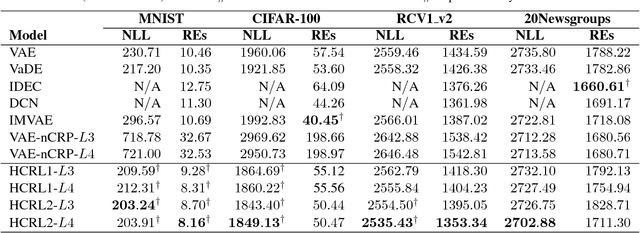

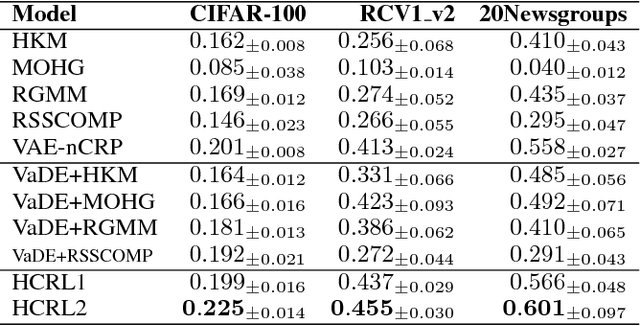
The joint optimization of representation learning and clustering in the embedding space has experienced a breakthrough in recent years. In spite of the advance, clustering with representation learning has been limited to flat-level categories, which often involves cohesive clustering with a focus on instance relations. To overcome the limitations of flat clustering, we introduce hierarchically-clustered representation learning (HCRL), which simultaneously optimizes representation learning and hierarchical clustering in the embedding space. Compared with a few prior works, HCRL firstly attempts to consider a generation of deep embeddings from every component of the hierarchy, not just leaf components. In addition to obtaining hierarchically clustered embeddings, we can reconstruct data by the various abstraction levels, infer the intrinsic hierarchical structure, and learn the level-proportion features. We conducted evaluations with image and text domains, and our quantitative analyses showed competent likelihoods and the best accuracies compared with the baselines.
Adversarial Dropout for Supervised and Semi-supervised Learning
Sep 18, 2017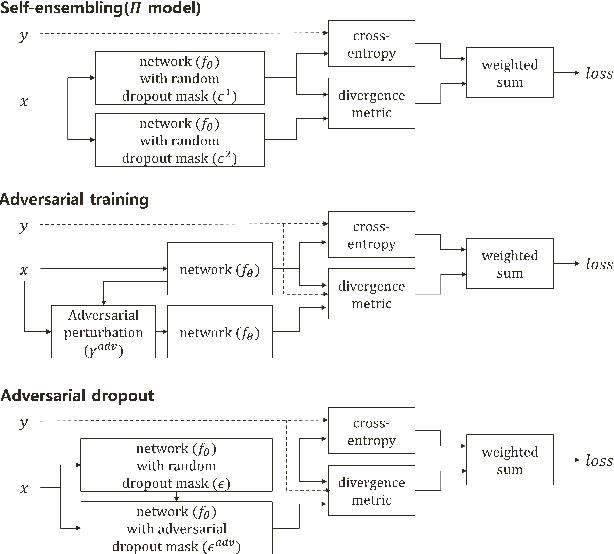
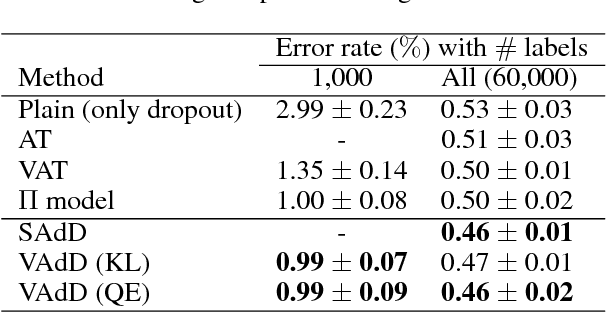
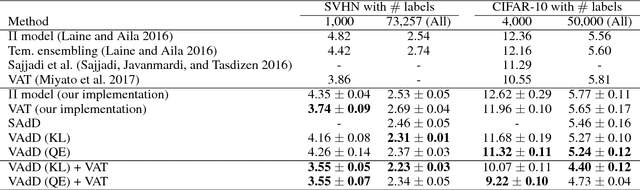

Recently, the training with adversarial examples, which are generated by adding a small but worst-case perturbation on input examples, has been proved to improve generalization performance of neural networks. In contrast to the individually biased inputs to enhance the generality, this paper introduces adversarial dropout, which is a minimal set of dropouts that maximize the divergence between the outputs from the network with the dropouts and the training supervisions. The identified adversarial dropout are used to reconfigure the neural network to train, and we demonstrated that training on the reconfigured sub-network improves the generalization performance of supervised and semi-supervised learning tasks on MNIST and CIFAR-10. We analyzed the trained model to reason the performance improvement, and we found that adversarial dropout increases the sparsity of neural networks more than the standard dropout does.