 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Adversarially Robust Neural Networks without Adversarial Examples
Oct 09, 2022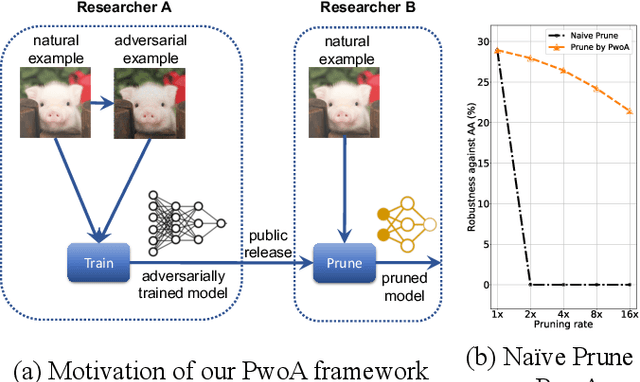
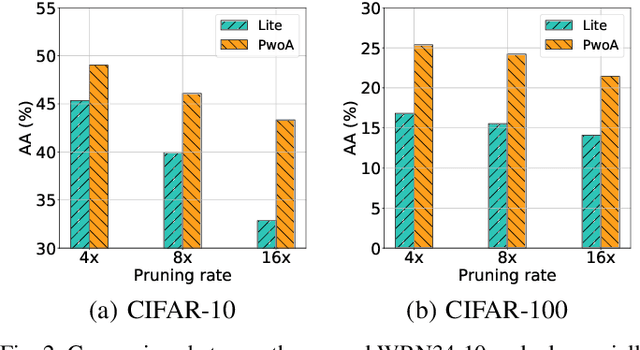
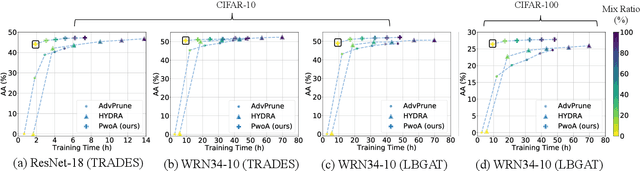
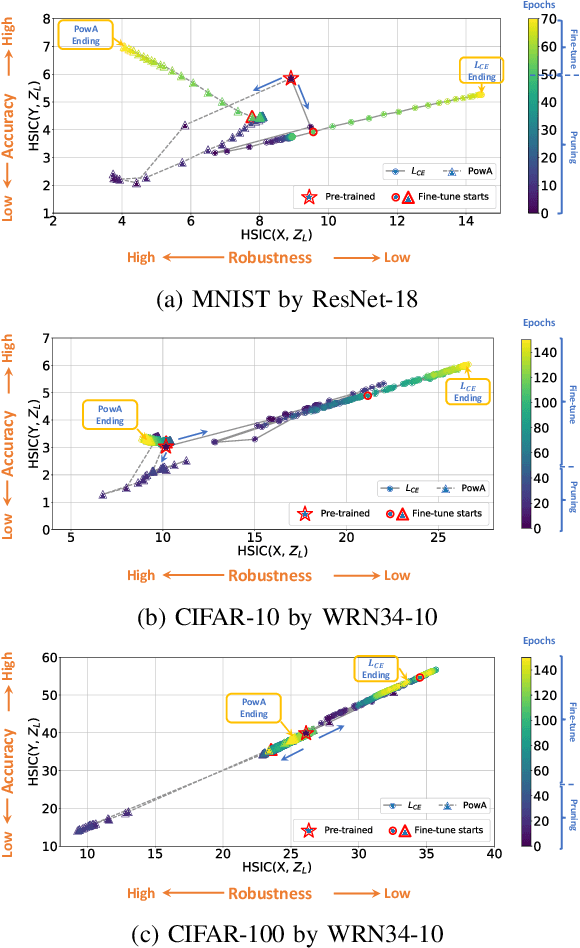
Adversarial pruning compresses models while preserving robustness. Current methods require access to adversarial examples during pruning. This significantly hampers training efficiency. Moreover, as new adversarial attacks and training methods develop at a rapid rate, adversarial pruning methods need to be modified accordingly to keep up. In this work, we propose a novel framework to prune a previously trained robust neural network while maintaining adversarial robustness, without further generating adversarial examples. We leverage concurrent self-distillation and pruning to preserve knowledge in the original model as well as regularizing the pruned model via the Hilbert-Schmidt Information Bottleneck. We comprehensively evaluate our proposed framework and show its superior performance in terms of both adversarial robustness and efficiency when pruning architectures trained on the MNIST, CIFAR-10, and CIFAR-100 datasets against five state-of-the-art attacks. Code is available at https://github.com/neu-spiral/PwoA/.
SparCL: Sparse Continual Learning on the Edge
Sep 20, 2022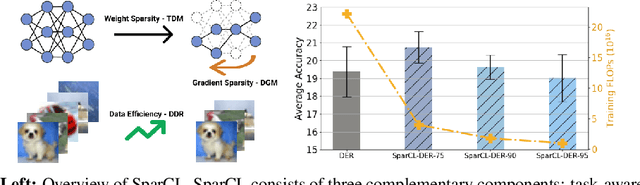
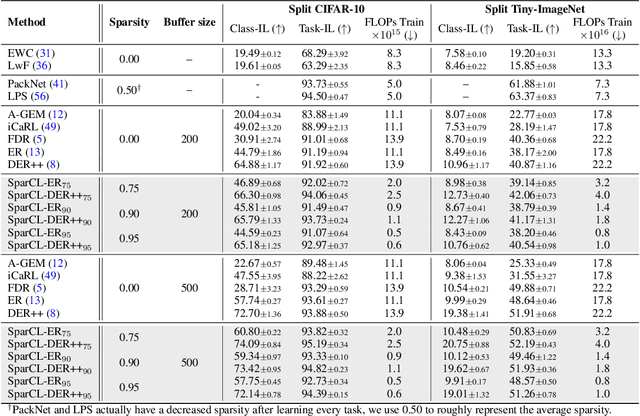
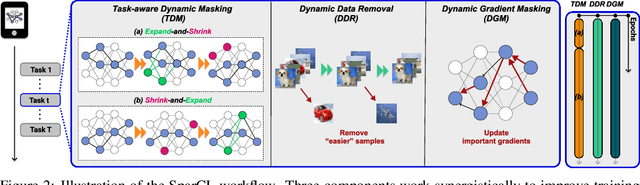
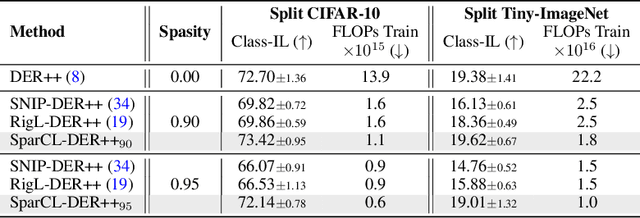
Existing work in continual learning (CL) focuses on mitigating catastrophic forgetting, i.e., model performance deterioration on past tasks when learning a new task. However, the training efficiency of a CL system is under-investigated, which limits the real-world application of CL systems under resource-limited scenarios. In this work, we propose a novel framework called Sparse Continual Learning(SparCL), which is the first study that leverages sparsity to enable cost-effective continual learning on edge devices. SparCL achieves both training acceleration and accuracy preservation through the synergy of three aspects: weight sparsity, data efficiency, and gradient sparsity. Specifically, we propose task-aware dynamic masking (TDM) to learn a sparse network throughout the entire CL process, dynamic data removal (DDR) to remove less informative training data, and dynamic gradient masking (DGM) to sparsify the gradient updates. Each of them not only improves efficiency, but also further mitigates catastrophic forgetting. SparCL consistently improves the training efficiency of existing state-of-the-art (SOTA) CL methods by at most 23X less training FLOPs, and, surprisingly, further improves the SOTA accuracy by at most 1.7%. SparCL also outperforms competitive baselines obtained from adapting SOTA sparse training methods to the CL setting in both efficiency and accuracy. We also evaluate the effectiveness of SparCL on a real mobile phone, further indicating the practical potential of our method.
Differentially Private Regression with Unbounded Covariates
Feb 19, 2022We provide computationally efficient, differentially private algorithms for the classical regression settings of Least Squares Fitting, Binary Regression and Linear Regression with unbounded covariates. Prior to our work, privacy constraints in such regression settings were studied under strong a priori bounds on covariates. We consider the case of Gaussian marginals and extend recent differentially private techniques on mean and covariance estimation (Kamath et al., 2019; Karwa and Vadhan, 2018) to the sub-gaussian regime. We provide a novel technical analysis yielding differentially private algorithms for the above classical regression settings. Through the case of Binary Regression, we capture the fundamental and widely-studied models of logistic regression and linearly-separable SVMs, learning an unbiased estimate of the true regression vector, up to a scaling factor.
AirNN: Neural Networks with Over-the-Air Convolution via Reconfigurable Intelligent Surfaces
Feb 07, 2022



Over-the-air analog computation allows offloading computation to the wireless environment through carefully constructed transmitted signals. In this paper, we design and implement the first-of-its-kind over-the-air convolution and demonstrate it for inference tasks in a convolutional neural network (CNN). We engineer the ambient wireless propagation environment through reconfigurable intelligent surfaces (RIS) to design such an architecture, which we call 'AirNN'. AirNN leverages the physics of wave reflection to represent a digital convolution, an essential part of a CNN architecture, in the analog domain. In contrast to classical communication, where the receiver must react to the channel-induced transformation, generally represented as finite impulse response (FIR) filter, AirNN proactively creates the signal reflections to emulate specific FIR filters through RIS. AirNN involves two steps: first, the weights of the neurons in the CNN are drawn from a finite set of channel impulse responses (CIR) that correspond to realizable FIR filters. Second, each CIR is engineered through RIS, and reflected signals combine at the receiver to determine the output of the convolution. This paper presents a proof-of-concept of AirNN by experimentally demonstrating over-the-air convolutions. We then validate the entire resulting CNN model accuracy via simulations for an example task of modulation classification.
Deep Learning on Multimodal Sensor Data at the Wireless Edge for Vehicular Network
Jan 12, 2022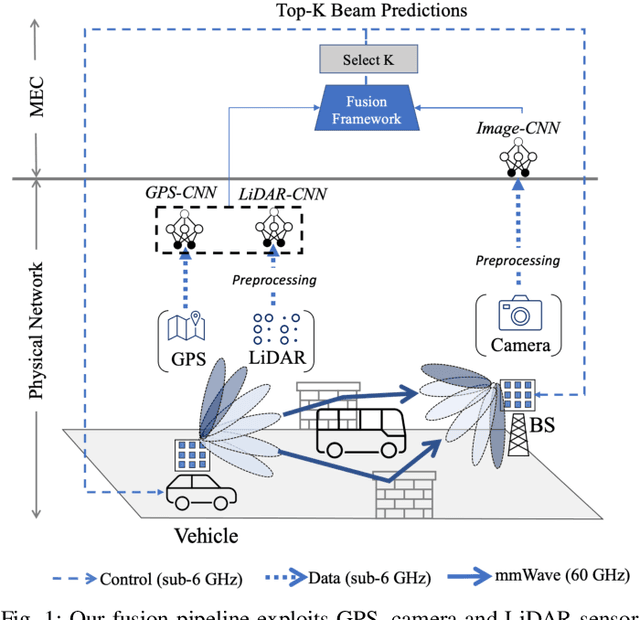
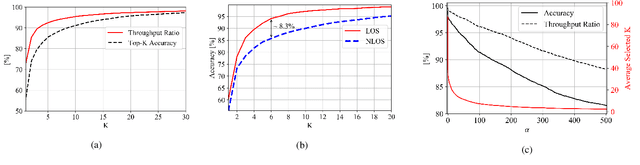
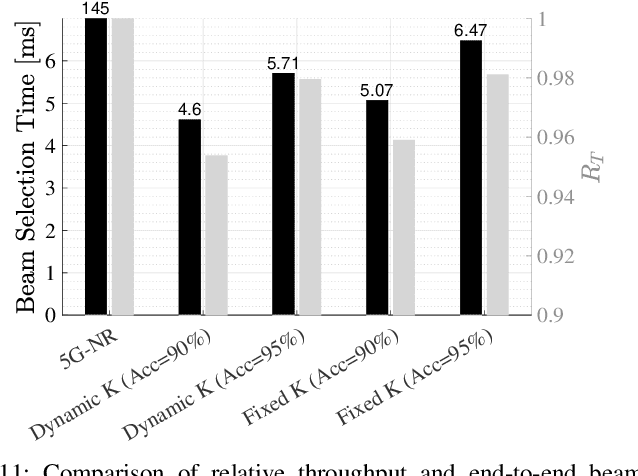
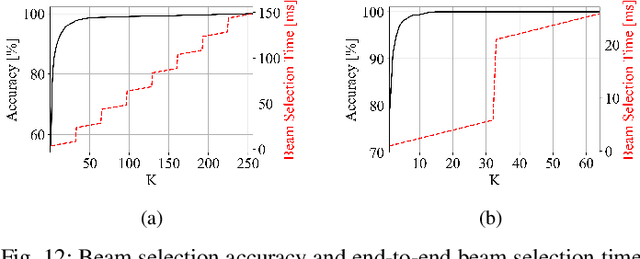
Beam selection for millimeter-wave links in a vehicular scenario is a challenging problem, as an exhaustive search among all candidate beam pairs cannot be assuredly completed within short contact times. We solve this problem via a novel expediting beam selection by leveraging multimodal data collected from sensors like LiDAR, camera images, and GPS. We propose individual modality and distributed fusion-based deep learning (F-DL) architectures that can execute locally as well as at a mobile edge computing center (MEC), with a study on associated tradeoffs. We also formulate and solve an optimization problem that considers practical beam-searching, MEC processing and sensor-to-MEC data delivery latency overheads for determining the output dimensions of the above F-DL architectures. Results from extensive evaluations conducted on publicly available synthetic and home-grown real-world datasets reveal 95% and 96% improvement in beam selection speed over classical RF-only beam sweeping, respectively. F-DL also outperforms the state-of-the-art techniques by 20-22% in predicting top-10 best beam pairs.
Robust Regression via Model Based Methods
Jun 29, 2021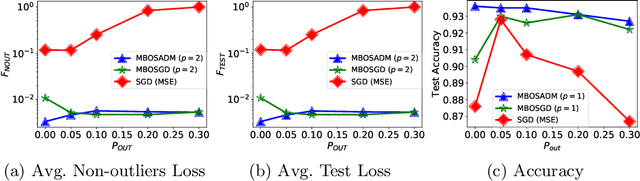
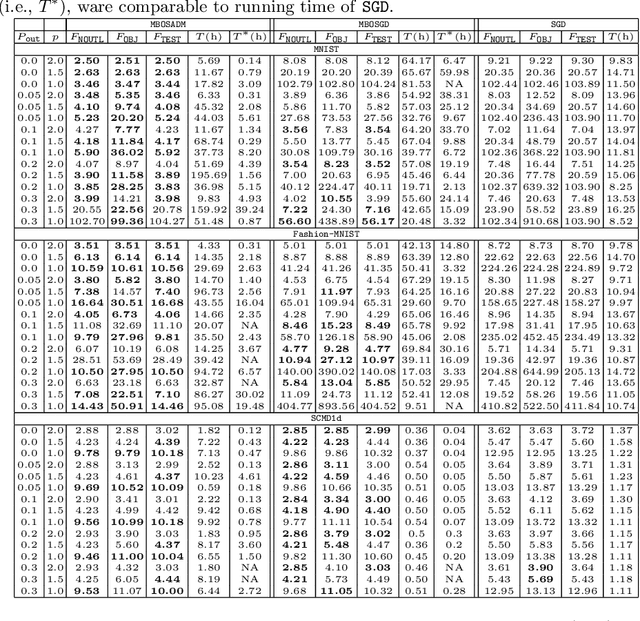
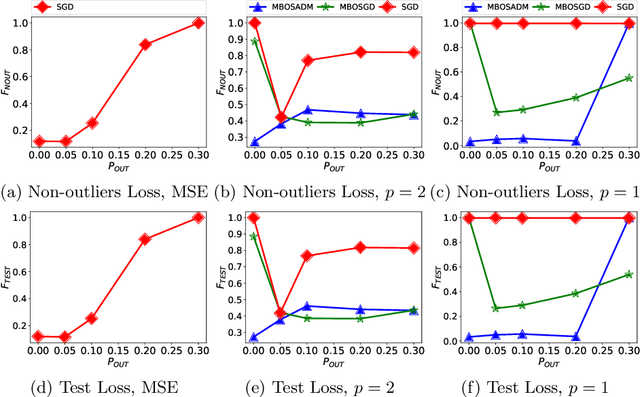
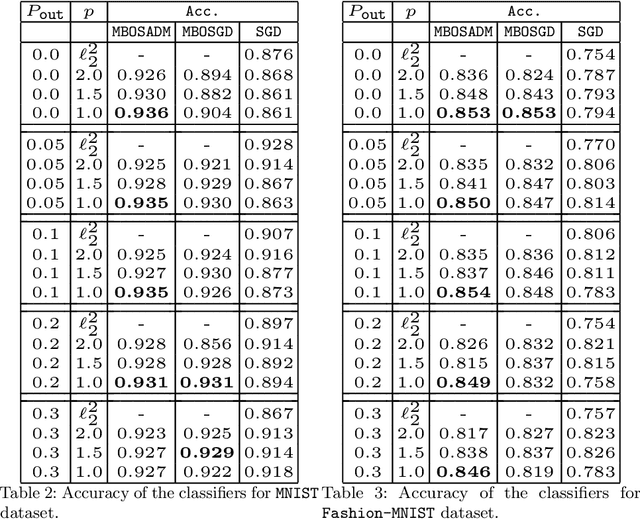
The mean squared error loss is widely used in many applications, including auto-encoders, multi-target regression, and matrix factorization, to name a few. Despite computational advantages due to its differentiability, it is not robust to outliers. In contrast, l_p norms are known to be robust, but cannot be optimized via, e.g., stochastic gradient descent, as they are non-differentiable. We propose an algorithm inspired by so-called model-based optimization (MBO) [35, 36], which replaces a non-convex objective with a convex model function and alternates between optimizing the model function and updating the solution. We apply this to robust regression, proposing SADM, a stochastic variant of the Online Alternating Direction Method of Multipliers (OADM) [50] to solve the inner optimization in MBO. We show that SADM converges with the rate O(log T/T). Finally, we demonstrate experimentally (a) the robustness of l_p norms to outliers and (b) the efficiency of our proposed model-based algorithms in comparison with gradient methods on autoencoders and multi-target regression.
Revisiting Hilbert-Schmidt Information Bottleneck for Adversarial Robustness
Jun 04, 2021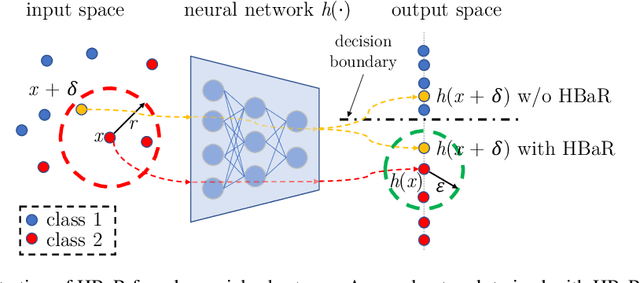
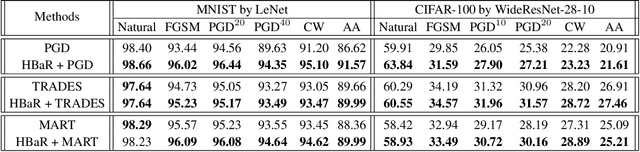
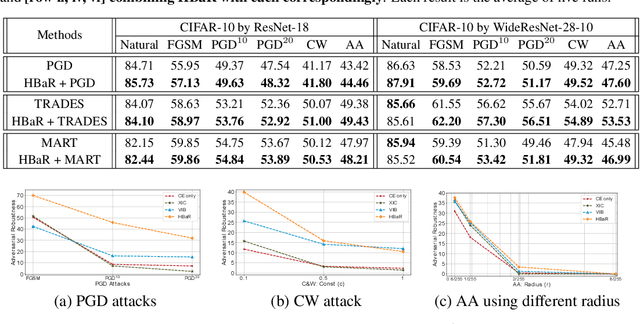
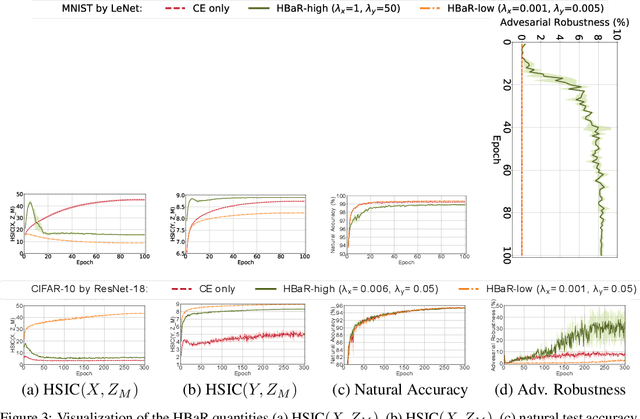
We investigate the HSIC (Hilbert-Schmidt independence criterion) bottleneck as a regularizer for learning an adversarially robust deep neural network classifier. We show that the HSIC bottleneck enhances robustness to adversarial attacks both theoretically and experimentally. Our experiments on multiple benchmark datasets and architectures demonstrate that incorporating an HSIC bottleneck regularizer attains competitive natural accuracy and improves adversarial robustness, both with and without adversarial examples during training.
On the Sample Complexity of Rank Regression from Pairwise Comparisons
May 04, 2021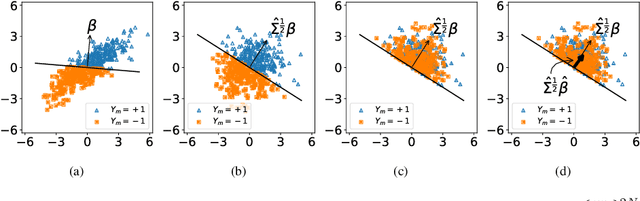

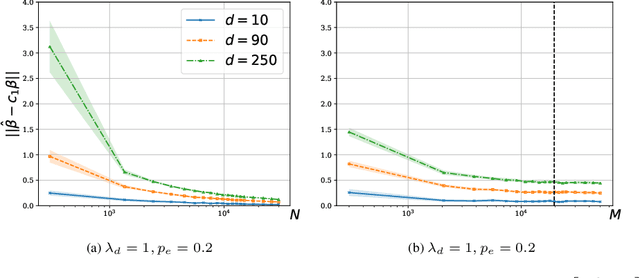
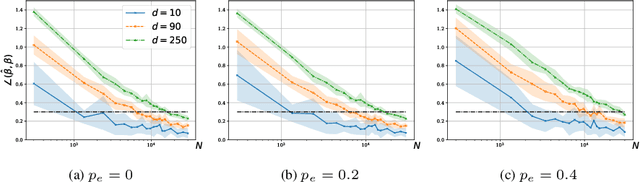
We consider a rank regression setting, in which a dataset of $N$ samples with features in $\mathbb{R}^d$ is ranked by an oracle via $M$ pairwise comparisons. Specifically, there exists a latent total ordering of the samples; when presented with a pair of samples, a noisy oracle identifies the one ranked higher with respect to the underlying total ordering. A learner observes a dataset of such comparisons and wishes to regress sample ranks from their features. We show that to learn the model parameters with $\epsilon > 0$ accuracy, it suffices to conduct $M \in \Omega(dN\log^3 N/\epsilon^2)$ comparisons uniformly at random when $N$ is $\Omega(d/\epsilon^2)$.
Machine Learning on Camera Images for Fast mmWave Beamforming
Feb 15, 2021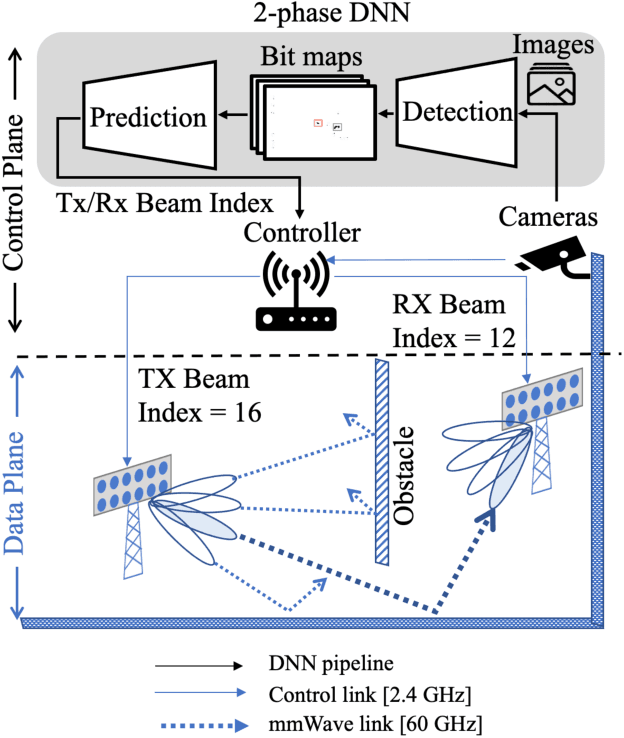
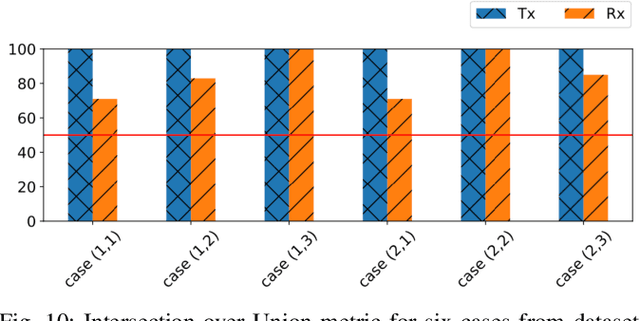
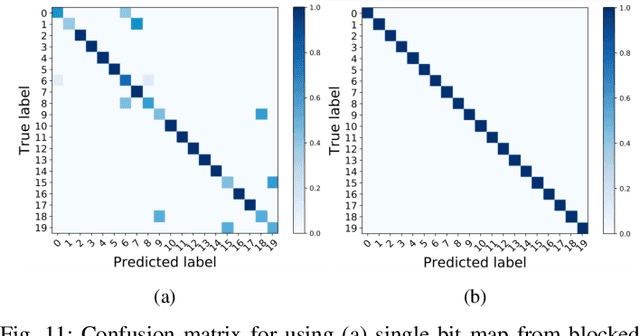
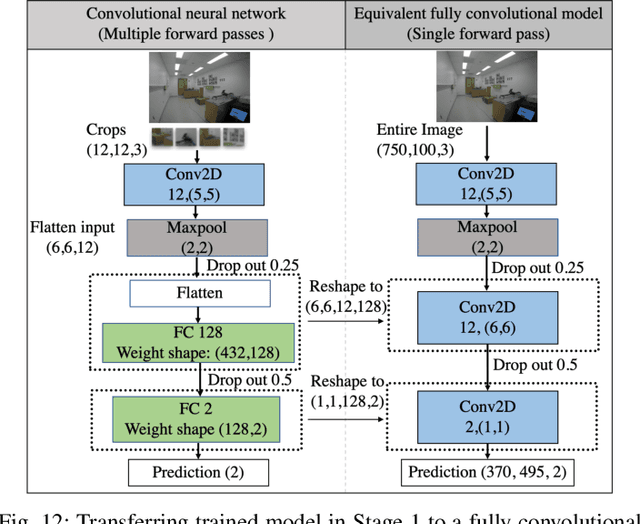
Perfect alignment in chosen beam sectors at both transmit- and receive-nodes is required for beamforming in mmWave bands. Current 802.11ad WiFi and emerging 5G cellular standards spend up to several milliseconds exploring different sector combinations to identify the beam pair with the highest SNR. In this paper, we propose a machine learning (ML) approach with two sequential convolutional neural networks (CNN) that uses out-of-band information, in the form of camera images, to (i) rapidly identify the locations of the transmitter and receiver nodes, and then (ii) return the optimal beam pair. We experimentally validate this intriguing concept for indoor settings using the NI 60GHz mmwave transceiver. Our results reveal that our ML approach reduces beamforming related exploration time by 93% under different ambient lighting conditions, with an error of less than 1% compared to the time-intensive deterministic method defined by the current standards.
No-Regret Caching via Online Mirror Descent
Feb 08, 2021
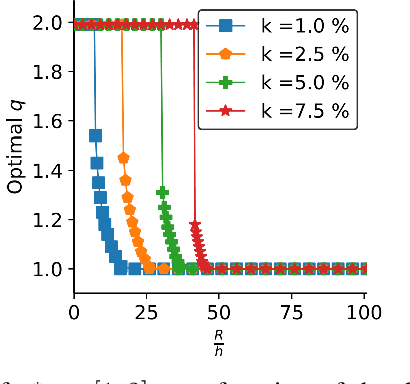
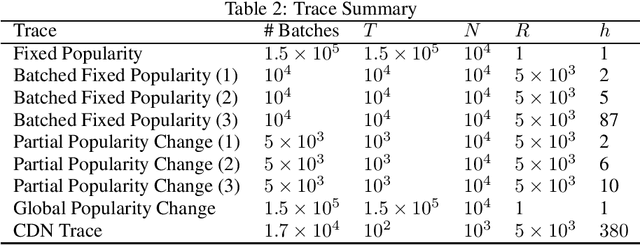
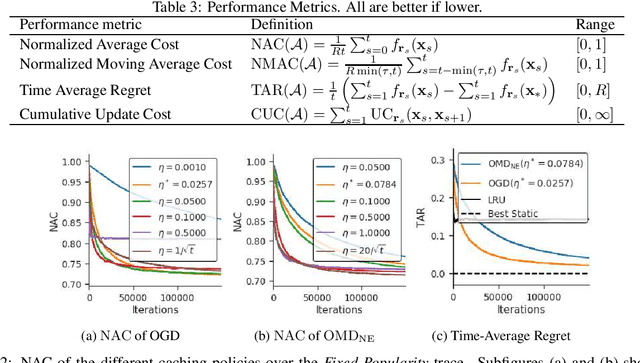
We study an online caching problem in which requests can be served by a local cache to avoid retrieval costs from a remote server. The cache can update its state after a batch of requests and store an arbitrarily small fraction of each content. We study no-regret algorithms based on Online Mirror Descent (OMD) strategies. We show that the optimal OMD strategy depends on the request diversity present in a batch. We also prove that, when the cache must store the entire content, rather than a fraction, OMD strategies can be coupled with a randomized rounding scheme that preserves regret guarantees.