 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Fairness for Neural Network Models using Formal Verification
Dec 16, 2022



Machine learning models are increasingly deployed for critical decision-making tasks, making it important to verify that they do not contain gender or racial biases picked up from training data. Typical approaches to achieve fairness revolve around efforts to clean or curate training data, with post-hoc statistical evaluation of the fairness of the model on evaluation data. In contrast, we propose techniques to \emph{prove} fairness using recently developed formal methods that verify properties of neural network models.Beyond the strength of guarantee implied by a formal proof, our methods have the advantage that we do not need explicit training or evaluation data (which is often proprietary) in order to analyze a given trained model. In experiments on two familiar datasets in the fairness literature (COMPAS and ADULTS), we show that through proper training, we can reduce unfairness by an average of 65.4\% at a cost of less than 1\% in AUC score.
Hierarchies over Vector Space: Orienting Word and Graph Embeddings
Nov 02, 2022



Word and graph embeddings are widely used in deep learning applications. We present a data structure that captures inherent hierarchical properties from an unordered flat embedding space, particularly a sense of direction between pairs of entities. Inspired by the notion of \textit{distributional generality}, our algorithm constructs an arborescence (a directed rooted tree) by inserting nodes in descending order of entity power (e.g., word frequency), pointing each entity to the closest more powerful node as its parent. We evaluate the performance of the resulting tree structures on three tasks: hypernym relation discovery, least-common-ancestor (LCA) discovery among words, and Wikipedia page link recovery. We achieve average 8.98\% and 2.70\% for hypernym and LCA discovery across five languages and 62.76\% accuracy on directed Wiki-page link recovery, with both substantially above baselines. Finally, we investigate the effect of insertion order, the power/similarity trade-off and various power sources to optimize parent selection.
Chapter Captor: Text Segmentation in Novels
Nov 09, 2020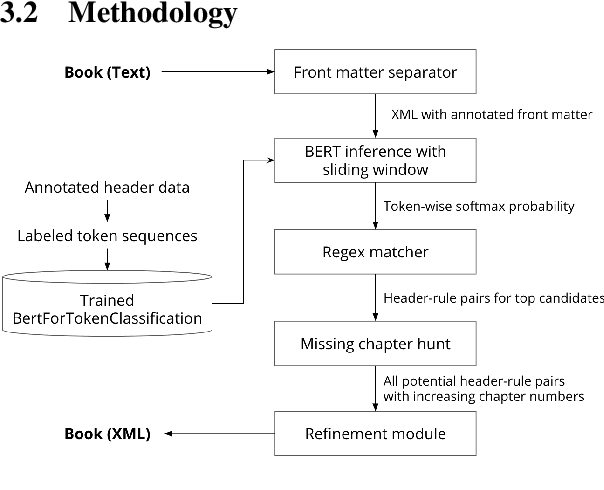
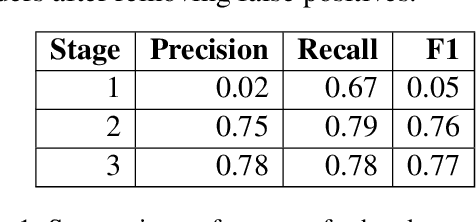
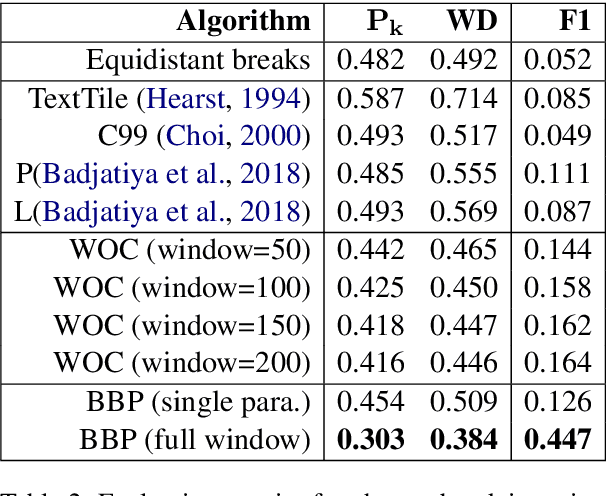
Books are typically segmented into chapters and sections, representing coherent subnarratives and topics. We investigate the task of predicting chapter boundaries, as a proxy for the general task of segmenting long texts. We build a Project Gutenberg chapter segmentation data set of 9,126 English novels, using a hybrid approach combining neural inference and rule matching to recognize chapter title headers in books, achieving an F1-score of 0.77 on this task. Using this annotated data as ground truth after removing structural cues, we present cut-based and neural methods for chapter segmentation, achieving an F1-score of 0.453 on the challenging task of exact break prediction over book-length documents. Finally, we reveal interesting historical trends in the chapter structure of novels.
What time is it? Temporal Analysis of Novels
Nov 09, 2020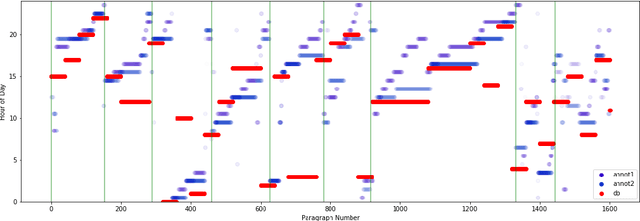
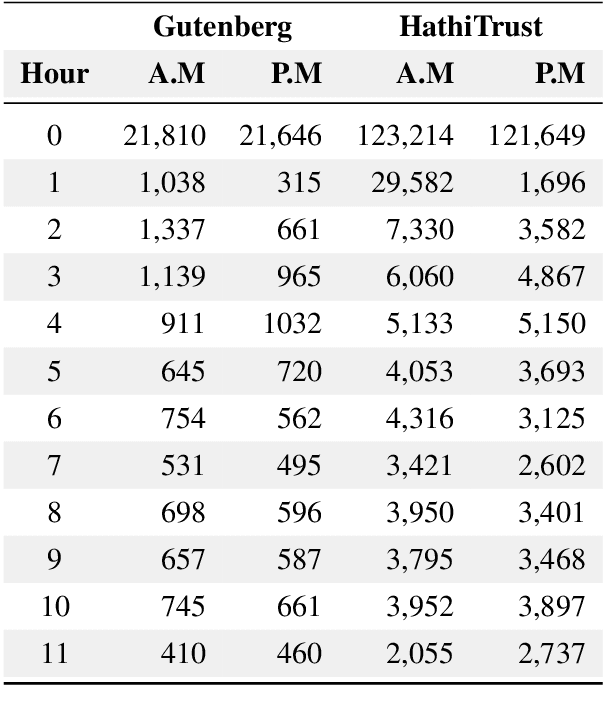
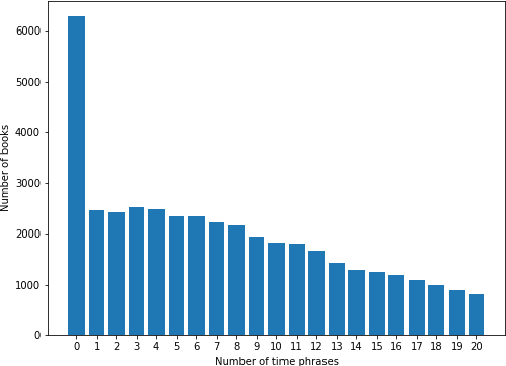
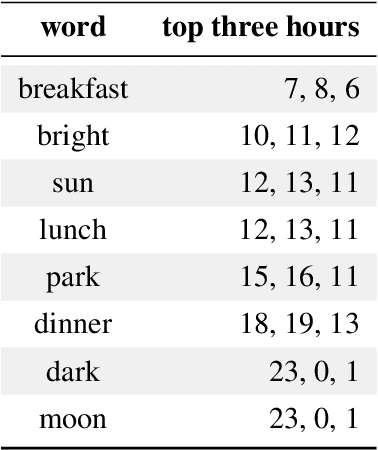
Recognizing the flow of time in a story is a crucial aspect of understanding it. Prior work related to time has primarily focused on identifying temporal expressions or relative sequencing of events, but here we propose computationally annotating each line of a book with wall clock times, even in the absence of explicit time-descriptive phrases. To do so, we construct a data set of hourly time phrases from 52,183 fictional books. We then construct a time-of-day classification model that achieves an average error of 2.27 hours. Furthermore, we show that by analyzing a book in whole using dynamic programming of breakpoints, we can roughly partition a book into segments that each correspond to a particular time-of-day. This approach improves upon baselines by over two hours. Finally, we apply our model to a corpus of literature categorized by different periods in history, to show interesting trends of hourly activity throughout the past. Among several observations we find that the fraction of events taking place past 10 P.M jumps past 1880 - coincident with the advent of the electric light bulb and city lights.
Online AUC Optimization for Sparse High-Dimensional Datasets
Sep 23, 2020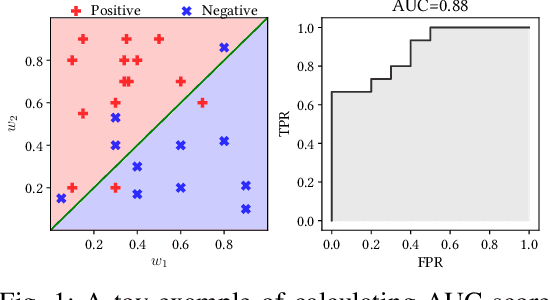
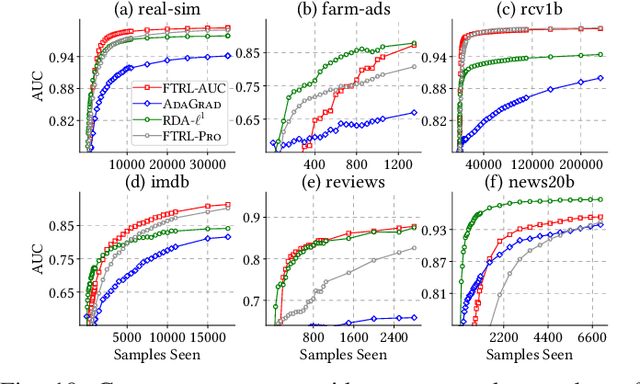
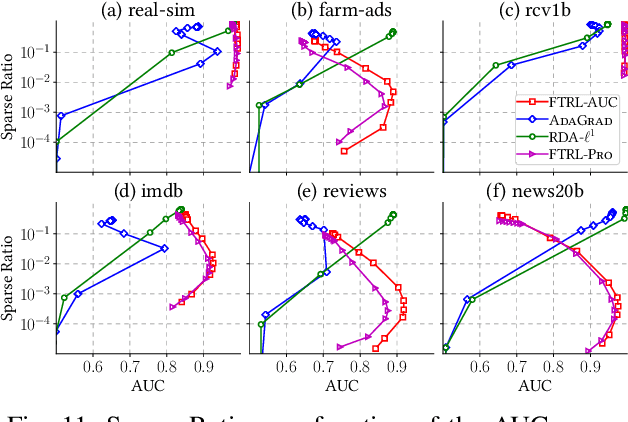
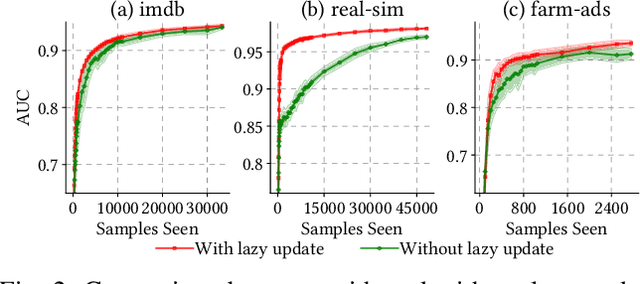
The Area Under the ROC Curve (AUC) is a widely used performance measure for imbalanced classification arising from many application domains where high-dimensional sparse data is abundant. In such cases, each $d$ dimensional sample has only $k$ non-zero features with $k \ll d$, and data arrives sequentially in a streaming form. Current online AUC optimization algorithms have high per-iteration cost $\mathcal{O}(d)$ and usually produce non-sparse solutions in general, and hence are not suitable for handling the data challenge mentioned above. In this paper, we aim to directly optimize the AUC score for high-dimensional sparse datasets under online learning setting and propose a new algorithm, \textsc{FTRL-AUC}. Our proposed algorithm can process data in an online fashion with a much cheaper per-iteration cost $\mathcal{O}(k)$, making it amenable for high-dimensional sparse streaming data analysis. Our new algorithmic design critically depends on a novel reformulation of the U-statistics AUC objective function as the empirical saddle point reformulation, and the innovative introduction of the "lazy update" rule so that the per-iteration complexity is dramatically reduced from $\mathcal{O}(d)$ to $\mathcal{O}(k)$. Furthermore, \textsc{FTRL-AUC} can inherently capture sparsity more effectively by applying a generalized Follow-The-Regularized-Leader (FTRL) framework. Experiments on real-world datasets demonstrate that \textsc{FTRL-AUC} significantly improves both run time and model sparsity while achieving competitive AUC scores compared with the state-of-the-art methods. Comparison with the online learning method for logistic loss demonstrates that \textsc{FTRL-AUC} achieves higher AUC scores especially when datasets are imbalanced.
The Trumpiest Trump? Identifying a Subject's Most Characteristic Tweets
Sep 09, 2019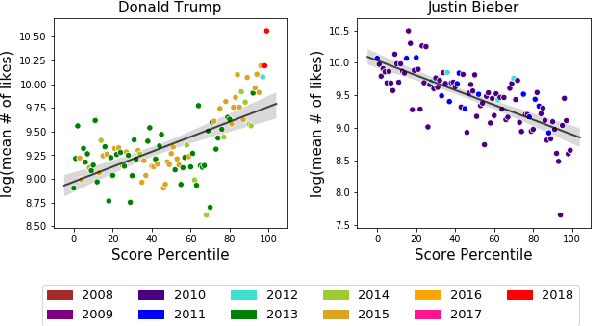
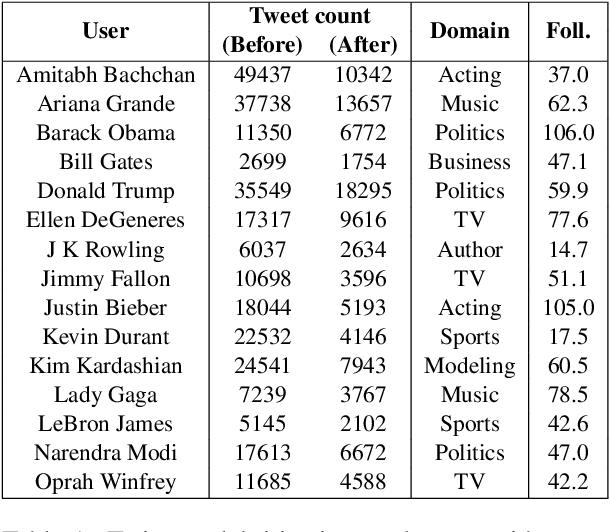
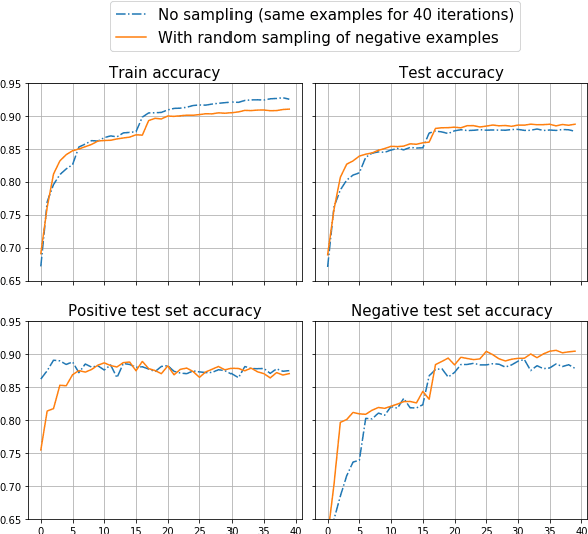
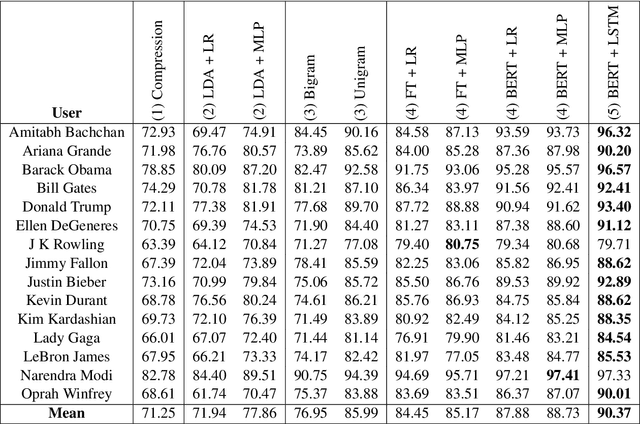
The sequence of documents produced by any given author varies in style and content, but some documents are more typical or representative of the source than others. We quantify the extent to which a given short text is characteristic of a specific person, using a dataset of tweets from fifteen celebrities. Such analysis is useful for generating excerpts of high-volume Twitter profiles, and understanding how representativeness relates to tweet popularity. We first consider the related task of binary author detection (is x the author of text T?), and report a test accuracy of 90.37% for the best of five approaches to this problem. We then use these models to compute characterization scores among all of an author's texts. A user study shows human evaluators agree with our characterization model for all 15 celebrities in our dataset, each with p-value < 0.05. We use these classifiers to show surprisingly strong correlations between characterization scores and the popularity of the associated texts. Indeed, we demonstrate a statistically significant correlation between this score and tweet popularity (likes/replies/retweets) for 13 of the 15 celebrities in our study.
Fast and Accurate Network Embeddings via Very Sparse Random Projection
Aug 30, 2019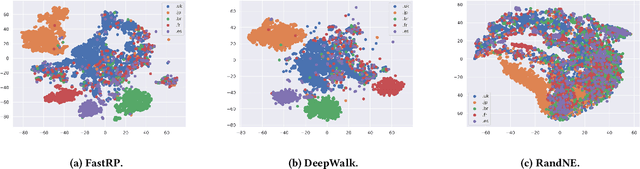

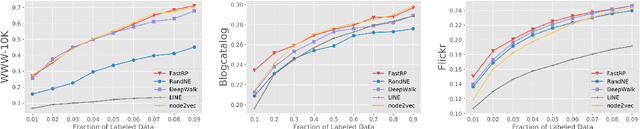
We present FastRP, a scalable and performant algorithm for learning distributed node representations in a graph. FastRP is over 4,000 times faster than state-of-the-art methods such as DeepWalk and node2vec, while achieving comparable or even better performance as evaluated on several real-world networks on various downstream tasks. We observe that most network embedding methods consist of two components: construct a node similarity matrix and then apply dimension reduction techniques to this matrix. We show that the success of these methods should be attributed to the proper construction of this similarity matrix, rather than the dimension reduction method employed. FastRP is proposed as a scalable algorithm for network embeddings. Two key features of FastRP are: 1) it explicitly constructs a node similarity matrix that captures transitive relationships in a graph and normalizes matrix entries based on node degrees; 2) it utilizes very sparse random projection, which is a scalable optimization-free method for dimension reduction. An extra benefit from combining these two design choices is that it allows the iterative computation of node embeddings so that the similarity matrix need not be explicitly constructed, which further speeds up FastRP. FastRP is also advantageous for its ease of implementation, parallelization and hyperparameter tuning. The source code is available at https://github.com/GTmac/FastRP.
The Secret Lives of Names? Name Embeddings from Social Media
May 12, 2019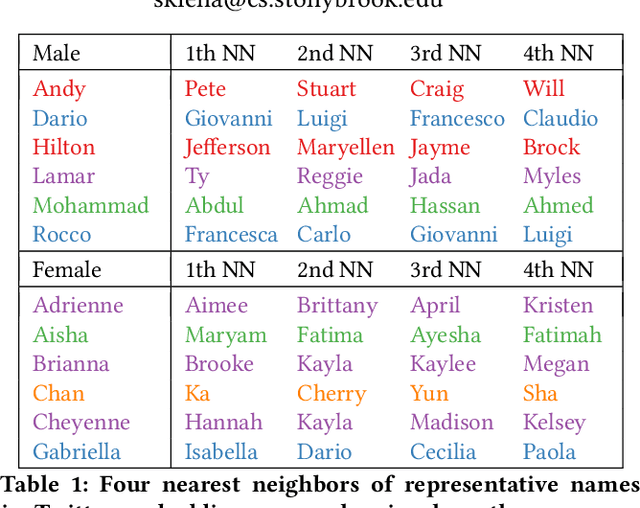
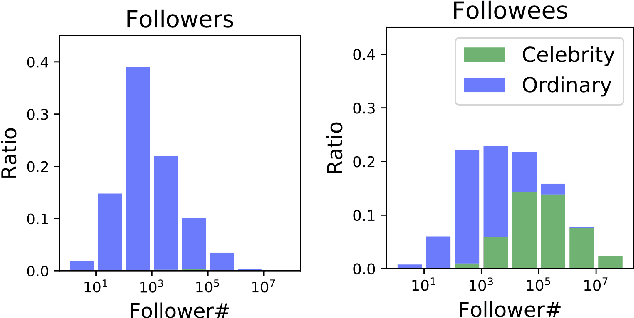
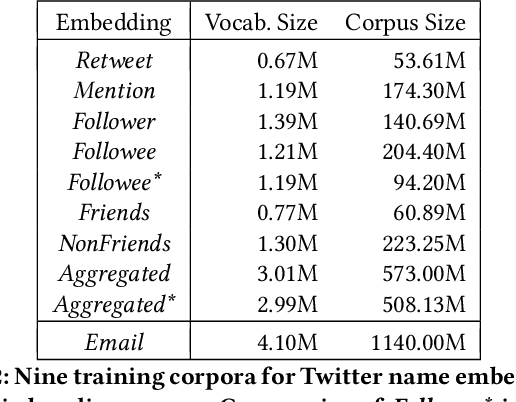
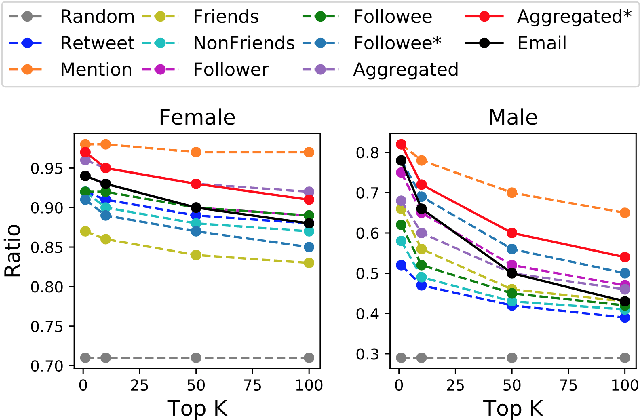
Your name tells a lot about you: your gender, ethnicity and so on. It has been shown that name embeddings are more effective in representing names than traditional substring features. However, our previous name embedding model is trained on private email data and are not publicly accessible. In this paper, we explore learning name embeddings from public Twitter data. We argue that Twitter embeddings have two key advantages: \textit{(i)} they can and will be publicly released to support research community. \textit{(ii)} even with a smaller training corpus, Twitter embeddings achieve similar performances on multiple tasks comparing to email embeddings. As a test case to show the power of name embeddings, we investigate the modeling of lifespans. We find it interesting that adding name embeddings can further improve the performances of models using demographic features, which are traditionally used for lifespan modeling. Through residual analysis, we observe that fine-grained groups (potentially reflecting socioeconomic status) are the latent contributing factors encoded in name embeddings. These were previously hidden to demographic models, and may help to enhance the predictive power of a wide class of research studies.
Multi-view Models for Political Ideology Detection of News Articles
Sep 10, 2018
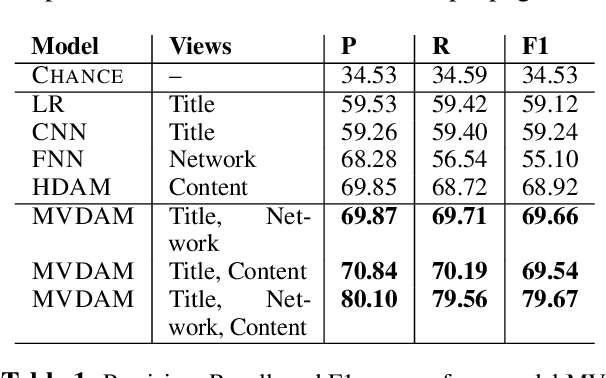
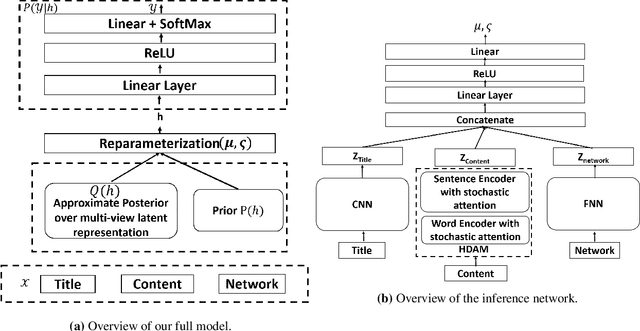

A news article's title, content and link structure often reveal its political ideology. However, most existing works on automatic political ideology detection only leverage textual cues. Drawing inspiration from recent advances in neural inference, we propose a novel attention based multi-view model to leverage cues from all of the above views to identify the ideology evinced by a news article. Our model draws on advances in representation learning in natural language processing and network science to capture cues from both textual content and the network structure of news articles. We empirically evaluate our model against a battery of baselines and show that our model outperforms state of the art by 10 percentage points F1 score.
Learning to Represent Bilingual Dictionaries
Aug 31, 2018
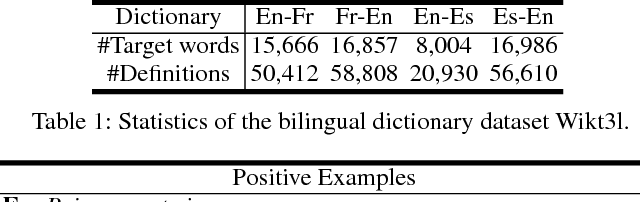
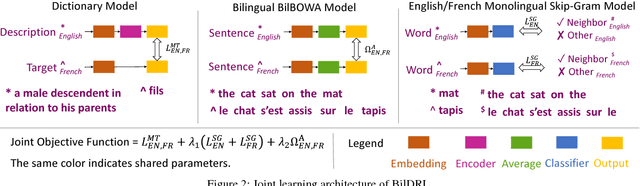
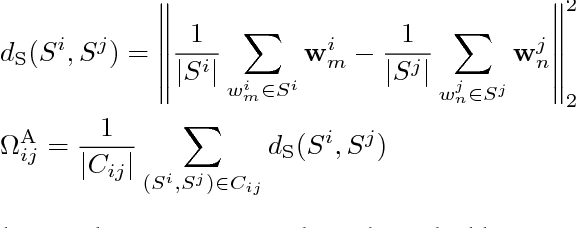
Bilingual word embeddings have been widely used to capture the similarity of lexical semantics in different human languages. However, many applications, such as cross-lingual semantic search and question answering, can be largely benefited from the cross-lingual correspondence between sentences and lexicons. To bridge this gap, we propose a neural embedding model that leverages bilingual dictionaries. The proposed model is trained to map the literal word definitions to the cross-lingual target words, for which we explore with different sentence encoding techniques. To enhance the learning process on limited resources, our model adopts several critical learning strategies, including multi-task learning on different bridges of languages, and joint learning of the dictionary model with a bilingual word embedding model. Experimental evaluation focuses on two applications. The results of the cross-lingual reverse dictionary retrieval task show our model's promising ability of comprehending bilingual concepts based on descriptions, and highlight the effectiveness of proposed learning strategies in improving performance. Meanwhile, our model effectively addresses the bilingual paraphrase identification problem and significantly outperforms previous approaches.